 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing GPUs And LLMs Can Be Satisfying for Nonlinear Real Arithmetic Problems
Mar 08, 2026Solving quantifier-free non-linear real arithmetic (NRA) problems is a computationally hard task. To tackle this problem, prior work proposed a promising approach based on gradient descent. In this work, we extend their ideas and combine LLMs and GPU acceleration to obtain an efficient technique. We have implemented our findings in the novel SMT solver GANRA (GPU Accelerated solving of Nonlinear Real Arithmetic problems). We evaluate GANRA on two different NRA benchmarks and demonstrate significant improvements over the previous state of the art. In particular, on the Sturm-MBO benchmark, we can prove satisfiability for more than five times as many instances in less than 1/20th of the previous state-of-the-art runtime.
Debona: Decoupled Boundary Network Analysis for Tighter Bounds and Faster Adversarial Robustness Proofs
Jun 16, 2020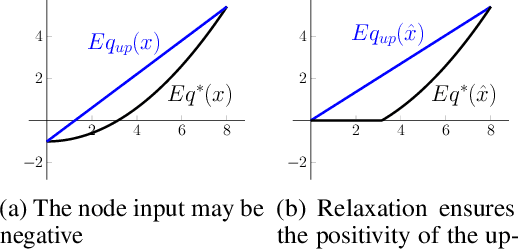
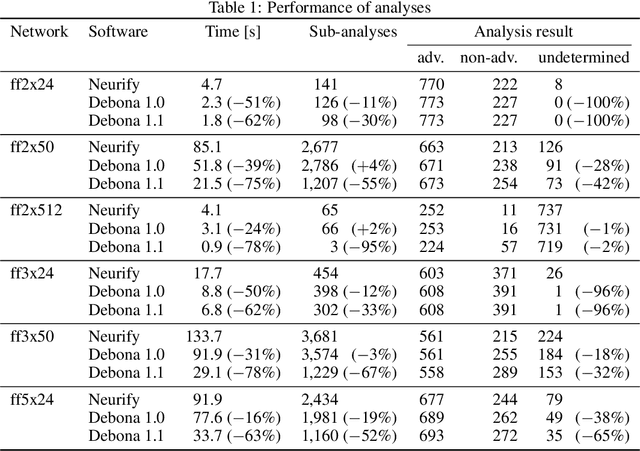
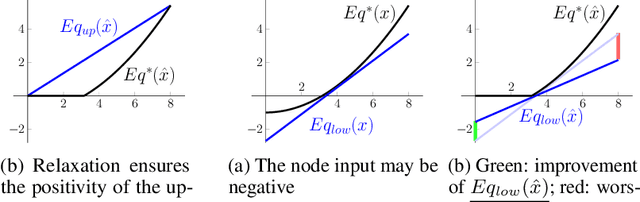
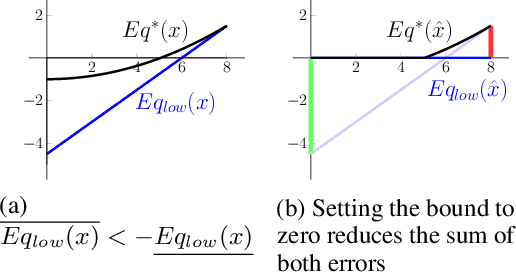
Neural networks are commonly used in safety-critical real-world applications. Unfortunately, the predicted output is often highly sensitive to small, and possibly imperceptible, changes to the input data. Proving that either no such adversarial examples exist, or providing a concrete instance, is therefore crucial to ensure safe applications. As enumerating and testing all potential adversarial examples is computationally infeasible, verification techniques have been developed to provide mathematically sound proofs of their absence using overestimations of the network activations. We propose an improved technique for computing tight upper and lower bounds of these node values, based on increased flexibility gained by computing both bounds independently of each other. Furthermore, we gain an additional improvement by re-implementing part of the original state-of-the-art software "Neurify", leading to a faster analysis. Combined, these adaptations reduce the necessary runtime by up to 78%, and allow a successful search for networks and inputs that were previously too complex. Finally, we provide proofs for tight upper and lower bounds on max-pooling layers in convolutional networks. To ensure widespread usability, we open source our implementation "Debona", featuring both the implementation specific enhancements as well as the refined boundary computation for faster and more exact results.