 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Cross-Domain Word Representation Learning
May 27, 2015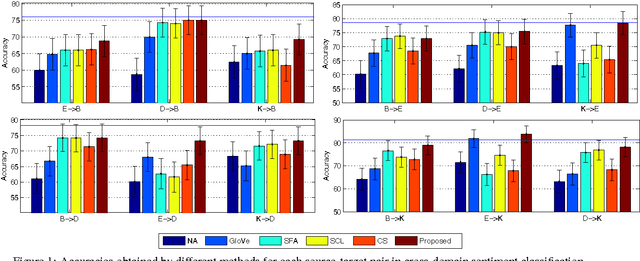
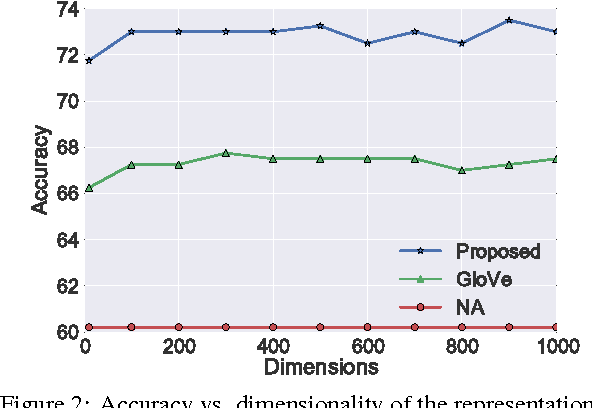
Meaning of a word varies from one domain to another. Despite this important domain dependence in word semantics, existing word representation learning methods are bound to a single domain. Given a pair of \emph{source}-\emph{target} domains, we propose an unsupervised method for learning domain-specific word representations that accurately capture the domain-specific aspects of word semantics. First, we select a subset of frequent words that occur in both domains as \emph{pivots}. Next, we optimize an objective function that enforces two constraints: (a) for both source and target domain documents, pivots that appear in a document must accurately predict the co-occurring non-pivots, and (b) word representations learnt for pivots must be similar in the two domains. Moreover, we propose a method to perform domain adaptation using the learnt word representations. Our proposed method significantly outperforms competitive baselines including the state-of-the-art domain-insensitive word representations, and reports best sentiment classification accuracies for all domain-pairs in a benchmark dataset.
Embedding Semantic Relations into Word Representations
May 01, 2015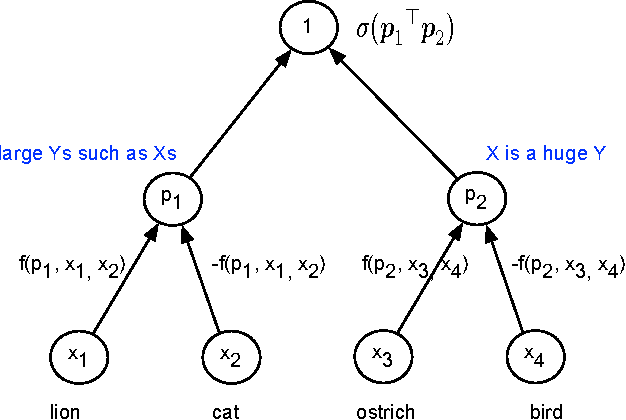
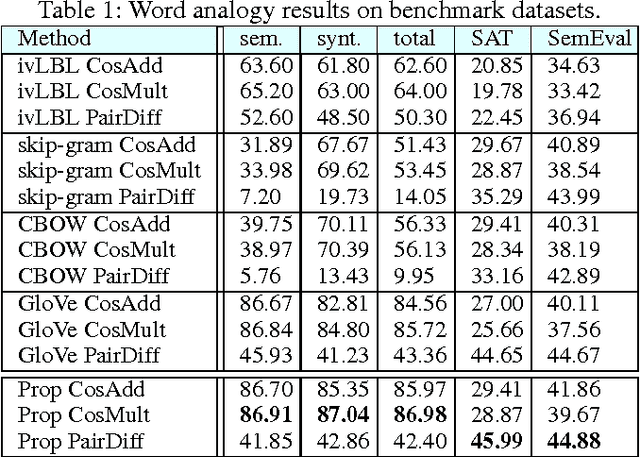
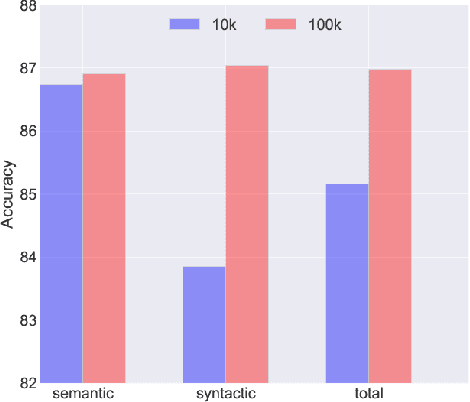
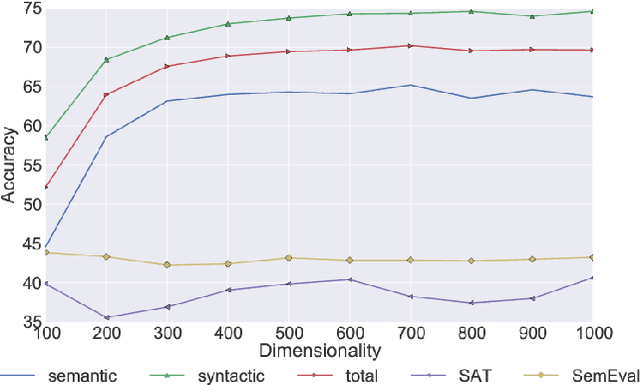
Learning representations for semantic relations is important for various tasks such as analogy detection, relational search, and relation classification. Although there have been several proposals for learning representations for individual words, learning word representations that explicitly capture the semantic relations between words remains under developed. We propose an unsupervised method for learning vector representations for words such that the learnt representations are sensitive to the semantic relations that exist between two words. First, we extract lexical patterns from the co-occurrence contexts of two words in a corpus to represent the semantic relations that exist between those two words. Second, we represent a lexical pattern as the weighted sum of the representations of the words that co-occur with that lexical pattern. Third, we train a binary classifier to detect relationally similar vs. non-similar lexical pattern pairs. The proposed method is unsupervised in the sense that the lexical pattern pairs we use as train data are automatically sampled from a corpus, without requiring any manual intervention. Our proposed method statistically significantly outperforms the current state-of-the-art word representations on three benchmark datasets for proportional analogy detection, demonstrating its ability to accurately capture the semantic relations among words.
Learning Word Representations from Relational Graphs
Dec 07, 2014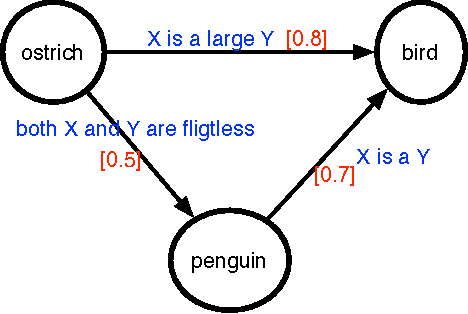
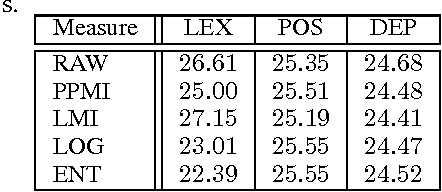
Attributes of words and relations between two words are central to numerous tasks in Artificial Intelligence such as knowledge representation, similarity measurement, and analogy detection. Often when two words share one or more attributes in common, they are connected by some semantic relations. On the other hand, if there are numerous semantic relations between two words, we can expect some of the attributes of one of the words to be inherited by the other. Motivated by this close connection between attributes and relations, given a relational graph in which words are inter- connected via numerous semantic relations, we propose a method to learn a latent representation for the individual words. The proposed method considers not only the co-occurrences of words as done by existing approaches for word representation learning, but also the semantic relations in which two words co-occur. To evaluate the accuracy of the word representations learnt using the proposed method, we use the learnt word representations to solve semantic word analogy problems. Our experimental results show that it is possible to learn better word representations by using semantic semantics between words.