 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFold-CP: A Context Parallelism Framework for Biomolecular Modeling
Mar 16, 2026Understanding cellular machinery requires atomic-scale reconstruction of large biomolecular assemblies. However, predicting the structures of these systems has been constrained by hardware memory requirements of models like AlphaFold 3, imposing a practical ceiling of a few thousand residues that can be processed on a single GPU. Here we present NVIDIA BioNeMo Fold-CP, a context parallelism framework that overcomes this barrier by distributing the inference and training pipelines of co-folding models across multiple GPUs. We use the Boltz models as open source reference architectures and implement custom multidimensional primitives that efficiently parallelize both the dense triangular updates and the irregular, data-dependent pattern of window-batched local attention. Our approach achieves efficient memory scaling; for an N-token input distributed across P GPUs, per-device memory scales as $O(N^2/P)$, enabling the structure prediction of assemblies exceeding 30,000 residues on 64 NVIDIA B300 GPUs. We demonstrate the scientific utility of this approach through successful developer use cases: Fold-CP enabled the scoring of over 90% of Comprehensive Resource of Mammalian protein complexes (CORUM) database, as well as folding of disease-relevant PI4KA lipid kinase complex bound to an intrinsically disordered region without cropping. By providing a scalable pathway for modeling massive systems with full global context, Fold-CP represents a significant step toward the realization of a virtual cell.
TCJA-SNN: Temporal-Channel Joint Attention for Spiking Neural Networks
Jun 21, 2022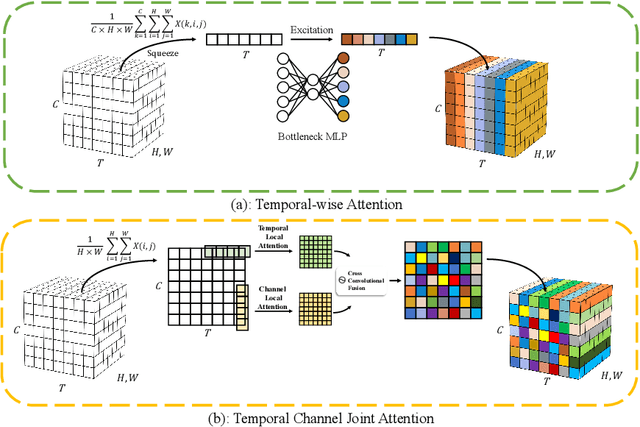
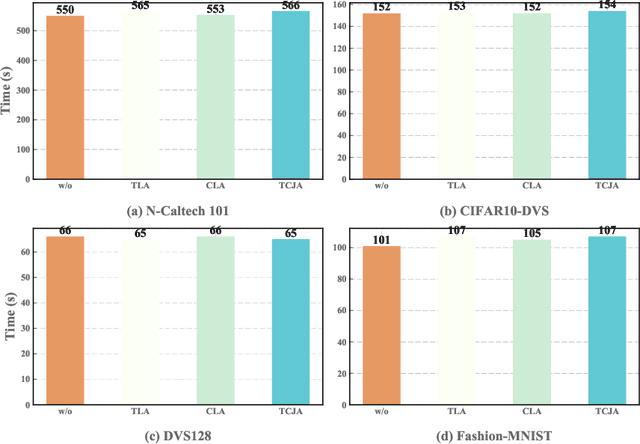
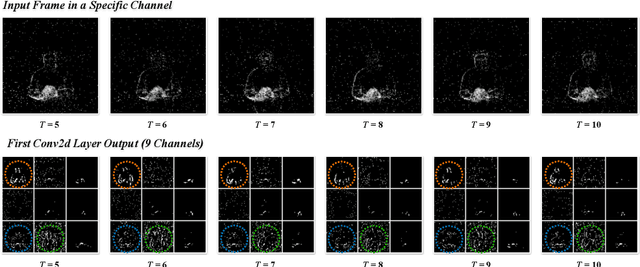

Spiking Neural Networks (SNNs) is a practical approach toward more data-efficient deep learning by simulating neurons leverage on temporal information. In this paper, we propose the Temporal-Channel Joint Attention (TCJA) architectural unit, an efficient SNN technique that depends on attention mechanisms, by effectively enforcing the relevance of spike sequence along both spatial and temporal dimensions. Our essential technical contribution lies on: 1) compressing the spike stream into an average matrix by employing the squeeze operation, then using two local attention mechanisms with an efficient 1-D convolution to establish temporal-wise and channel-wise relations for feature extraction in a flexible fashion. 2) utilizing the Cross Convolutional Fusion (CCF) layer for modeling inter-dependencies between temporal and channel scope, which breaks the independence of the two dimensions and realizes the interaction between features. By virtue of jointly exploring and recalibrating data stream, our method outperforms the state-of-the-art (SOTA) by up to 15.7% in terms of top-1 classification accuracy on all tested mainstream static and neuromorphic datasets, including Fashion-MNIST, CIFAR10-DVS, N-Caltech 101, and DVS128 Gesture.