 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA reinforcement learning approach for VQA validation: an application to diabetic macular edema grading
Jul 19, 2023Recent advances in machine learning models have greatly increased the performance of automated methods in medical image analysis. However, the internal functioning of such models is largely hidden, which hinders their integration in clinical practice. Explainability and trust are viewed as important aspects of modern methods, for the latter's widespread use in clinical communities. As such, validation of machine learning models represents an important aspect and yet, most methods are only validated in a limited way. In this work, we focus on providing a richer and more appropriate validation approach for highly powerful Visual Question Answering (VQA) algorithms. To better understand the performance of these methods, which answer arbitrary questions related to images, this work focuses on an automatic visual Turing test (VTT). That is, we propose an automatic adaptive questioning method, that aims to expose the reasoning behavior of a VQA algorithm. Specifically, we introduce a reinforcement learning (RL) agent that observes the history of previously asked questions, and uses it to select the next question to pose. We demonstrate our approach in the context of evaluating algorithms that automatically answer questions related to diabetic macular edema (DME) grading. The experiments show that such an agent has similar behavior to a clinician, whereby asking questions that are relevant to key clinical concepts.
* 16 pages (+ 23 pages supplementary material)
Concept-Centric Visual Turing Tests for Method Validation
Jul 15, 2019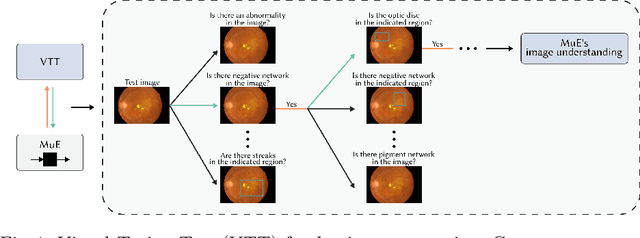
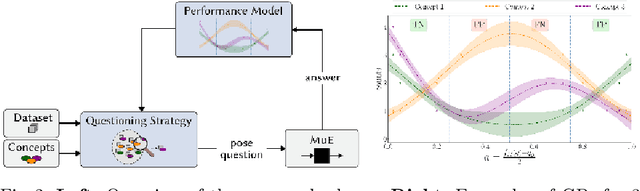
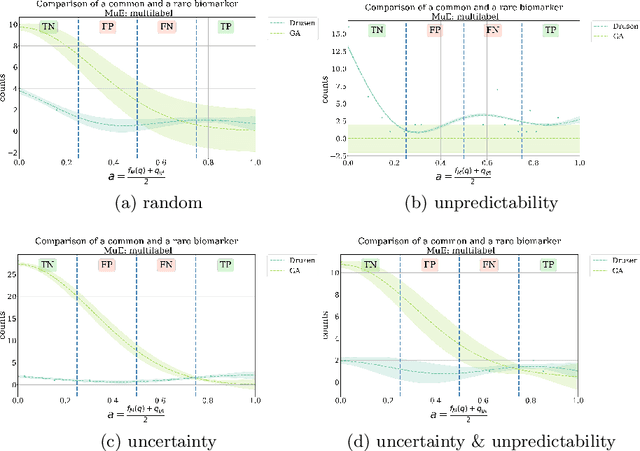
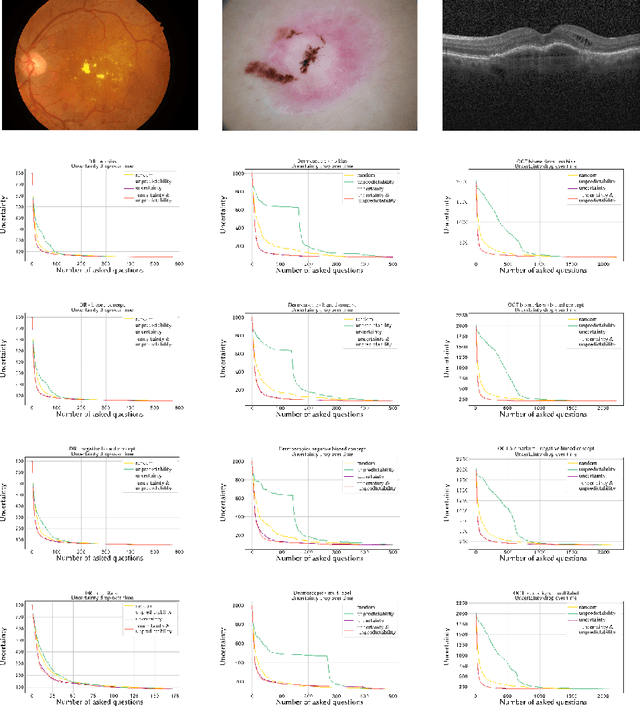
Recent advances in machine learning for medical imaging have led to impressive increases in model complexity and overall capabilities. However, the ability to discern the precise information a machine learning method is using to make decisions has lagged behind and it is often unclear how these performances are in fact achieved. Conventional evaluation metrics that reduce method performance to a single number or a curve only provide limited insights. Yet, systems used in clinical practice demand thorough validation that such crude characterizations miss. To this end, we present a framework to evaluate classification methods based on a number of interpretable concepts that are crucial for a clinical task. Our approach is inspired by the Turing Test concept and how to devise a test that adaptively questions a method for its ability to interpret medical images. To do this, we make use of a Twenty Questions paradigm whereby we use a probabilistic model to characterize the method's capacity to grasp task-specific concepts, and we introduce a strategy to sequentially query the method according to its previous answers. The results show that the probabilistic model is able to expose both the dataset's and the method's biases, and can be used to reduced the number of queries needed for confident performance evaluation.