 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Grammatical Error Correction for Romanian
Apr 26, 2026Resources for Grammatical Error Correction (GEC) in non-English languages are scarce, while available spellcheckers in these languages are mostly limited to simple corrections and rules. In this paper we introduce a first GEC corpus for Romanian consisting of 10k pairs of sentences. In addition, the German version of ERRANT (ERRor ANnotation Toolkit) scorer was adapted for Romanian to analyze this corpus and extract edits needed for evaluation. Multiple neural models were experimented, together with pretraining strategies, which proved effective for GEC in low-resource settings. Our baseline consists of a small Transformer model trained only on the GEC dataset (F0.5 of 44.38), whereas the best performing model is produced by pretraining a larger Transformer model on artificially generated data, followed by finetuning on the actual corpus (F0.5 of 53.76). The proposed method for generating additional training examples is easily extensible and can be applied to any language, as it requires only a POS tagger
Romanian Diacritics Restoration Using Recurrent Neural Networks
Sep 06, 2020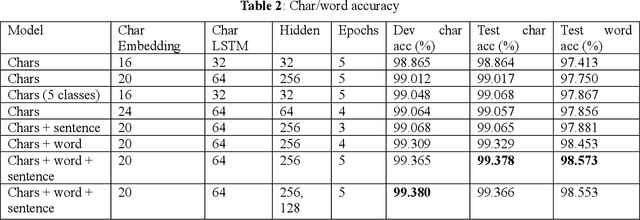
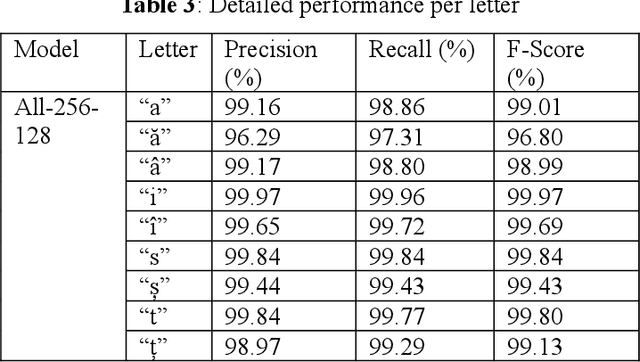
Diacritics restoration is a mandatory step for adequately processing Romanian texts, and not a trivial one, as you generally need context in order to properly restore a character. Most previous methods which were experimented for Romanian restoration of diacritics do not use neural networks. Among those that do, there are no solutions specifically optimized for this particular language (i.e., they were generally designed to work on many different languages). Therefore we propose a novel neural architecture based on recurrent neural networks that can attend information at different levels of abstractions in order to restore diacritics.