 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-uniformity is All You Need: Efficient and Timely Encrypted Traffic Classification With ECHO
Jun 03, 2024



With 95% of Internet traffic now encrypted, an effective approach to classifying this traffic is crucial for network security and management. This paper introduces ECHO -- a novel optimization process for ML/DL-based encrypted traffic classification. ECHO targets both classification time and memory utilization and incorporates two innovative techniques. The first component, HO (Hyperparameter Optimization of binnings), aims at creating efficient traffic representations. While previous research often uses representations that map packet sizes and packet arrival times to fixed-sized bins, we show that non-uniform binnings are significantly more efficient. These non-uniform binnings are derived by employing a hyperparameter optimization algorithm in the training stage. HO significantly improves accuracy given a required representation size, or, equivalently, achieves comparable accuracy using smaller representations. Then, we introduce EC (Early Classification of traffic), which enables faster classification using a cascade of classifiers adapted for different exit times, where classification is based on the level of confidence. EC reduces the average classification latency by up to 90\%. Remarkably, this method not only maintains classification accuracy but also, in certain cases, improves it. Using three publicly available datasets, we demonstrate that the combined method, Early Classification with Hyperparameter Optimization (ECHO), leads to a significant improvement in classification efficiency.
Unveiling Hidden Links Between Unseen Security Entities
Mar 04, 2024The proliferation of software vulnerabilities poses a significant challenge for security databases and analysts tasked with their timely identification, classification, and remediation. With the National Vulnerability Database (NVD) reporting an ever-increasing number of vulnerabilities, the traditional manual analysis becomes untenably time-consuming and prone to errors. This paper introduces VulnScopper, an innovative approach that utilizes multi-modal representation learning, combining Knowledge Graphs (KG) and Natural Language Processing (NLP), to automate and enhance the analysis of software vulnerabilities. Leveraging ULTRA, a knowledge graph foundation model, combined with a Large Language Model (LLM), VulnScopper effectively handles unseen entities, overcoming the limitations of previous KG approaches. We evaluate VulnScopper on two major security datasets, the NVD and the Red Hat CVE database. Our method significantly improves the link prediction accuracy between Common Vulnerabilities and Exposures (CVEs), Common Weakness Enumeration (CWEs), and Common Platform Enumerations (CPEs). Our results show that VulnScopper outperforms existing methods, achieving up to 78% Hits@10 accuracy in linking CVEs to CPEs and CWEs and presenting an 11.7% improvement over large language models in predicting CWE labels based on the Red Hat database. Based on the NVD, only 6.37% of the linked CPEs are being published during the first 30 days; many of them are related to critical and high-risk vulnerabilities which, according to multiple compliance frameworks (such as CISA and PCI), should be remediated within 15-30 days. Our model can uncover new products linked to vulnerabilities, reducing remediation time and improving vulnerability management. We analyzed several CVEs from 2023 to showcase this ability.
Efficient Data-Dependent Learnability
Nov 20, 2020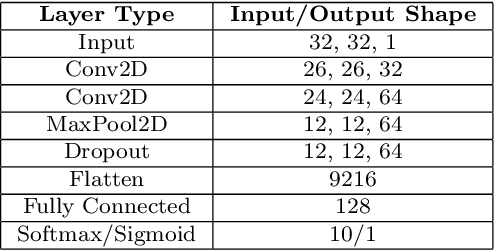
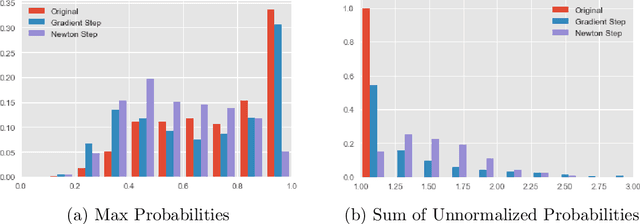
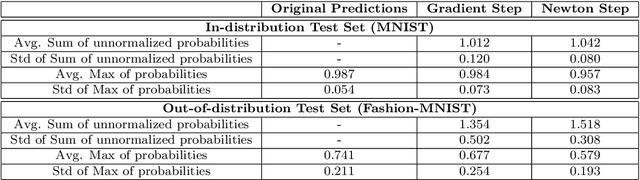
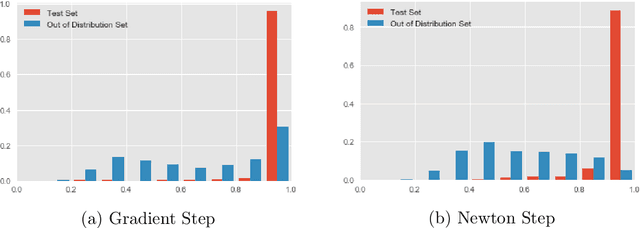
The predictive normalized maximum likelihood (pNML) approach has recently been proposed as the min-max optimal solution to the batch learning problem where both the training set and the test data feature are individuals, known sequences. This approach has yields a learnability measure that can also be interpreted as a stability measure. This measure has shown some potential in detecting out-of-distribution examples, yet it has considerable computational costs. In this project, we propose and analyze an approximation of the pNML, which is based on influence functions. Combining both theoretical analysis and experiments, we show that when applied to neural networks, this approximation can detect out-of-distribution examples effectively. We also compare its performance to that achieved by conducting a single gradient step for each possible label.