 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtures of Transparent Local Models
Jan 15, 2026The predominance of machine learning models in many spheres of human activity has led to a growing demand for their transparency. The transparency of models makes it possible to discern some factors, such as security or non-discrimination. In this paper, we propose a mixture of transparent local models as an alternative solution for designing interpretable (or transparent) models. Our approach is designed for the situations where a simple and transparent function is suitable for modeling the label of instances in some localities/regions of the input space, but may change abruptly as we move from one locality to another. Consequently, the proposed algorithm is to learn both the transparent labeling function and the locality of the input space where the labeling function achieves a small risk in its assigned locality. By using a new multi-predictor (and multi-locality) loss function, we established rigorous PAC-Bayesian risk bounds for the case of binary linear classification problem and that of linear regression. In both cases, synthetic data sets were used to illustrate how the learning algorithms work. The results obtained from real data sets highlight the competitiveness of our approach compared to other existing methods as well as certain opaque models. Keywords: PAC-Bayes, risk bounds, local models, transparent models, mixtures of local transparent models.
Detection of Block-Exchangeable Structure in Large-Scale Correlation Matrices
Oct 24, 2018

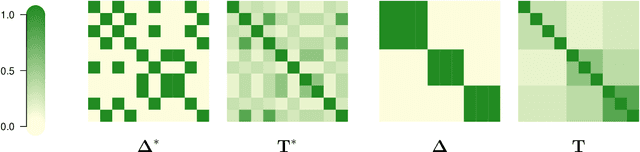

Correlation matrices are omnipresent in multivariate data analysis. When the number d of variables is large, the sample estimates of correlation matrices are typically noisy and conceal underlying dependence patterns. We consider the case when the variables can be grouped into K clusters with exchangeable dependence; this assumption is often made in applications, e.g., in finance and econometrics. Under this partial exchangeability condition, the corresponding correlation matrix has a block structure and the number of unknown parameters is reduced from d(d-1)/2 to at most K(K+1)/2. We propose a robust algorithm based on Kendall's rank correlation to identify the clusters without assuming the knowledge of K a priori or anything about the margins except continuity. The corresponding block-structured estimator performs considerably better than the sample Kendall rank correlation matrix when K < d. The new estimator can also be much more efficient in finite samples even in the unstructured case K = d, although there is no gain asymptotically. When the distribution of the data is elliptical, the results extend to linear correlation matrices and their inverses. The procedure is illustrated on financial stock returns.