 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-based Re-identification of Behavioral Clickstream Data
Jan 21, 2022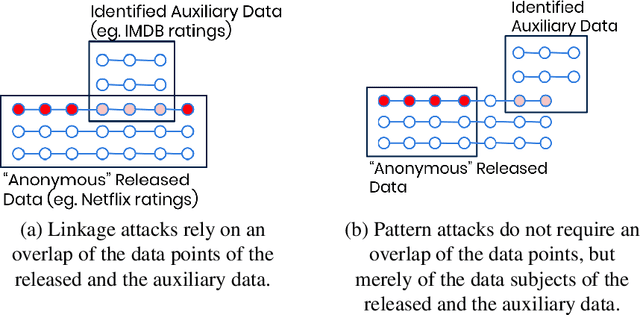


AI-based face recognition, i.e., the re-identification of individuals within images, is an already well established technology for video surveillance, for user authentication, for tagging photos of friends, etc. This paper demonstrates that similar techniques can be applied to successfully re-identify individuals purely based on their behavioral patterns. In contrast to de-anonymization attacks based on record linkage, these methods do not require any overlap in data points between a released dataset and an identified auxiliary dataset. The mere resemblance of behavioral patterns between records is sufficient to correctly attribute behavioral data to identified individuals. Further, we can demonstrate that data perturbation does not provide protection, unless a significant share of data utility is being destroyed. These findings call for sincere cautions when sharing actual behavioral data with third parties, as modern-day privacy regulations, like the GDPR, define their scope based on the ability to re-identify. This has also strong implications for the Marketing domain, when dealing with potentially re-identify-able data sources like shopping behavior, clickstream data or cockies. We also demonstrate how synthetic data can offer a viable alternative, that is shown to be resilient against our introduced AI-based re-identification attacks.
Holdout-Based Fidelity and Privacy Assessment of Mixed-Type Synthetic Data
Apr 01, 2021
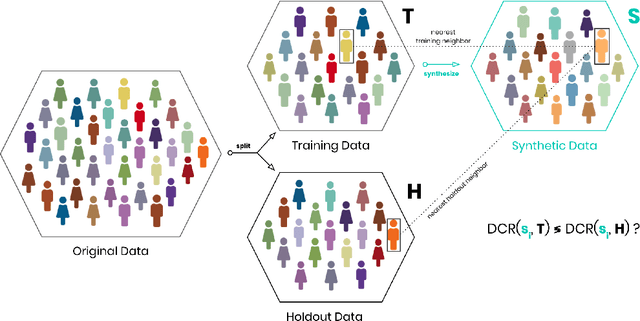
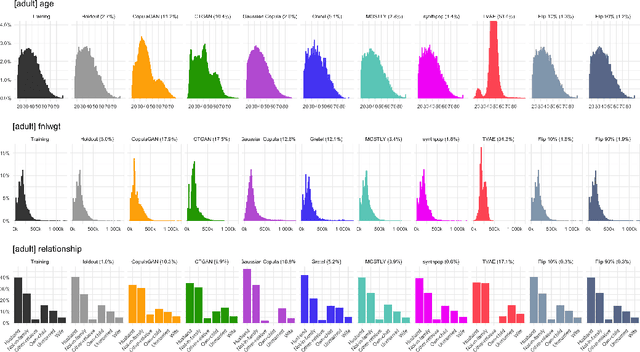
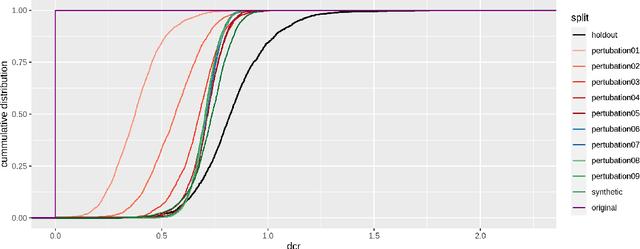
AI-based data synthesis has seen rapid progress over the last several years, and is increasingly recognized for its promise to enable privacy-respecting high-fidelity data sharing. However, adequately evaluating the quality of generated synthetic datasets is still an open challenge. We introduce and demonstrate a holdout-based empirical assessment framework for quantifying the fidelity as well as the privacy risk of synthetic data solutions for mixed-type tabular data. Measuring fidelity is based on statistical distances of lower-dimensional marginal distributions, which provide a model-free and easy-to-communicate empirical metric for the representativeness of a synthetic dataset. Privacy risk is assessed by calculating the individual-level distances to closest record with respect to the training data. By showing that the synthetic samples are just as close to the training as to the holdout data, we yield strong evidence that the synthesizer indeed learned to generalize patterns and is independent of individual training records. We demonstrate the presented framework for seven distinct synthetic data solutions across four mixed-type datasets and compare these to more traditional statistical disclosure techniques. The results highlight the need to systematically assess the fidelity just as well as the privacy of these emerging class of synthetic data generators.