 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Traffic of MANETs using Graph Neural Networks
Dec 17, 2022Graph Neural Networks (GNNs) have been taking role in many areas, thanks to their expressive power on graph-structured data. On the other hand, Mobile Ad-Hoc Networks (MANETs) are gaining attention as network technologies have been taken to the 5G level. However, there is no study that evaluates the efficiency of GNNs on MANETs. In this study, we aim to fill this absence by implementing a MANET dataset in a popular GNN framework, i.e., PyTorch Geometric; and show how GNNs can be utilized to analyze the traffic of MANETs. We operate an edge prediction task on the dataset with GraphSAGE (SAG) model, where SAG model tries to predict whether there is a link between two nodes. We construe several evaluation metrics to measure the performance and efficiency of GNNs on MANETs. SAG model showed 82.1 accuracy on average in the experiments.
Benchmarking Apache Spark and Hadoop MapReduce on Big Data Classification
Sep 21, 2022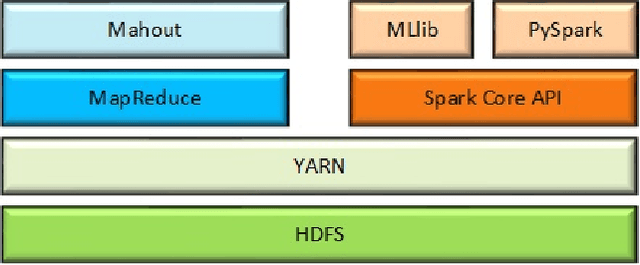
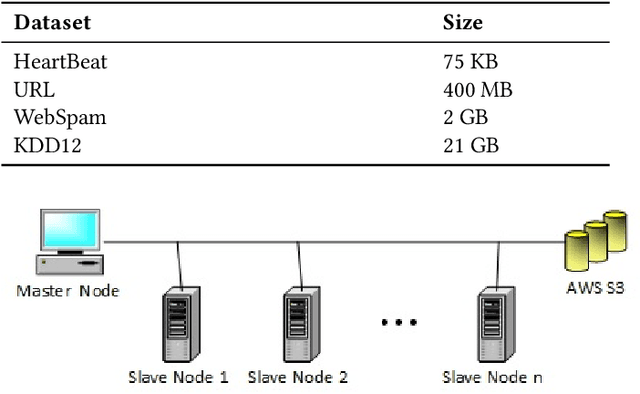
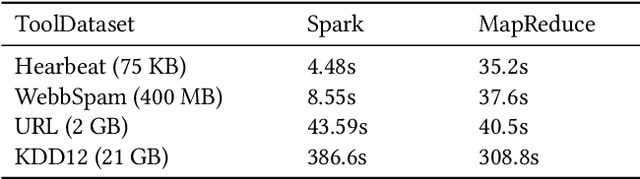
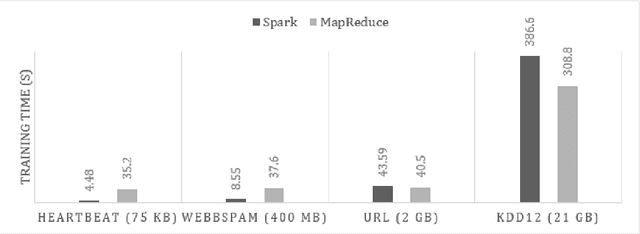
Most of the popular Big Data analytics tools evolved to adapt their working environment to extract valuable information from a vast amount of unstructured data. The ability of data mining techniques to filter this helpful information from Big Data led to the term Big Data Mining. Shifting the scope of data from small-size, structured, and stable data to huge volume, unstructured, and quickly changing data brings many data management challenges. Different tools cope with these challenges in their own way due to their architectural limitations. There are numerous parameters to take into consideration when choosing the right data management framework based on the task at hand. In this paper, we present a comprehensive benchmark for two widely used Big Data analytics tools, namely Apache Spark and Hadoop MapReduce, on a common data mining task, i.e., classification. We employ several evaluation metrics to compare the performance of the benchmarked frameworks, such as execution time, accuracy, and scalability. These metrics are specialized to measure the performance for classification task. To the best of our knowledge, there is no previous study in the literature that employs all these metrics while taking into consideration task-specific concerns. We show that Spark is 5 times faster than MapReduce on training the model. Nevertheless, the performance of Spark degrades when the input workload gets larger. Scaling the environment by additional clusters significantly improves the performance of Spark. However, similar enhancement is not observed in Hadoop. Machine learning utility of MapReduce tend to have better accuracy scores than that of Spark, like around 3%, even in small size data sets.
* 2021 5th International Conference on Cloud and Big Data Computing (ICCBDC 2021)