 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Potential Topics In News Using BERT, CRF and Wikipedia
Feb 28, 2020
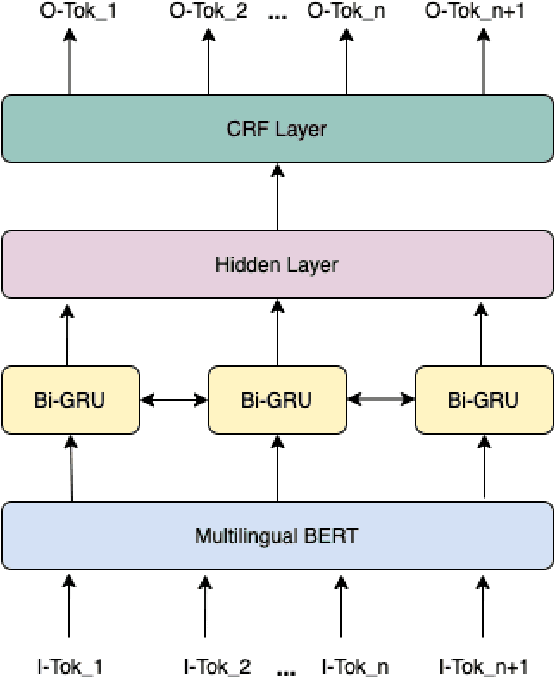
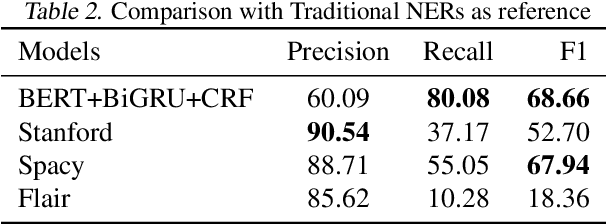
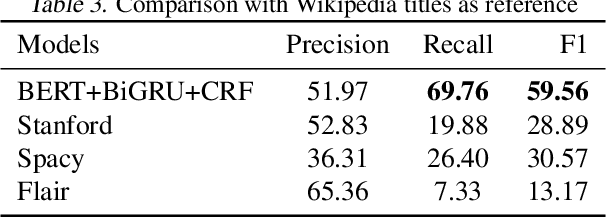
For a news content distribution platform like Dailyhunt, Named Entity Recognition is a pivotal task for building better user recommendation and notification algorithms. Apart from identifying names, locations, organisations from the news for 13+ Indian languages and use them in algorithms, we also need to identify n-grams which do not necessarily fit in the definition of Named-Entity, yet they are important. For example, "me too movement", "beef ban", "alwar mob lynching". In this exercise, given an English language text, we are trying to detect case-less n-grams which convey important information and can be used as topics and/or hashtags for a news. Model is built using Wikipedia titles data, private English news corpus and BERT-Multilingual pre-trained model, Bi-GRU and CRF architecture. It shows promising results when compared with industry best Flair, Spacy and Stanford-caseless-NER in terms of F1 and especially Recall.
Marathi To English Neural Machine Translation With Near Perfect Corpus And Transformers
Feb 26, 2020
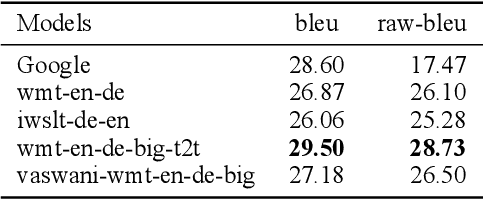
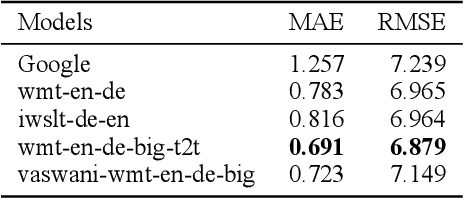

There have been very few attempts to benchmark performances of state-of-the-art algorithms for Neural Machine Translation task on Indian Languages. Google, Bing, Facebook and Yandex are some of the very few companies which have built translation systems for few of the Indian Languages. Among them, translation results from Google are supposed to be better, based on general inspection. Bing-Translator do not even support Marathi language which has around 95 million speakers and ranks 15th in the world in terms of combined primary and secondary speakers. In this exercise, we trained and compared variety of Neural Machine Marathi to English Translators trained with BERT-tokenizer by huggingface and various Transformer based architectures using Facebook's Fairseq platform with limited but almost correct parallel corpus to achieve better BLEU scores than Google on Tatoeba and Wikimedia open datasets.