 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Adversarial Traffic Generation : Black-box Approach to Evade Intrusion Detection Systems in IoT Networks
Mar 24, 2026The integration of machine learning (ML) algorithms into Internet of Things (IoT) applications has introduced significant advantages alongside vulnerabilities to adversarial attacks, especially within IoT-based intrusion detection systems (IDS). While theoretical adversarial attacks have been extensively studied, practical implementation constraints have often been overlooked. This research addresses this gap by evaluating the feasibility of evasion attacks on IoT network-based IDSs, employing a novel black-box adversarial attack. Our study aims to bridge theoretical vulnerabilities with real-world applicability, enhancing understanding and defense against sophisticated threats in modern IoT ecosystems. Additionally, we propose a defense scheme tailored to mitigate the impact of evasion attacks, thereby reinforcing the resilience of ML-based IDSs. Our findings demonstrate successful evasion attacks against IDSs, underscoring their susceptibility to advanced techniques. In contrast, we proposed a defense mechanism that exhibits robust performance by effectively detecting the majority of adversarial traffic, showcasing promising outcomes compared to current state-of-the-art defenses. By addressing these critical cybersecurity challenges, our research contributes to advancing IoT security and provides insights for developing more resilient IDS.
* Already published in International Journal of Machine Learning and Cybernetics. Debicha, I., Kenaza, T., Charfi, I. et al. Targeted adversarial traffic generation: black-box approach to evade intrusion detection systems in IoT networks. Int. J. Mach. Learn. & Cyber. 17, 58 (2026). https://doi.org/10.1007/s13042-025-02873-w
Review on the Feasibility of Adversarial Evasion Attacks and Defenses for Network Intrusion Detection Systems
Mar 13, 2023

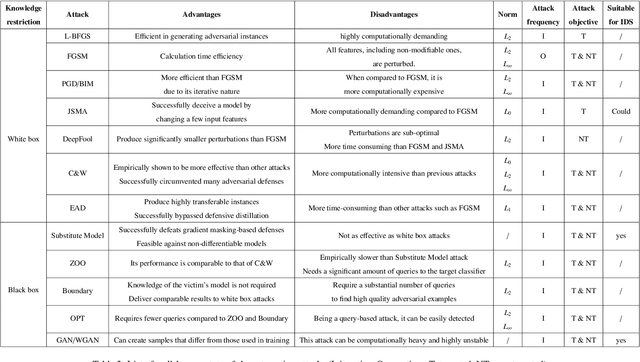
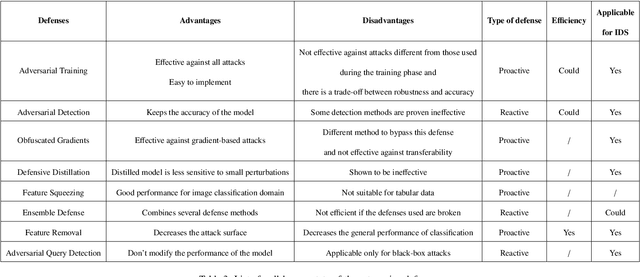
Nowadays, numerous applications incorporate machine learning (ML) algorithms due to their prominent achievements. However, many studies in the field of computer vision have shown that ML can be fooled by intentionally crafted instances, called adversarial examples. These adversarial examples take advantage of the intrinsic vulnerability of ML models. Recent research raises many concerns in the cybersecurity field. An increasing number of researchers are studying the feasibility of such attacks on security systems based on ML algorithms, such as Intrusion Detection Systems (IDS). The feasibility of such adversarial attacks would be influenced by various domain-specific constraints. This can potentially increase the difficulty of crafting adversarial examples. Despite the considerable amount of research that has been done in this area, much of it focuses on showing that it is possible to fool a model using features extracted from the raw data but does not address the practical side, i.e., the reverse transformation from theory to practice. For this reason, we propose a review browsing through various important papers to provide a comprehensive analysis. Our analysis highlights some challenges that have not been addressed in the reviewed papers.
Adv-Bot: Realistic Adversarial Botnet Attacks against Network Intrusion Detection Systems
Mar 12, 2023Due to the numerous advantages of machine learning (ML) algorithms, many applications now incorporate them. However, many studies in the field of image classification have shown that MLs can be fooled by a variety of adversarial attacks. These attacks take advantage of ML algorithms' inherent vulnerability. This raises many questions in the cybersecurity field, where a growing number of researchers are recently investigating the feasibility of such attacks against machine learning-based security systems, such as intrusion detection systems. The majority of this research demonstrates that it is possible to fool a model using features extracted from a raw data source, but it does not take into account the real implementation of such attacks, i.e., the reverse transformation from theory to practice. The real implementation of these adversarial attacks would be influenced by various constraints that would make their execution more difficult. As a result, the purpose of this study was to investigate the actual feasibility of adversarial attacks, specifically evasion attacks, against network-based intrusion detection systems (NIDS), demonstrating that it is entirely possible to fool these ML-based IDSs using our proposed adversarial algorithm while assuming as many constraints as possible in a black-box setting. In addition, since it is critical to design defense mechanisms to protect ML-based IDSs against such attacks, a defensive scheme is presented. Realistic botnet traffic traces are used to assess this work. Our goal is to create adversarial botnet traffic that can avoid detection while still performing all of its intended malicious functionality.
* This work is published in Computers & Security (an Elsevier journal) https://www.sciencedirect.com/science/article/pii/S016740482300086X
TAD: Transfer Learning-based Multi-Adversarial Detection of Evasion Attacks against Network Intrusion Detection Systems
Oct 27, 2022Nowadays, intrusion detection systems based on deep learning deliver state-of-the-art performance. However, recent research has shown that specially crafted perturbations, called adversarial examples, are capable of significantly reducing the performance of these intrusion detection systems. The objective of this paper is to design an efficient transfer learning-based adversarial detector and then to assess the effectiveness of using multiple strategically placed adversarial detectors compared to a single adversarial detector for intrusion detection systems. In our experiments, we implement existing state-of-the-art models for intrusion detection. We then attack those models with a set of chosen evasion attacks. In an attempt to detect those adversarial attacks, we design and implement multiple transfer learning-based adversarial detectors, each receiving a subset of the information passed through the IDS. By combining their respective decisions, we illustrate that combining multiple detectors can further improve the detectability of adversarial traffic compared to a single detector in the case of a parallel IDS design.
* This is a preprint of an already published journal paper
Detect & Reject for Transferability of Black-box Adversarial Attacks Against Network Intrusion Detection Systems
Dec 22, 2021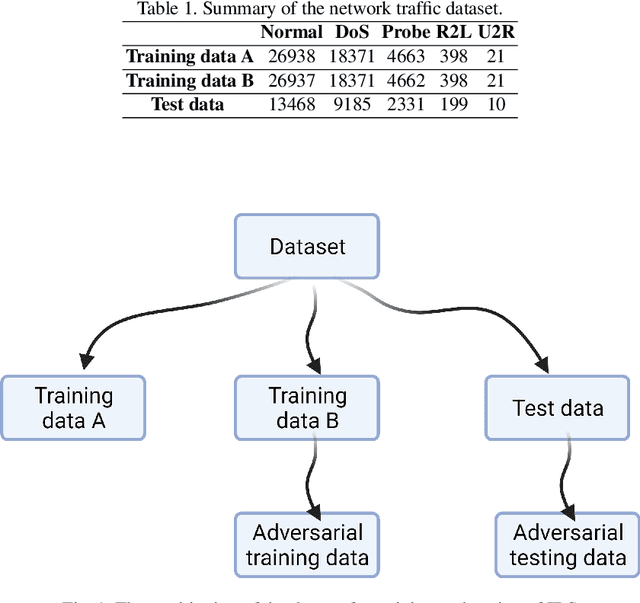

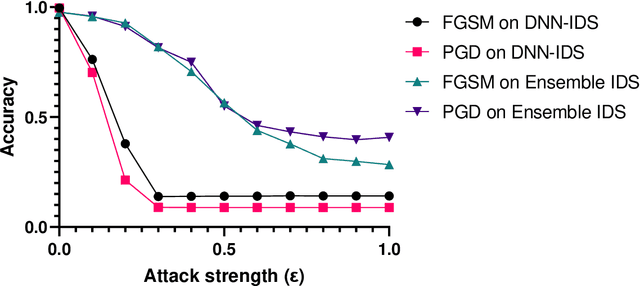
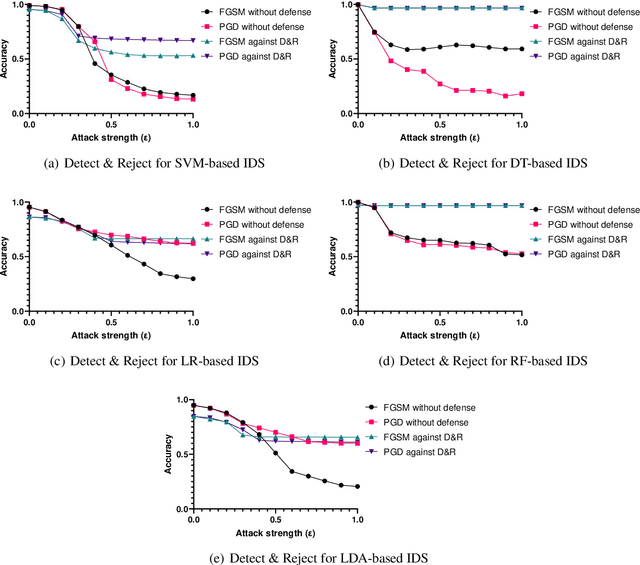
In the last decade, the use of Machine Learning techniques in anomaly-based intrusion detection systems has seen much success. However, recent studies have shown that Machine learning in general and deep learning specifically are vulnerable to adversarial attacks where the attacker attempts to fool models by supplying deceptive input. Research in computer vision, where this vulnerability was first discovered, has shown that adversarial images designed to fool a specific model can deceive other machine learning models. In this paper, we investigate the transferability of adversarial network traffic against multiple machine learning-based intrusion detection systems. Furthermore, we analyze the robustness of the ensemble intrusion detection system, which is notorious for its better accuracy compared to a single model, against the transferability of adversarial attacks. Finally, we examine Detect & Reject as a defensive mechanism to limit the effect of the transferability property of adversarial network traffic against machine learning-based intrusion detection systems.