 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking and Event-driven Neuromorphic Mamba Models for Efficient Speech Recognition
May 31, 2026Deep learning has greatly advanced automatic speech recognition (ASR), enabling widespread deployment on edge devices such as smartphones and smart home systems. However, the computational and energy demands of deep neural networks pose significant challenges for such resource-constrained deployments, introducing latency and limiting real-time interaction. Neuromorphic computing offers a promising solution by introducing activation sparsity through spiking neural networks (SNNs) and event-driven neural networks, converting dense operations into sparse computations. However, a study that evaluates the hardware benefits of different neuromorphic strategies remains lacking for ASR. This paper explores spiking and event-driven neuromorphic neural networks to improve activation sparsity in the state-of-the-art SpeechMamba model for ASR. We introduce an event-driven SpeechMamba with FATReLU activation, achieving over 60% activation sparsity with less than 1% accuracy degradation on LibriSpeech. We also propose a spiking SpeechMamba that attains over 70% sparsity while using 30% fewer parameters than comparable SNNs. Finally, we develop a cycle-accurate event-driven simulator enabling flexible algorithm-hardware co-exploration, which helps us identify computational bottlenecks and yields over 10% additional efficiency improvements.
Comparative Evaluation of Deep Learning Models for Fake Image Detection
May 20, 2026The growing sophistication of GAN-based image manipulation presents significant challenges for digital forensics. This study compares the performance of four pretrained CNN architectures including VGG16, ResNet50, EfficientNetB0, and XceptionNet for fake image detection using a unified preprocessing and training pipeline. A dataset of real and manipulated images was processed through resizing, normalization, and augmentation to address class imbalance and improve generalization. Models were evaluated using Accuracy, Precision, Recall, F1-score, and ROC-AUC. VGG16 achieved the highest accuracy at 91%, with XceptionNet, ResNet50, and EfficientNetB0 each reaching 90%. EfficientNetB0 showed stronger sensitivity to fake images but reduced reliability on real samples, reflecting imbalance-driven bias. Limitations include dataset imbalance, overfitting, and limited interpretability, which affect cross-domain robustness. The study provides a reproducible baseline and underscores the need for balanced datasets, advanced augmentation, and fairness-aware training to develop reliable fake image detection systems.
* Accepted at ICCIIoT26 and waiting to be indexed
Code Switching Language Model Using Monolingual Training Data
Dec 24, 2020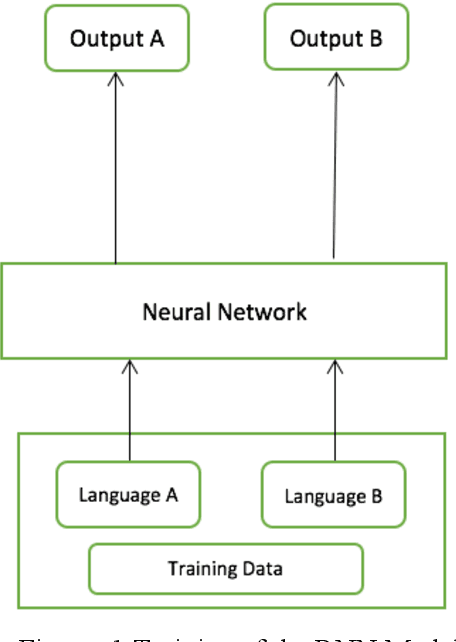

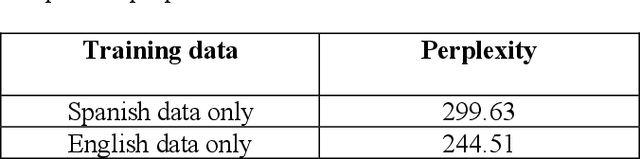
Training a code-switching (CS) language model using only monolingual data is still an ongoing research problem. In this paper, a CS language model is trained using only monolingual training data. As recurrent neural network (RNN) models are best suited for predicting sequential data. In this work, an RNN language model is trained using alternate batches from only monolingual English and Spanish data and the perplexity of the language model is computed. From the results, it is concluded that using alternate batches of monolingual data in training reduced the perplexity of a CS language model. The results were consistently improved using mean square error (MSE) in the output embeddings of RNN based language model. By combining both methods, perplexity is reduced from 299.63 to 80.38. The proposed methods were comparable to the language model fine tune with code-switch training data.