 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-Spectrogram Segmentation for Environmental Sound Classification via Convolutional Recurrent Neural Network and Score Level Fusion
Aug 16, 2019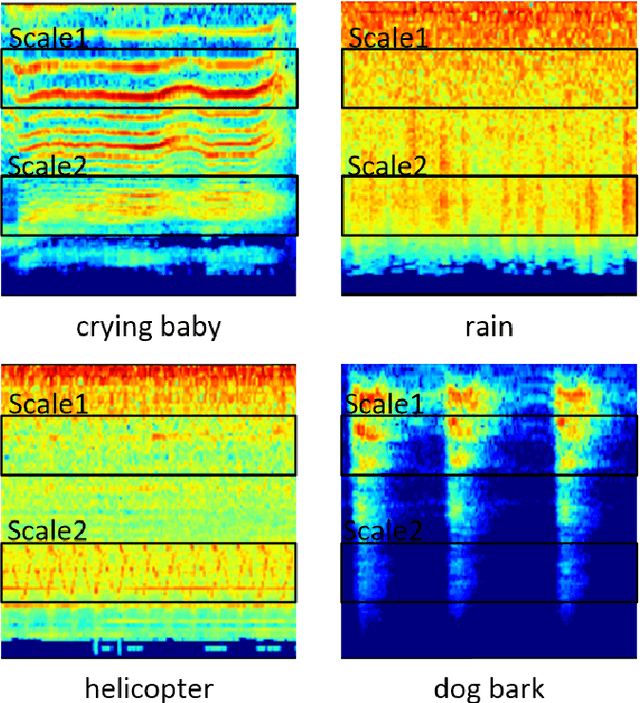
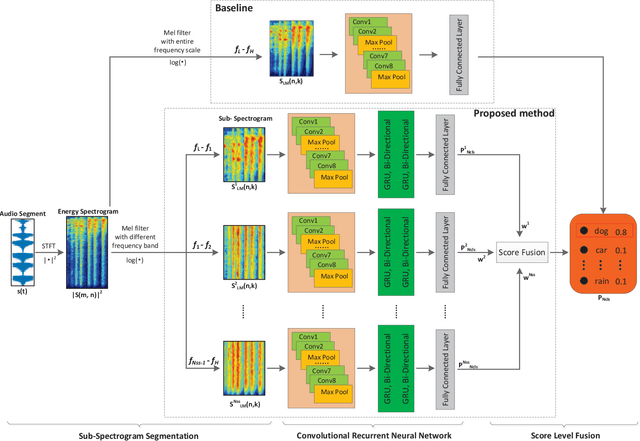
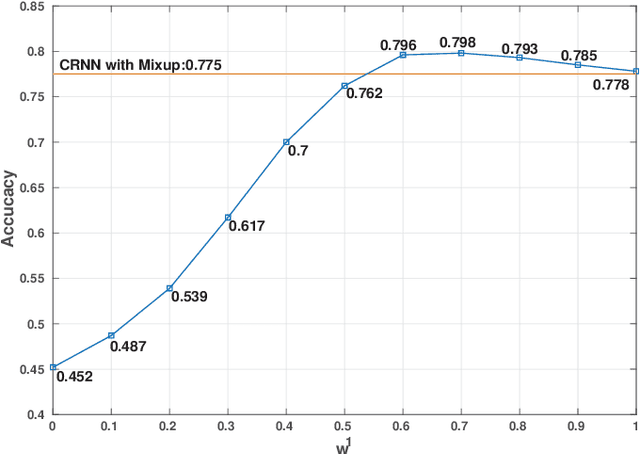

Environmental Sound Classification (ESC) is an important and challenging problem, and feature representation is a critical and even decisive factor in ESC. Feature representation ability directly affects the accuracy of sound classification. Therefore, the ESC performance is heavily dependent on the effectiveness of representative features extracted from the environmental sounds. In this paper, we propose a subspectrogram segmentation based ESC classification framework. In addition, we adopt the proposed Convolutional Recurrent Neural Network (CRNN) and score level fusion to jointly improve the classification accuracy. Extensive truncation schemes are evaluated to find the optimal number and the corresponding band ranges of sub-spectrograms. Based on the numerical experiments, the proposed framework can achieve 81.9% ESC classification accuracy on the public dataset ESC-50, which provides 9.1% accuracy improvement over traditional baseline schemes.
Attention based Convolutional Recurrent Neural Network for Environmental Sound Classification
Jul 04, 2019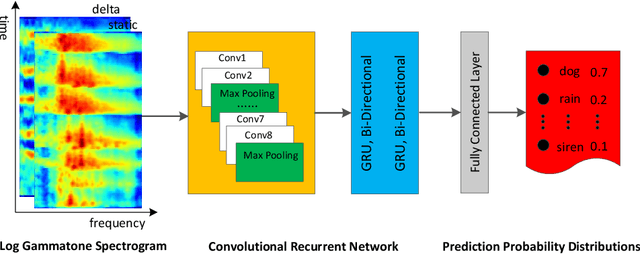
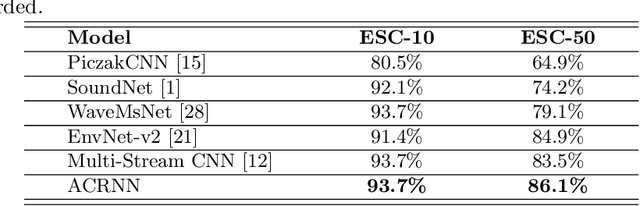
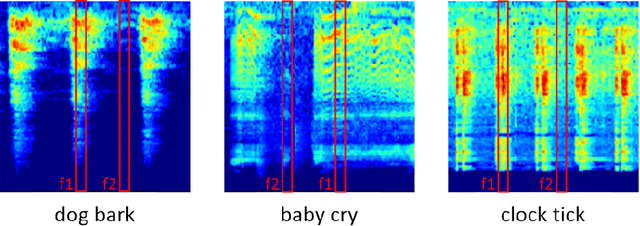

Environmental sound classification (ESC) is a challenging problem due to the complexity of sounds. The ESC performance is heavily dependent on the effectiveness of representative features extracted from the environmental sounds. However, ESC often suffers from the semantically irrelevant frames and silent frames. In order to deal with this, we employ a frame-level attention model to focus on the semantically relevant frames and salient frames. Specifically, we first propose an convolutional recurrent neural network to learn spectro-temporal features and temporal correlations. Then, we extend our convolutional RNN model with a frame-level attention mechanism to learn discriminative feature representations for ESC. Experiments were conducted on ESC-50 and ESC-10 datasets. Experimental results demonstrated the effectiveness of the proposed method and achieved the state-of-the-art performance in terms of classification accuracy.