 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatMMFuse: Multi-Modal Fusion model for Material Property Prediction
Apr 30, 2025

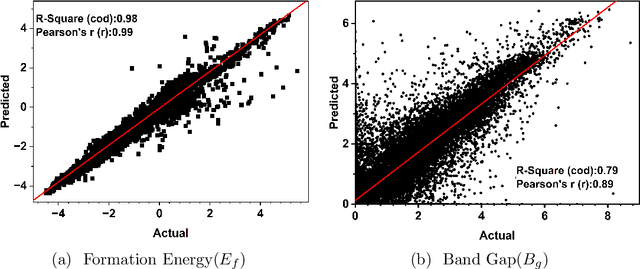
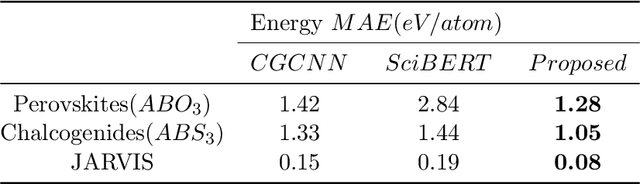
The recent progress of using graph based encoding of crystal structures for high throughput material property prediction has been quite successful. However, using a single modality model prevents us from exploiting the advantages of an enhanced features space by combining different representations. Specifically, pre-trained Large language models(LLMs) can encode a large amount of knowledge which is beneficial for training of models. Moreover, the graph encoder is able to learn the local features while the text encoder is able to learn global information such as space group and crystal symmetry. In this work, we propose Material Multi-Modal Fusion(MatMMFuse), a fusion based model which uses a multi-head attention mechanism for the combination of structure aware embedding from the Crystal Graph Convolution Network (CGCNN) and text embeddings from the SciBERT model. We train our model in an end-to-end framework using data from the Materials Project Dataset. We show that our proposed model shows an improvement compared to the vanilla CGCNN and SciBERT model for all four key properties: formation energy, band gap, energy above hull and fermi energy. Specifically, we observe an improvement of 40% compared to the vanilla CGCNN model and 68% compared to the SciBERT model for predicting the formation energy per atom. Importantly, we demonstrate the zero shot performance of the trained model on small curated datasets of Perovskites, Chalcogenides and the Jarvis Dataset. The results show that the proposed model exhibits better zero shot performance than the individual plain vanilla CGCNN and SciBERT model. This enables researchers to deploy the model for specialized industrial applications where collection of training data is prohibitively expensive.
Heart rate measurement using the built-in triaxial accelerometer from a commercial digital writing device
Sep 25, 2023Wearable devices are on the rise. Smart watches and phones, fitness trackers or smart textiles now provide unprecedented access to our own personal data. As such, wearable devices can enable health monitoring without disrupting our daily routines. In clinical settings, electrocardiograms (ECGs) and photoplethysmographies (PPGs) are used to monitor the heart's and respiratory behaviors. In more practical settings, accelerometers can be used to estimate the heartrate when they are attached to the chest. They can also help filter out some noise in ECG signal from movement. In this work, we compare the heart rate data extracted from the built-in accelerometer of a commercial smart pen equipped with sensors (STABILO's DigiPen), with a standard ECG monitor readouts. We demonstrate that it is possible to accurately predict the heart rate from the smart pencil. The data collection is done with eight volunteers, writing the alphabet continuously for five minutes. The signal is processed with a Butterworth filter to cut off noise. We achieve a mean-squared error (MSE) better than 6.685x10$^{-3}$ comparing the DigiPen's computed ${\Delta}$t (time between pulses) with the reference ECG data. The peaks' timestamps for both signals all maintain a correlation higher than 0.99. All computed heart rates from the pen accurately correlate with the reference ECG signals.
Multidimensional analysis using sensor arrays with deep learning for high-precision and high-accuracy diagnosis
Dec 06, 2022In the upcoming years, artificial intelligence (AI) is going to transform the practice of medicine in most of its specialties. Deep learning can help achieve better and earlier problem detection, while reducing errors on diagnosis. By feeding a deep neural network (DNN) with the data from a low-cost and low-accuracy sensor array, we demonstrate that it becomes possible to significantly improve the measurements' precision and accuracy. The data collection is done with an array composed of 32 temperature sensors, including 16 analog and 16 digital sensors. All sensors have accuracies between 0.5-2.0$^\circ$C. 800 vectors are extracted, covering a range from to 30 to 45$^\circ$C. In order to improve the temperature readings, we use machine learning to perform a linear regression analysis through a DNN. In an attempt to minimize the model's complexity in order to eventually run inferences locally, the network with the best results involves only three layers using the hyperbolic tangent activation function and the Adam Stochastic Gradient Descent (SGD) optimizer. The model is trained with a randomly-selected dataset using 640 vectors (80% of the data) and tested with 160 vectors (20%). Using the mean squared error as a loss function between the data and the model's prediction, we achieve a loss of only 1.47x10$^{-4}$ on the training set and 1.22x10$^{-4}$ on the test set. As such, we believe this appealing approach offers a new pathway towards significantly better datasets using readily-available ultra low-cost sensors.