 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustification of deep net classifiers by key based diversified aggregation with pre-filtering
May 14, 2019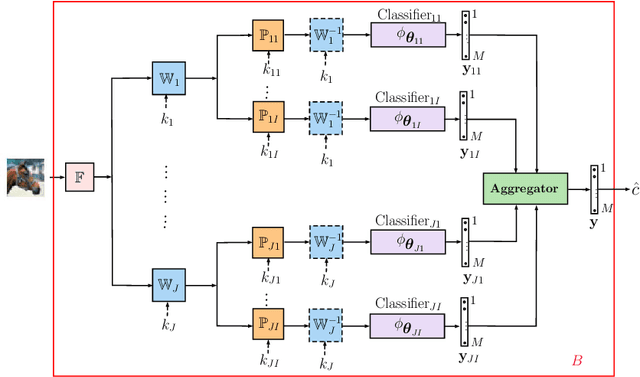
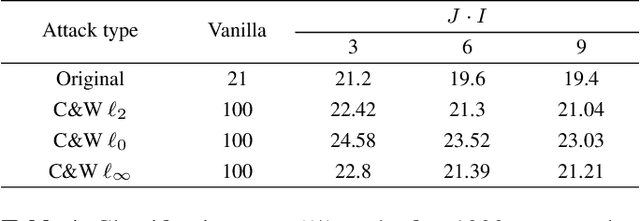

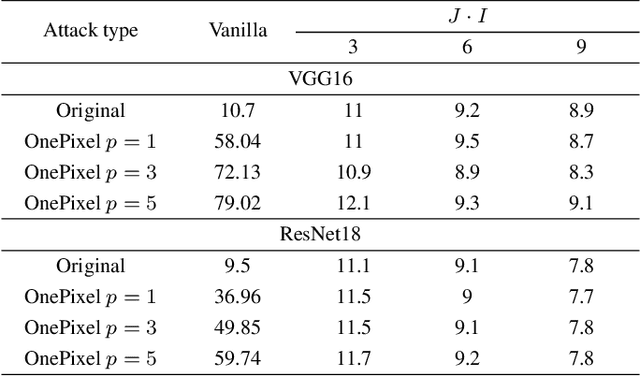
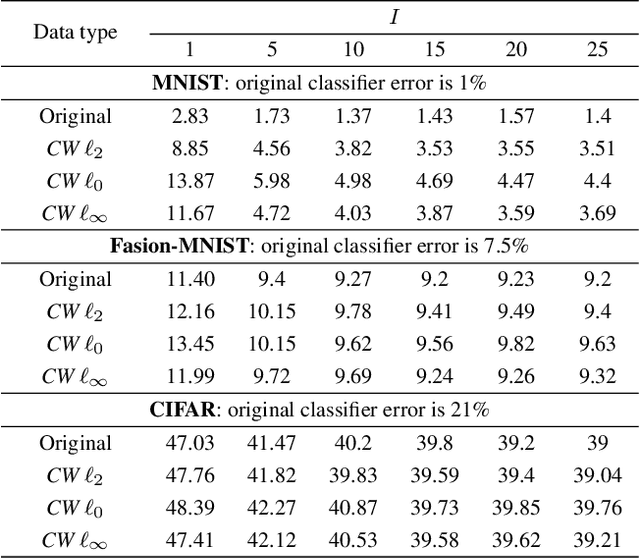
In this paper, we address a problem of machine learning system vulnerability to adversarial attacks. We propose and investigate a Key based Diversified Aggregation (KDA) mechanism as a defense strategy. The KDA assumes that the attacker (i) knows the architecture of classifier and the used defense strategy, (ii) has an access to the training data set but (iii) does not know the secret key. The robustness of the system is achieved by a specially designed key based randomization. The proposed randomization prevents the gradients' back propagation or the creating of a "bypass" system. The randomization is performed simultaneously in several channels and a multi-channel aggregation stabilizes the results of randomization by aggregating soft outputs from each classifier in multi-channel system. The performed experimental evaluation demonstrates a high robustness and universality of the KDA against the most efficient gradient based attacks like those proposed by N. Carlini and D. Wagner and the non-gradient based sparse adversarial perturbations like OnePixel attacks.
Reconstruction of Privacy-Sensitive Data from Protected Templates
May 08, 2019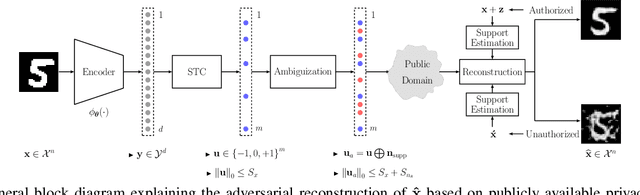
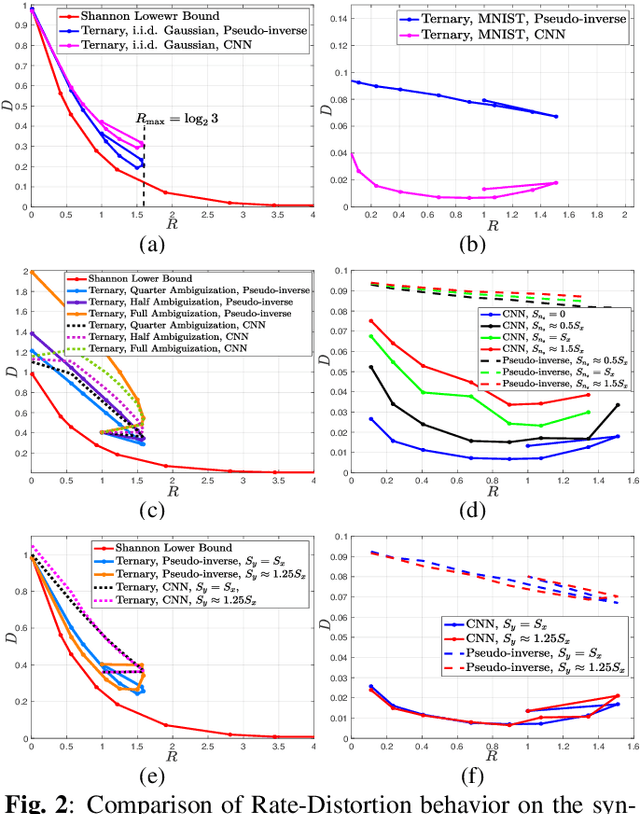

In this paper, we address the problem of data reconstruction from privacy-protected templates, based on recent concept of sparse ternary coding with ambiguization (STCA). The STCA is a generalization of randomization techniques which includes random projections, lossy quantization, and addition of ambiguization noise to satisfy the privacy-utility trade-off requirements. The theoretical privacy-preserving properties of STCA have been validated on synthetic data. However, the applicability of STCA to real data and potential threats linked to reconstruction based on recent deep reconstruction algorithms are still open problems. Our results demonstrate that STCA still achieves the claimed theoretical performance when facing deep reconstruction attacks for the synthetic i.i.d. data, while for real images special measures are required to guarantee proper protection of the templates.
Defending against adversarial attacks by randomized diversification
Apr 01, 2019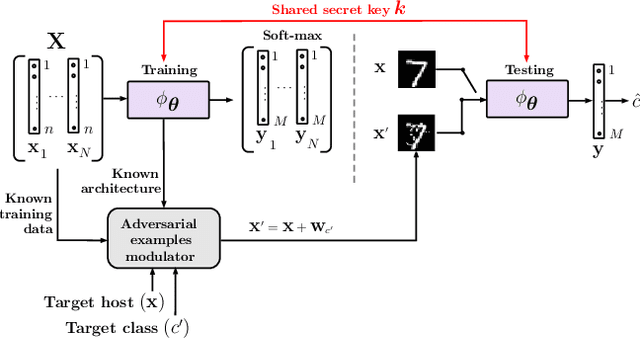
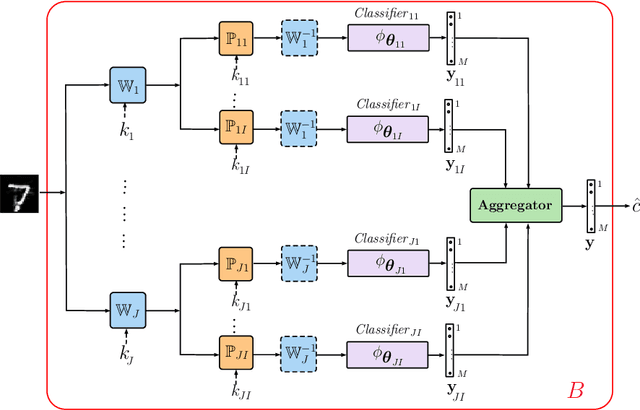
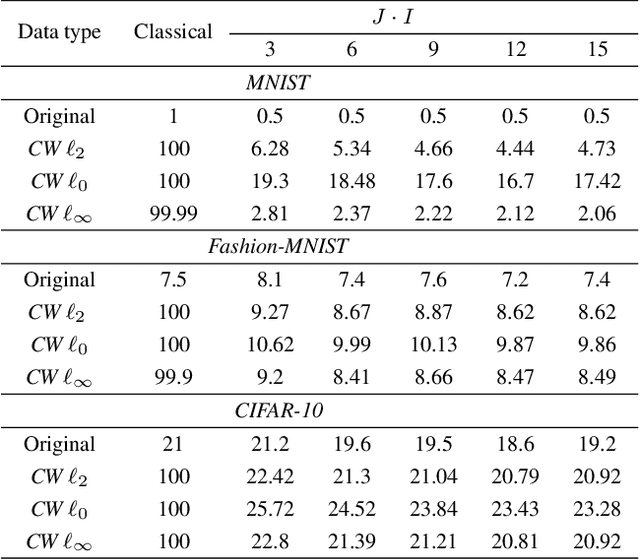
The vulnerability of machine learning systems to adversarial attacks questions their usage in many applications. In this paper, we propose a randomized diversification as a defense strategy. We introduce a multi-channel architecture in a gray-box scenario, which assumes that the architecture of the classifier and the training data set are known to the attacker. The attacker does not only have access to a secret key and to the internal states of the system at the test time. The defender processes an input in multiple channels. Each channel introduces its own randomization in a special transform domain based on a secret key shared between the training and testing stages. Such a transform based randomization with a shared key preserves the gradients in key-defined sub-spaces for the defender but it prevents gradient back propagation and the creation of various bypass systems for the attacker. An additional benefit of multi-channel randomization is the aggregation that fuses soft-outputs from all channels, thus increasing the reliability of the final score. The sharing of a secret key creates an information advantage to the defender. Experimental evaluation demonstrates an increased robustness of the proposed method to a number of known state-of-the-art attacks.
Clustering with Jointly Learned Nonlinear Transforms Over Discriminating Min-Max Similarity/Dissimilarity Assignment
Jan 30, 2019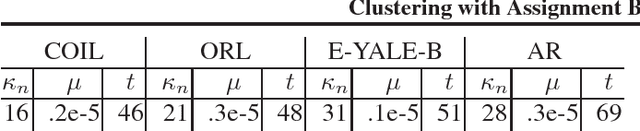
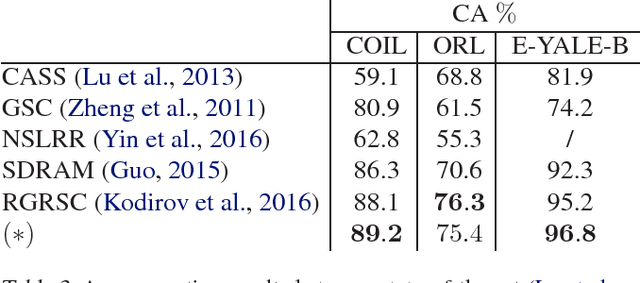
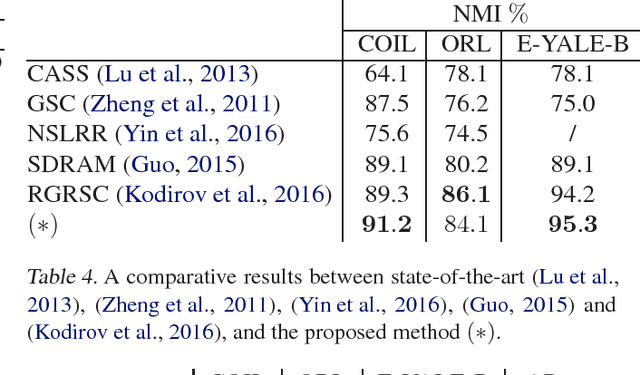
This paper presents a novel clustering concept that is based on jointly learned nonlinear transforms (NTs) with priors on the information loss and the discrimination. We introduce a clustering principle that is based on evaluation of a parametric min-max measure for the discriminative prior. The decomposition of the prior measure allows to break down the assignment into two steps. In the first step, we apply NTs to a data point in order to produce candidate NT representations. In the second step, we preform the actual assignment by evaluating the parametric measure over the candidate NT representations. Numerical experiments on image clustering task validate the potential of the proposed approach. The evaluation shows advantages in comparison to the state-of-the-art clustering methods.
Sparse Ternary Codes for similarity search have higher coding gain than dense binary codes
Apr 25, 2017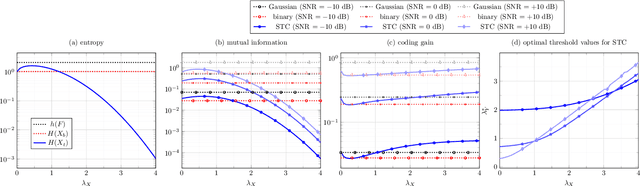
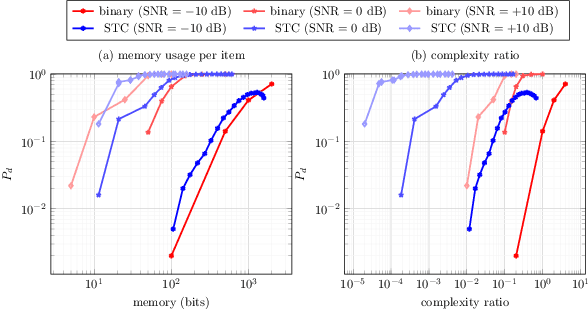
This paper addresses the problem of Approximate Nearest Neighbor (ANN) search in pattern recognition where feature vectors in a database are encoded as compact codes in order to speed-up the similarity search in large-scale databases. Considering the ANN problem from an information-theoretic perspective, we interpret it as an encoding, which maps the original feature vectors to a less entropic sparse representation while requiring them to be as informative as possible. We then define the coding gain for ANN search using information-theoretic measures. We next show that the classical approach to this problem, which consists of binarization of the projected vectors is sub-optimal. Instead, a properly designed ternary encoding achieves higher coding gains and lower complexity.