 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnt Colony Optimization for Mining Gradual Patterns
Aug 31, 2022Gradual pattern extraction is a field in (KDD) Knowledge Discovery in Databases that maps correlations between attributes of a data set as gradual dependencies. A gradual dependency may take a form of "the more Attribute K , the less Attribute L". In this paper, we propose an ant colony optimization technique that uses a probabilistic approach to learn and extract frequent gradual patterns. Through computational experiments on real-world data sets, we compared the performance of our ant-based algorithm to an existing gradual item set extraction algorithm and we found out that our algorithm outperforms the later especially when dealing with large data sets.
* 35 pages, journal article
Neuro-symbolic computing with spiking neural networks
Aug 04, 2022
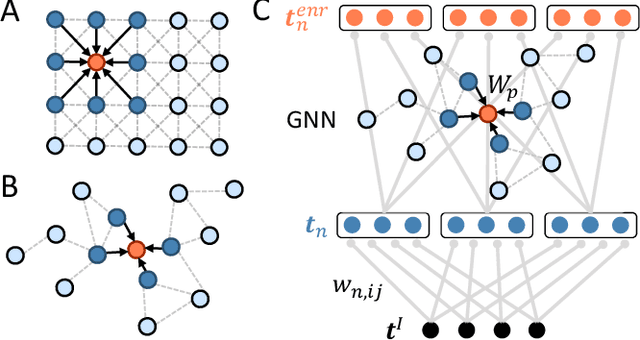
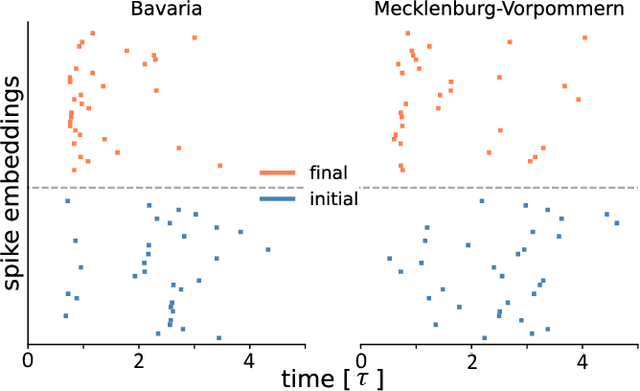
Knowledge graphs are an expressive and widely used data structure due to their ability to integrate data from different domains in a sensible and machine-readable way. Thus, they can be used to model a variety of systems such as molecules and social networks. However, it still remains an open question how symbolic reasoning could be realized in spiking systems and, therefore, how spiking neural networks could be applied to such graph data. Here, we extend previous work on spike-based graph algorithms by demonstrating how symbolic and multi-relational information can be encoded using spiking neurons, allowing reasoning over symbolic structures like knowledge graphs with spiking neural networks. The introduced framework is enabled by combining the graph embedding paradigm and the recent progress in training spiking neural networks using error backpropagation. The presented methods are applicable to a variety of spiking neuron models and can be trained end-to-end in combination with other differentiable network architectures, which we demonstrate by implementing a spiking relational graph neural network.
User-Interactive Offline Reinforcement Learning
May 21, 2022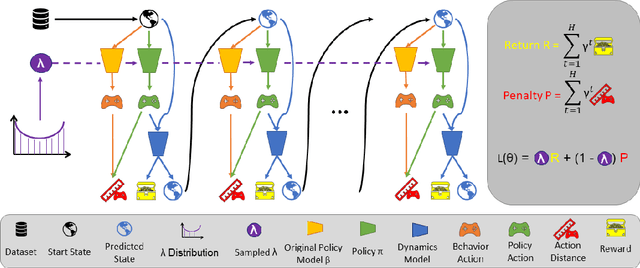
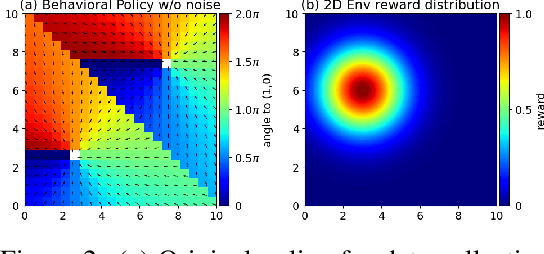

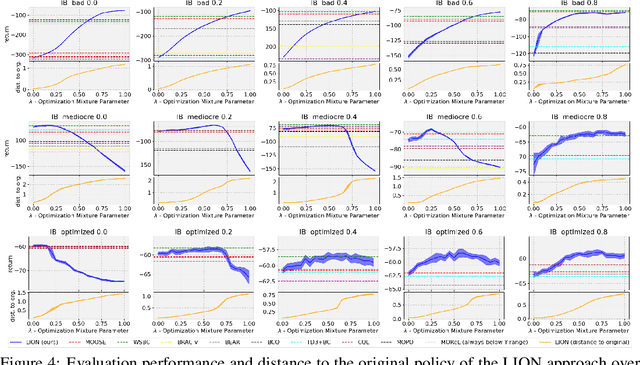
Offline reinforcement learning algorithms still lack trust in practice due to the risk that the learned policy performs worse than the original policy that generated the dataset or behaves in an unexpected way that is unfamiliar to the user. At the same time, offline RL algorithms are not able to tune their most important hyperparameter - the proximity of the learned policy to the original policy. We propose an algorithm that allows the user to tune this hyperparameter at runtime, thereby overcoming both of the above mentioned issues simultaneously. This allows users to start with the original behavior and grant successively greater deviation, as well as stopping at any time when the policy deteriorates or the behavior is too far from the familiar one.
How to Manage Tiny Machine Learning at Scale: An Industrial Perspective
Feb 18, 2022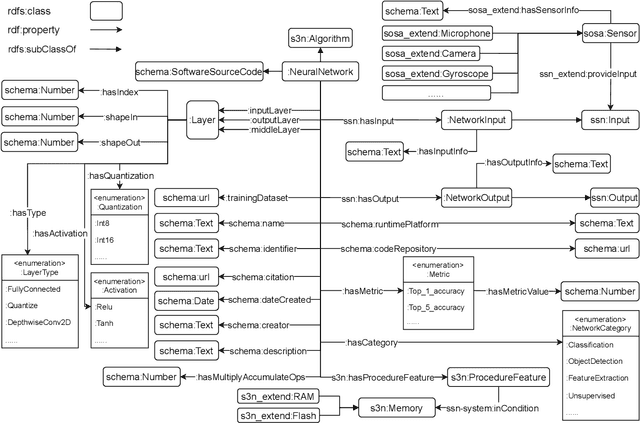
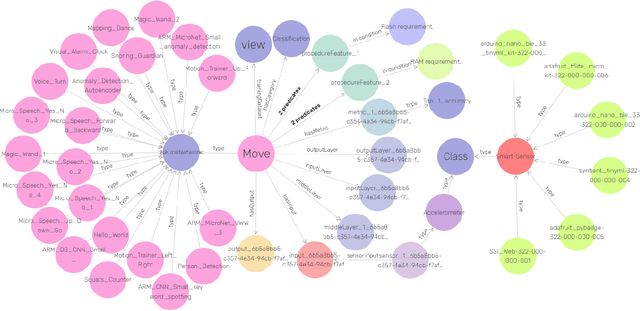
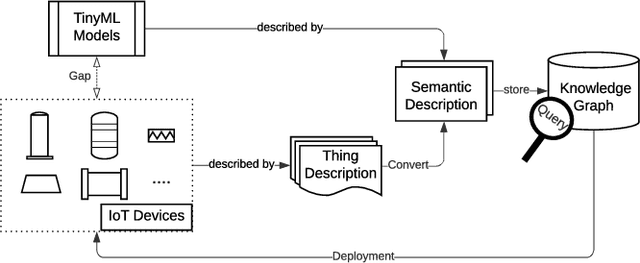
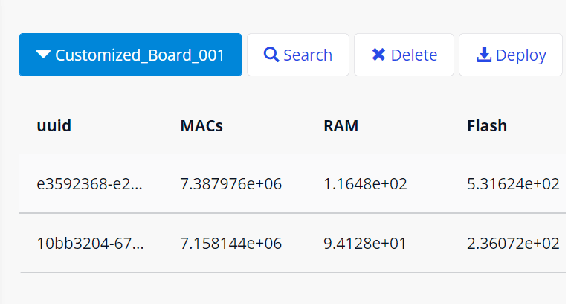
Tiny machine learning (TinyML) has gained widespread popularity where machine learning (ML) is democratized on ubiquitous microcontrollers, processing sensor data everywhere in real-time. To manage TinyML in the industry, where mass deployment happens, we consider the hardware and software constraints, ranging from available onboard sensors and memory size to ML-model architectures and runtime platforms. However, Internet of Things (IoT) devices are typically tailored to specific tasks and are subject to heterogeneity and limited resources. Moreover, TinyML models have been developed with different structures and are often distributed without a clear understanding of their working principles, leading to a fragmented ecosystem. Considering these challenges, we propose a framework using Semantic Web technologies to enable the joint management of TinyML models and IoT devices at scale, from modeling information to discovering possible combinations and benchmarking, and eventually facilitate TinyML component exchange and reuse. We present an ontology (semantic schema) for neural network models aligned with the World Wide Web Consortium (W3C) Thing Description, which semantically describes IoT devices. Furthermore, a Knowledge Graph of 23 publicly available ML models and six IoT devices were used to demonstrate our concept in three case studies, and we shared the code and examples to enhance reproducibility: https://github.com/Haoyu-R/How-to-Manage-TinyML-at-Scale
Comparing Model-free and Model-based Algorithms for Offline Reinforcement Learning
Jan 14, 2022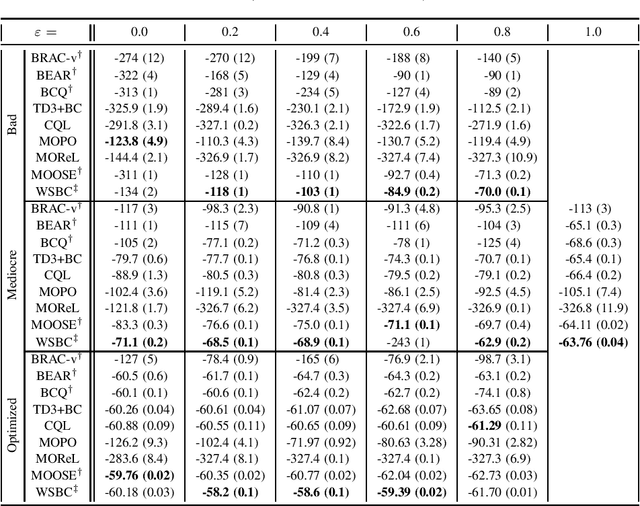
Offline reinforcement learning (RL) Algorithms are often designed with environments such as MuJoCo in mind, in which the planning horizon is extremely long and no noise exists. We compare model-free, model-based, as well as hybrid offline RL approaches on various industrial benchmark (IB) datasets to test the algorithms in settings closer to real world problems, including complex noise and partially observable states. We find that on the IB, hybrid approaches face severe difficulties and that simpler algorithms, such as rollout based algorithms or model-free algorithms with simpler regularizers perform best on the datasets.
Combining Sub-Symbolic and Symbolic Methods for Explainability
Dec 03, 2021

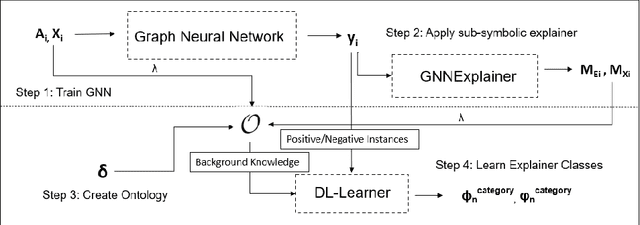

Similarly to other connectionist models, Graph Neural Networks (GNNs) lack transparency in their decision-making. A number of sub-symbolic approaches have been developed to provide insights into the GNN decision making process. These are first important steps on the way to explainability, but the generated explanations are often hard to understand for users that are not AI experts. To overcome this problem, we introduce a conceptual approach combining sub-symbolic and symbolic methods for human-centric explanations, that incorporate domain knowledge and causality. We furthermore introduce the notion of fidelity as a metric for evaluating how close the explanation is to the GNN's internal decision making process. The evaluation with a chemical dataset and ontology shows the explanatory value and reliability of our method.
Measuring Data Quality for Dataset Selection in Offline Reinforcement Learning
Nov 26, 2021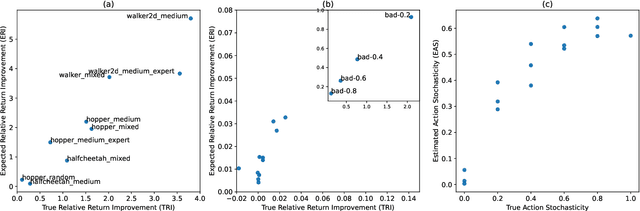
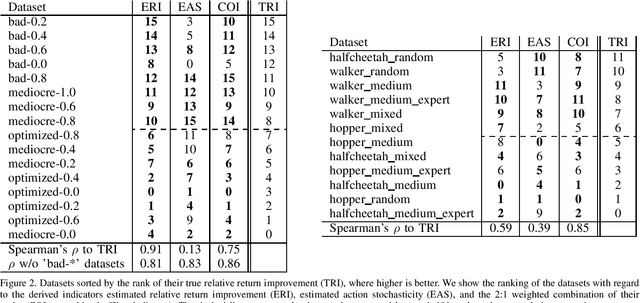
Recently developed offline reinforcement learning algorithms have made it possible to learn policies directly from pre-collected datasets, giving rise to a new dilemma for practitioners: Since the performance the algorithms are able to deliver depends greatly on the dataset that is presented to them, practitioners need to pick the right dataset among the available ones. This problem has so far not been discussed in the corresponding literature. We discuss ideas how to select promising datasets and propose three very simple indicators: Estimated relative return improvement (ERI) and estimated action stochasticity (EAS), as well as a combination of the two (COI), and empirically show that despite their simplicity they can be very effectively used for dataset selection.
Ontology-Based Skill Description Learning for Flexible Production Systems
Nov 25, 2021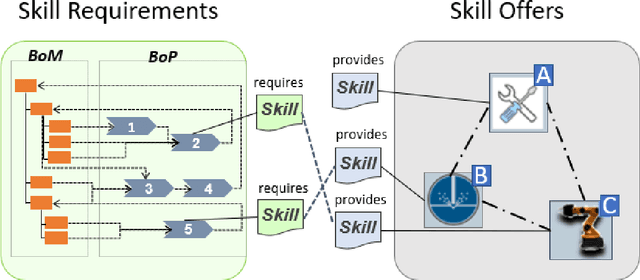
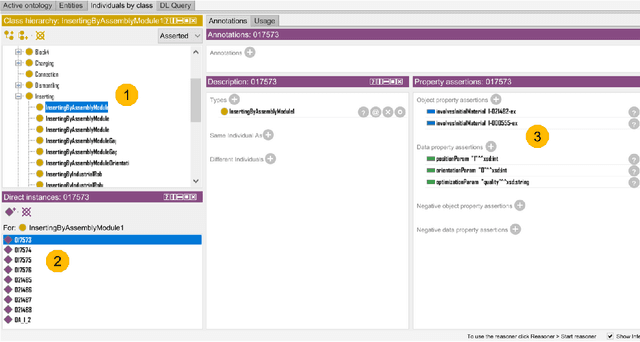
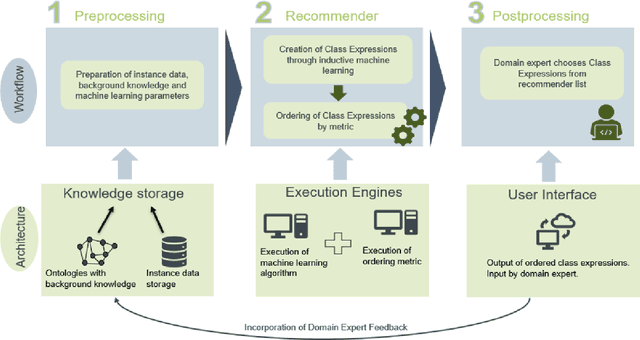
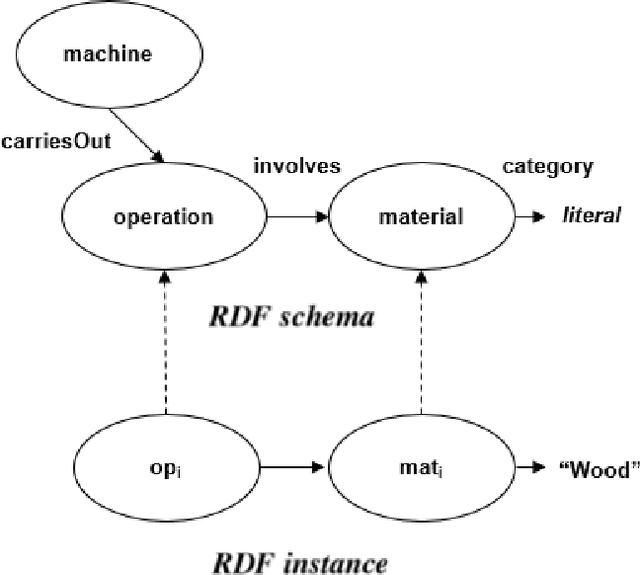
The increasing importance of resource-efficient production entails that manufacturing companies have to create a more dynamic production environment, with flexible manufacturing machines and processes. To fully utilize this potential of dynamic manufacturing through automatic production planning, formal skill descriptions of the machines are essential. However, generating those skill descriptions in a manual fashion is labor-intensive and requires extensive domain-knowledge. In this contribution an ontology-based semi-automatic skill description system that utilizes production logs and industrial ontologies through inductive logic programming is introduced and benefits and drawbacks of the proposed solution are evaluated.
Demystifying Graph Neural Network Explanations
Nov 25, 2021

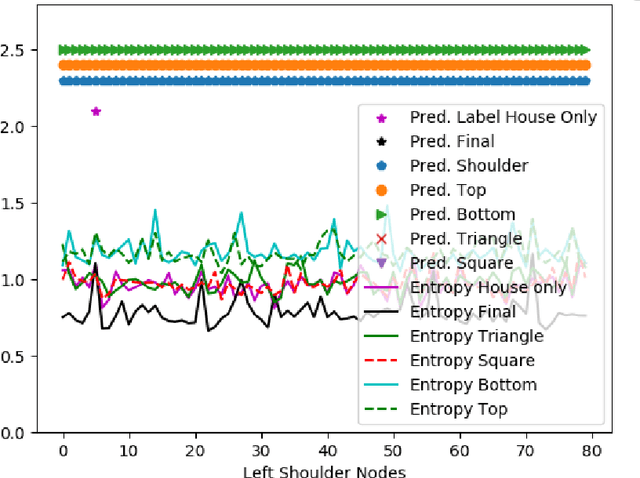

Graph neural networks (GNNs) are quickly becoming the standard approach for learning on graph structured data across several domains, but they lack transparency in their decision-making. Several perturbation-based approaches have been developed to provide insights into the decision making process of GNNs. As this is an early research area, the methods and data used to evaluate the generated explanations lack maturity. We explore these existing approaches and identify common pitfalls in three main areas: (1) synthetic data generation process, (2) evaluation metrics, and (3) the final presentation of the explanation. For this purpose, we perform an empirical study to explore these pitfalls along with their unintended consequences and propose remedies to mitigate their effects.
Towards Data-Free Domain Generalization
Oct 25, 2021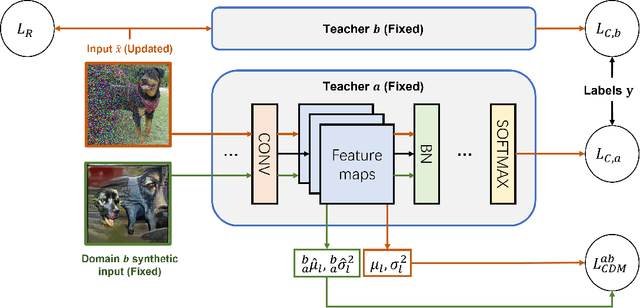
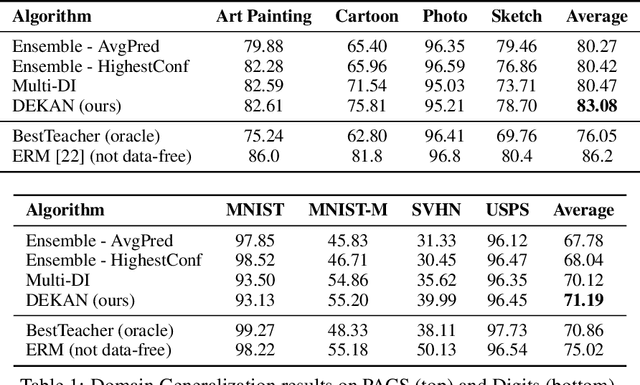
In this work, we investigate the unexplored intersection of domain generalization and data-free learning. In particular, we address the question: How can knowledge contained in models trained on different source data domains can be merged into a single model that generalizes well to unseen target domains, in the absence of source and target domain data? Machine learning models that can cope with domain shift are essential for for real-world scenarios with often changing data distributions. Prior domain generalization methods typically rely on using source domain data, making them unsuitable for private decentralized data. We define the novel problem of Data-Free Domain Generalization (DFDG), a practical setting where models trained on the source domains separately are available instead of the original datasets, and investigate how to effectively solve the domain generalization problem in that case. We propose DEKAN, an approach that extracts and fuses domain-specific knowledge from the available teacher models into a student model robust to domain shift. Our empirical evaluation demonstrates the effectiveness of our method which achieves first state-of-the-art results in DFDG by significantly outperforming ensemble and data-free knowledge distillation baselines.