 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Excitation Skewness for Automatic Speech Polarity Detection
May 31, 2020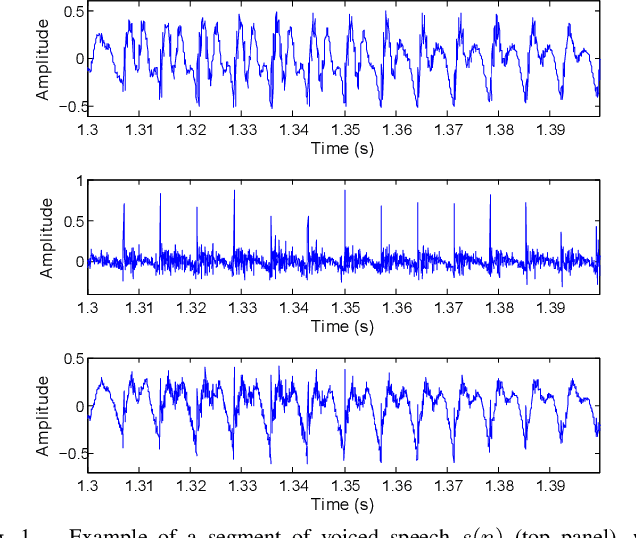
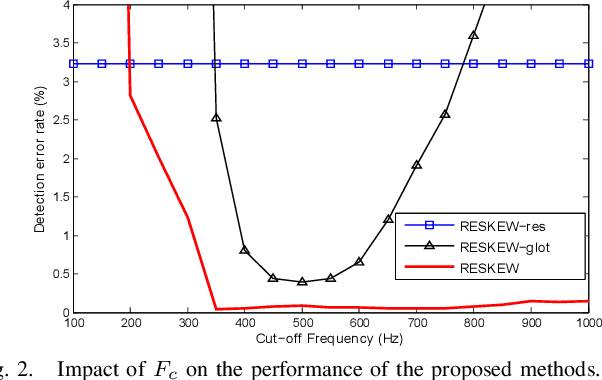

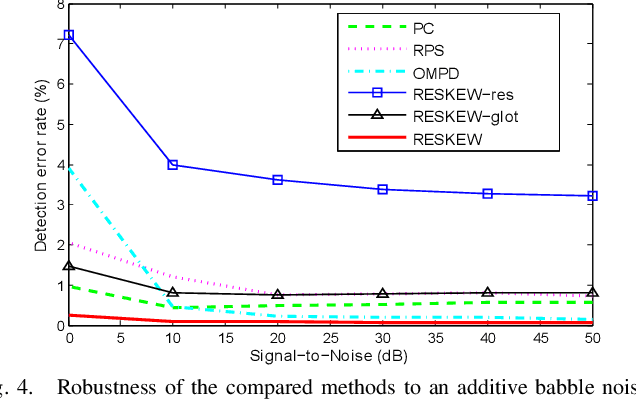
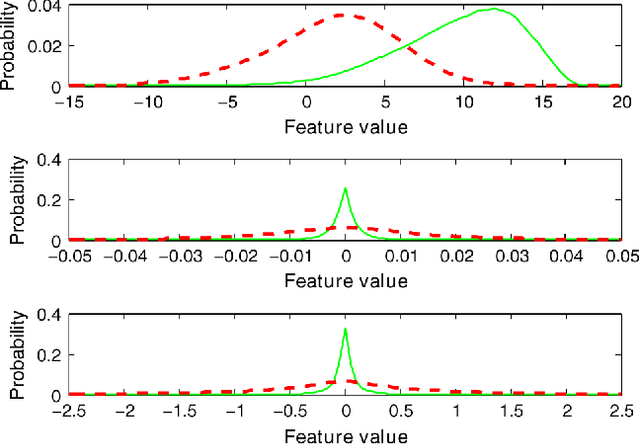
Detecting the correct speech polarity is a necessary step prior to several speech processing techniques. An error on its determination could have a dramatic detrimental impact on their performance. As current systems have to deal with increasing amounts of data stemming from multiple devices, the automatic detection of speech polarity has become a crucial problem. For this purpose, we here propose a very simple algorithm based on the skewness of two excitation signals. The method is shown on 10 speech corpora (8545 files) to lead to an error rate of only 0.06% in clean conditions and to clearly outperform four state-of-the-art methods. Besides it significantly reduces the computational load through its simplicity and is observed to exhibit the strongest robustness in both noisy and reverberant environments.
Maximum Voiced Frequency Estimation: Exploiting Amplitude and Phase Spectra
May 31, 2020
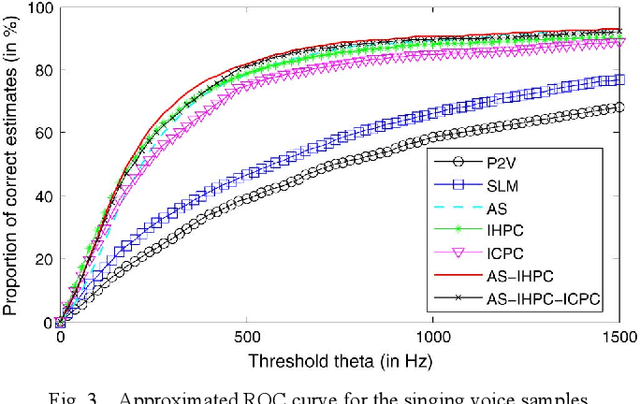
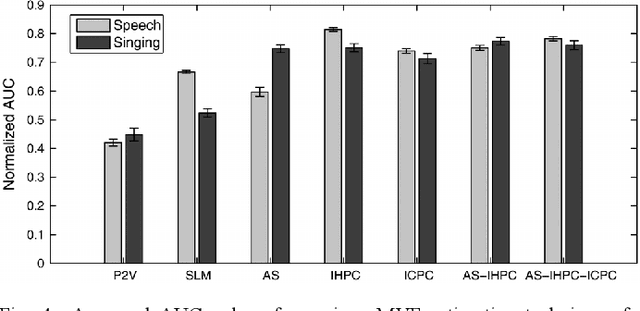
Maximum Voiced Frequency (MVF) is used in various speech models as the spectral boundary separating periodic and aperiodic components during the production of voiced sounds. Recent studies have shown that its proper estimation and modeling enhance the quality of statistical parametric speech synthesizers. Contrastingly, these same methods of MVF estimation have been reported to degrade the performance of singing voice synthesizers. This paper proposes a new approach for MVF estimation which exploits both amplitude and phase spectra. It is shown that phase conveys relevant information about the harmonicity of the voice signal, and that it can be jointly used with features derived from the amplitude spectrum. This information is further integrated into a maximum likelihood criterion which provides a decision about the MVF estimate. The proposed technique is compared to two state-of-the-art methods, and shows a superior performance in both objective and subjective evaluations. Perceptual tests indicate a drastic improvement in high-pitched voices.
Data-driven Detection and Analysis of the Patterns of Creaky Voice
May 31, 2020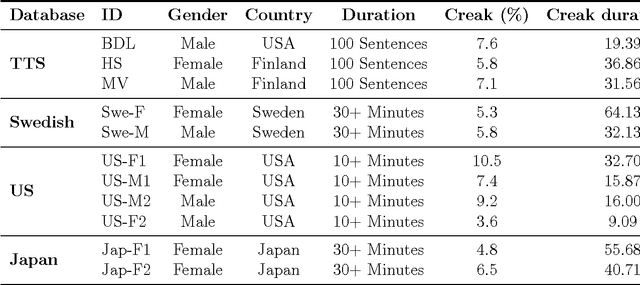
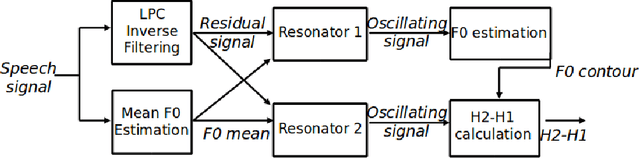
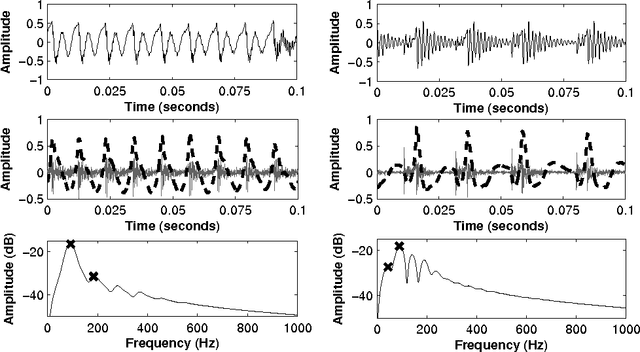
This paper investigates the temporal excitation patterns of creaky voice. Creaky voice is a voice quality frequently used as a phrase-boundary marker, but also as a means of portraying attitude, affective states and even social status. Consequently, the automatic detection and modelling of creaky voice may have implications for speech technology applications. The acoustic characteristics of creaky voice are, however, rather distinct from modal phonation. Further, several acoustic patterns can bring about the perception of creaky voice, thereby complicating the strategies used for its automatic detection, analysis and modelling. The present study is carried out using a variety of languages, speakers, and on both read and conversational data and involves a mutual information-based assessment of the various acoustic features proposed in the literature for detecting creaky voice. These features are then exploited in classification experiments where we achieve an appreciable improvement in detection accuracy compared to the state of the art. Both experiments clearly highlight the presence of several creaky patterns. A subsequent qualitative and quantitative analysis of the identified patterns is provided, which reveals a considerable speaker-dependent variability in the usage of these creaky patterns. We also investigate how creaky voice detection systems perform across creaky patterns.
Glottal source estimation robustness: A comparison of sensitivity of voice source estimation techniques
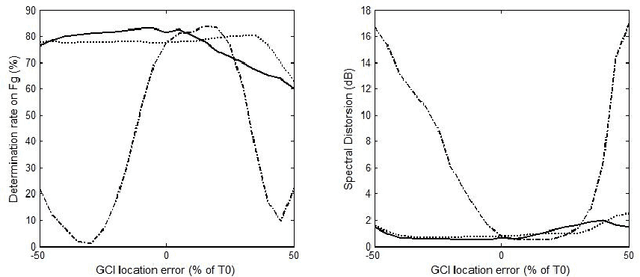
May 24, 2020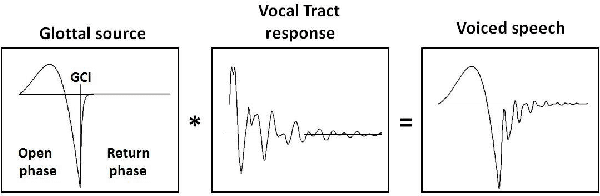

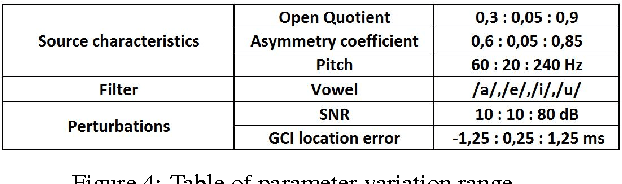
This paper addresses the problem of estimating the voice source directly from speech waveforms. A novel principle based on Anticausality Dominated Regions (ACDR) is used to estimate the glottal open phase. This technique is compared to two other state-of-the-art well-known methods, namely the Zeros of the Z-Transform (ZZT) and the Iterative Adaptive Inverse Filtering (IAIF) algorithms. Decomposition quality is assessed on synthetic signals through two objective measures: the spectral distortion and a glottal formant determination rate. Technique robustness is tested by analyzing the influence of noise and Glottal Closure Instant (GCI) location errors. Besides impacts of the fundamental frequency and the first formant on the performance are evaluated. Our proposed approach shows significant improvement in robustness, which could be of a great interest when decomposing real speech.
Oscillating Statistical Moments for Speech Polarity Detection
May 16, 2020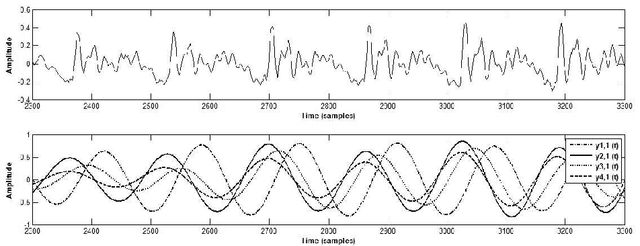
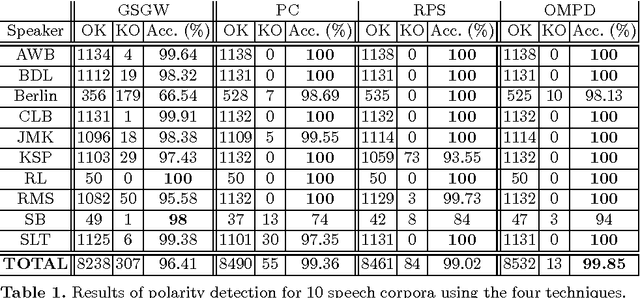
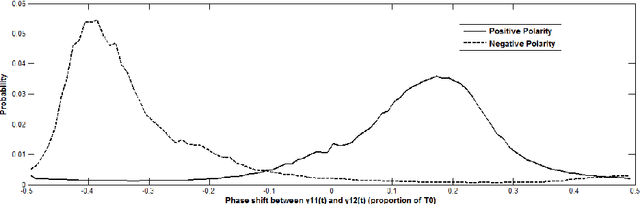
An inversion of the speech polarity may have a dramatic detrimental effect on the performance of various techniques of speech processing. An automatic method for determining the speech polarity (which is dependent upon the recording setup) is thus required as a preliminary step for ensuring the well-behaviour of such techniques. This paper proposes a new approach of polarity detection relying on oscillating statistical moments. These moments have the property to oscillate at the local fundamental frequency and to exhibit a phase shift which depends on the speech polarity. This dependency stems from the introduction of non-linearity or higher-order statistics in the moment calculation. The resulting method is shown on 10 speech corpora to provide a substantial improvement compared to state-of-the-art techniques.
Glottal Source Estimation using an Automatic Chirp Decomposition
May 16, 2020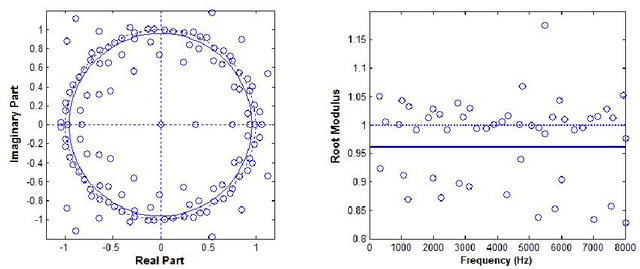

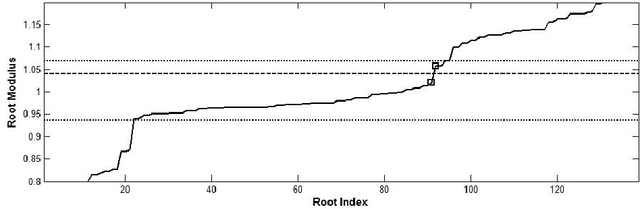
In a previous work, we showed that the glottal source can be estimated from speech signals by computing the Zeros of the Z-Transform (ZZT). Decomposition was achieved by separating the roots inside (causal contribution) and outside (anticausal contribution) the unit circle. In order to guarantee a correct deconvolution, time alignment on the Glottal Closure Instants (GCIs) was shown to be essential. This paper extends the formalism of ZZT by evaluating the Z-transform on a contour possibly different from the unit circle. A method is proposed for determining automatically this contour by inspecting the root distribution. The derived Zeros of the Chirp Z-Transform (ZCZT)-based technique turns out to be much more robust to GCI location errors.
Chirp Complex Cepstrum-based Decomposition for Asynchronous Glottal Analysis
May 10, 2020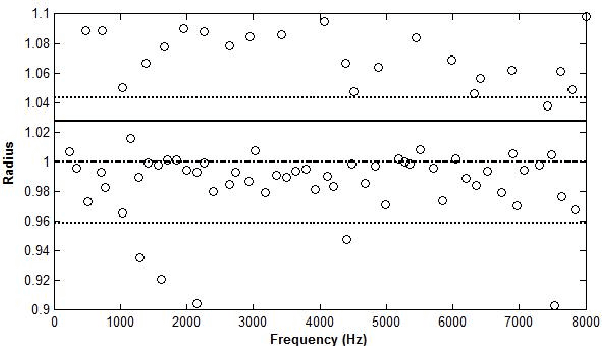
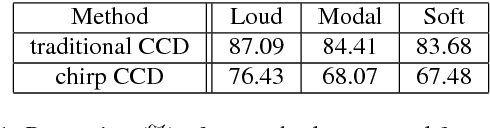
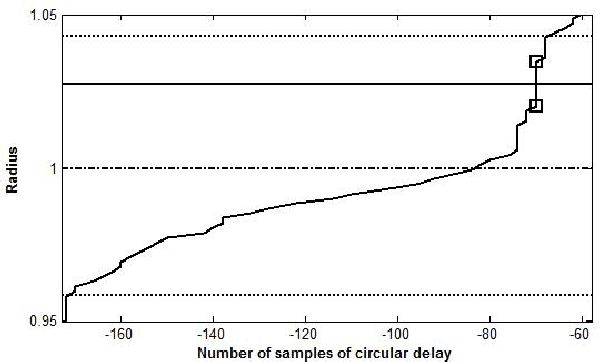
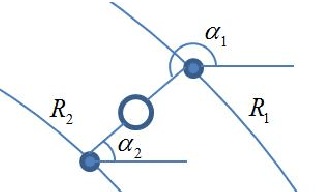
It was recently shown that complex cepstrum can be effectively used for glottal flow estimation by separating the causal and anticausal components of speech. In order to guarantee a correct estimation, some constraints on the window have been derived. Among these, the window has to be synchronized on a Glottal Closure Instant. This paper proposes an extension of the complex cepstrum-based decomposition by incorporating a chirp analysis. The resulting method is shown to give a reliable estimation of the glottal flow wherever the window is located. This technique is then suited for its integration in usual speech processing systems, which generally operate in an asynchronous way. Besides its potential for automatic voice quality analysis is highlighted.
Voice Conversion for Whispered Speech Synthesis
Jan 17, 2020
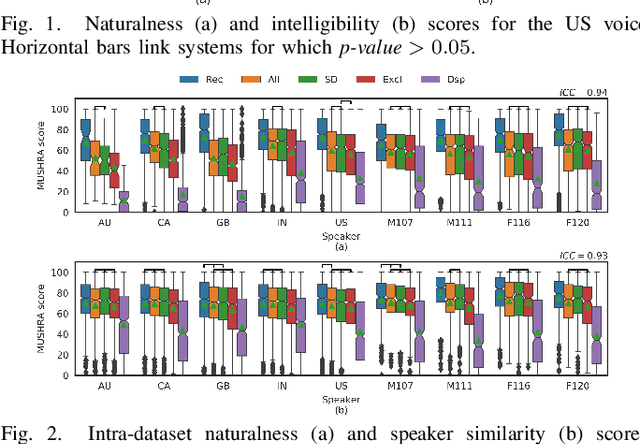
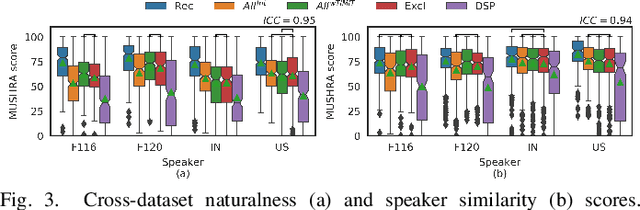
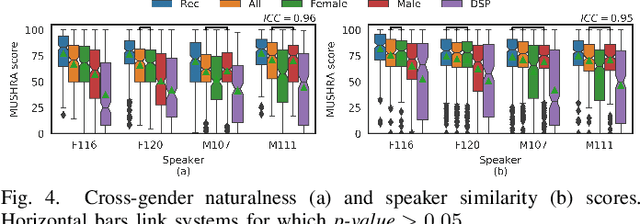
We present an approach to synthesize whisper by applying a handcrafted signal processing recipe and Voice Conversion (VC) techniques to convert normally phonated speech to whispered speech. We investigate using Gaussian Mixture Models (GMM) and Deep Neural Networks (DNN) to model the mapping between acoustic features of normal speech and those of whispered speech. We evaluate naturalness and speaker similarity of the converted whisper on an internal corpus and on the publicly available wTIMIT corpus. We show that applying VC techniques is significantly better than using rule-based signal processing methods and it achieves results that are indistinguishable from copy-synthesis of natural whisper recordings. We investigate the ability of the DNN model to generalize on unseen speakers, when trained with data from multiple speakers. We show that excluding the target speaker from the training set has little or no impact on the perceived naturalness and speaker similarity of the converted whisper. The proposed DNN method is used in the newly released Whisper Mode of Amazon Alexa.
On the Mutual Information between Source and Filter Contributions for Voice Pathology Detection
Jan 02, 2020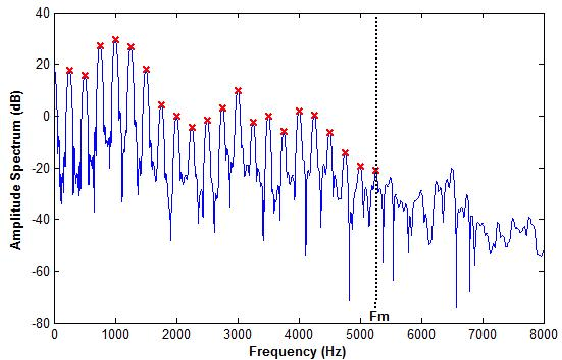
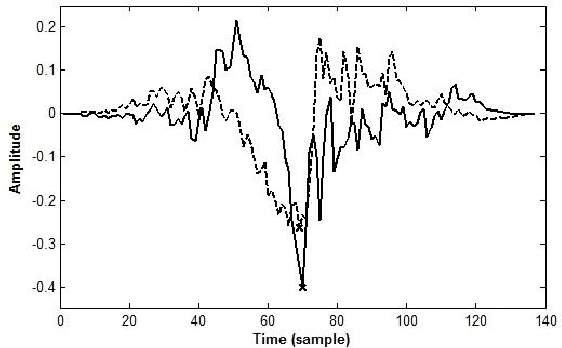
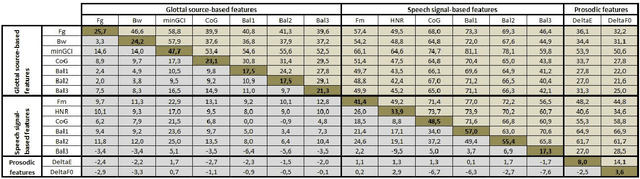
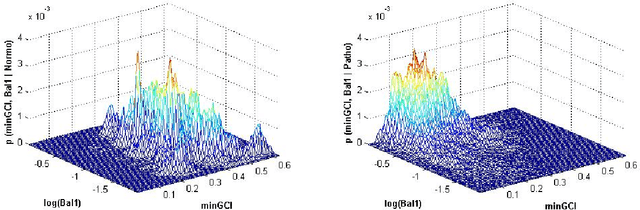
This paper addresses the problem of automatic detection of voice pathologies directly from the speech signal. For this, we investigate the use of the glottal source estimation as a means to detect voice disorders. Three sets of features are proposed, depending on whether they are related to the speech or the glottal signal, or to prosody. The relevancy of these features is assessed through mutual information-based measures. This allows an intuitive interpretation in terms of discrimation power and redundancy between the features, independently of any subsequent classifier. It is discussed which characteristics are interestingly informative or complementary for detecting voice pathologies.
Phase-based Information for Voice Pathology Detection
Jan 02, 2020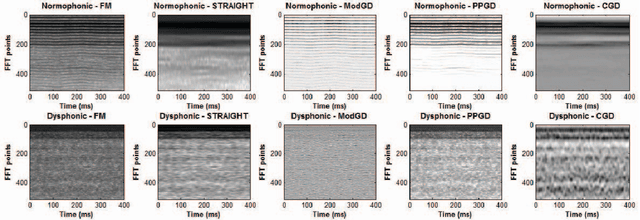


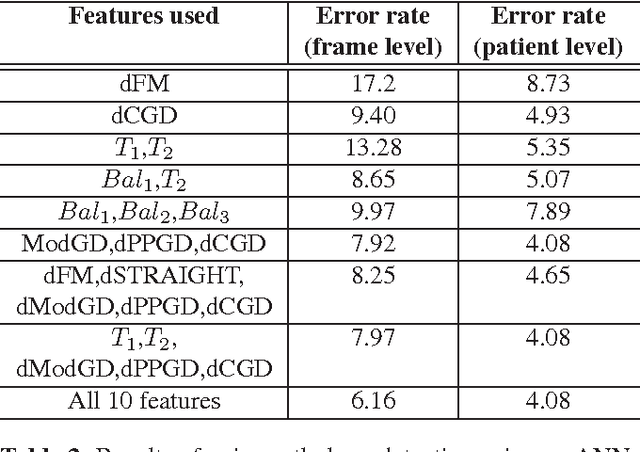
In most current approaches of speech processing, information is extracted from the magnitude spectrum. However recent perceptual studies have underlined the importance of the phase component. The goal of this paper is to investigate the potential of using phase-based features for automatically detecting voice disorders. It is shown that group delay functions are appropriate for characterizing irregularities in the phonation. Besides the respect of the mixed-phase model of speech is discussed. The proposed phase-based features are evaluated and compared to other parameters derived from the magnitude spectrum. Both streams are shown to be interestingly complementary. Furthermore phase-based features turn out to convey a great amount of relevant information, leading to high discrimination performance.