 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECOM: A Validity Discrimination Tradeoff in Automatic Metrics for Open Ended Reddit Question Answering
Jun 17, 2026Automatic metrics are the default for evaluating LLM-generated text, yet a metric is quietly asked to do two jobs: tell genuine content alignment from surface coincidence (validity), and tell a better system from a worse one (discriminative power). On open-ended, opinion-driven question answering, the two are in tension. We introduce RECOM (Reddit Evaluation for Correspondence of Models), a contamination-free evaluation dataset of 15,000 r/AskReddit questions (September 2025), each paired with its authentic community replies, which postdate every evaluated model's training cutoff. Scoring five open-source LLMs (7--10B) against every reply each metric paired with a random-derangement noise floor we find that no metric does both jobs well. Cosine similarity separates real from random answers (Cohen's $d \approx 2$) but cannot rank the five models ($|d| < 0.1$); BERTScore precision appears to rank the models (raw $|d|$ up to 0.63), but once response length is controlled this collapses to $|d| = 0.09$ and its validity is weak ($d \approx 0.8$, versus cosine's $\approx 2$). Because every metric scores the same outputs, this validity--discrimination tradeoff is a property of the metrics, not the models, and we argue it stems from representation design. Three independent LLM judges reproduce the validity gap and likewise separate the five models only weakly. We recommend reporting metrics on both axes, with an explicit random-baseline floor. RECOM is publicly available at https://anonymous.4open.science/r/recom-D4B0
Semi-Supervised Cascaded Clustering for Classification of Noisy Label Data
May 04, 2022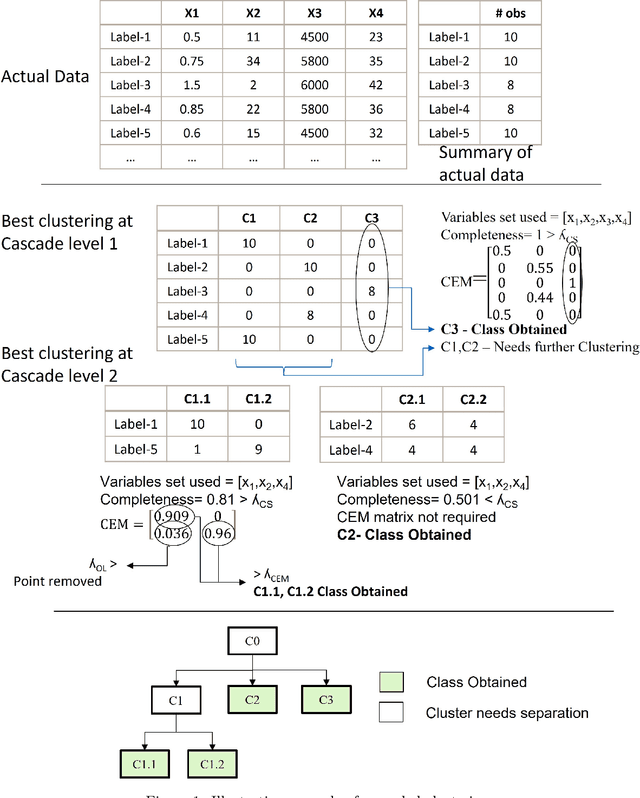
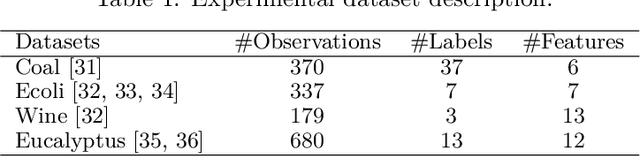

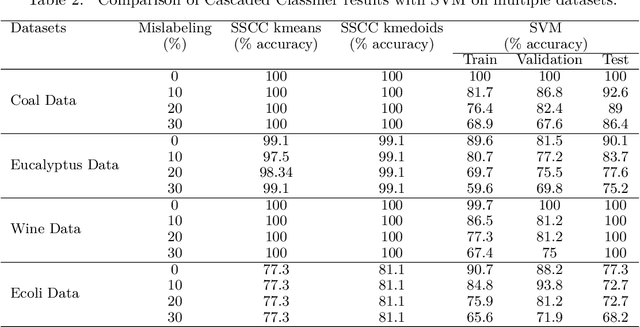
The performance of supervised classification techniques often deteriorates when the data has noisy labels. Even the semi-supervised classification approaches have largely focused only on the problem of handling missing labels. Most of the approaches addressing the noisy label data rely on deep neural networks (DNN) that require huge datasets for classification tasks. This poses a serious challenge especially in process and manufacturing industries, where the data is limited and labels are noisy. We propose a semi-supervised cascaded clustering (SSCC) algorithm to extract patterns and generate a cascaded tree of classes in such datasets. A novel cluster evaluation matrix (CEM) with configurable hyperparameters is introduced to localize and eliminate the noisy labels and invoke a pruning criterion on cascaded clustering. The algorithm reduces the dependency on expensive human expertise for assessing the accuracy of labels. A classifier generated based on SSCC is found to be accurate and consistent even when trained on noisy label datasets. It performed better in comparison with the support vector machines (SVM) when tested on multiple noisy-label datasets, including an industrial dataset. The proposed approach can be effectively used for deriving actionable insights in industrial settings with minimal human expertise.