 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCare: A Deep Dynamic Memory Model for Predictive Medicine
Apr 10, 2017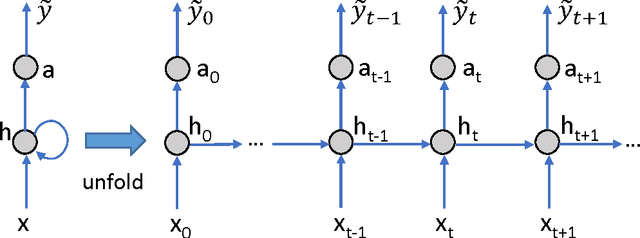
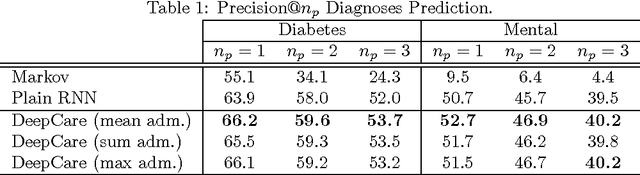
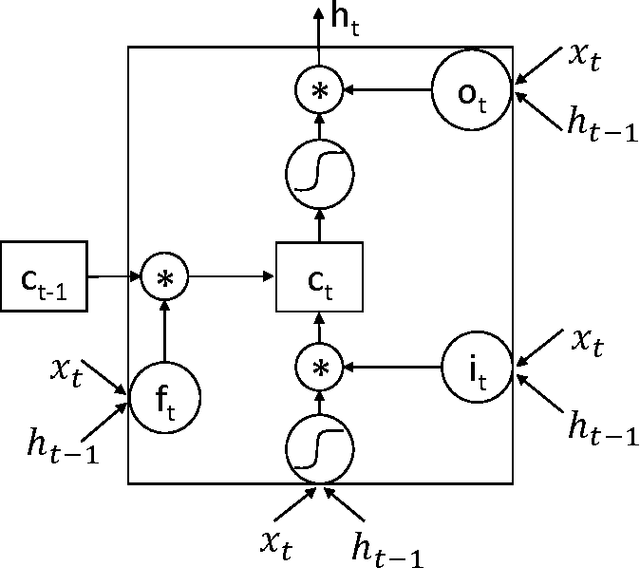
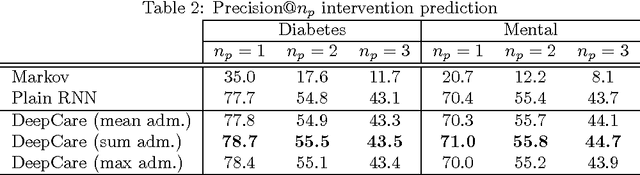
Personalized predictive medicine necessitates the modeling of patient illness and care processes, which inherently have long-term temporal dependencies. Healthcare observations, recorded in electronic medical records, are episodic and irregular in time. We introduce DeepCare, an end-to-end deep dynamic neural network that reads medical records, stores previous illness history, infers current illness states and predicts future medical outcomes. At the data level, DeepCare represents care episodes as vectors in space, models patient health state trajectories through explicit memory of historical records. Built on Long Short-Term Memory (LSTM), DeepCare introduces time parameterizations to handle irregular timed events by moderating the forgetting and consolidation of memory cells. DeepCare also incorporates medical interventions that change the course of illness and shape future medical risk. Moving up to the health state level, historical and present health states are then aggregated through multiscale temporal pooling, before passing through a neural network that estimates future outcomes. We demonstrate the efficacy of DeepCare for disease progression modeling, intervention recommendation, and future risk prediction. On two important cohorts with heavy social and economic burden -- diabetes and mental health -- the results show improved modeling and risk prediction accuracy.
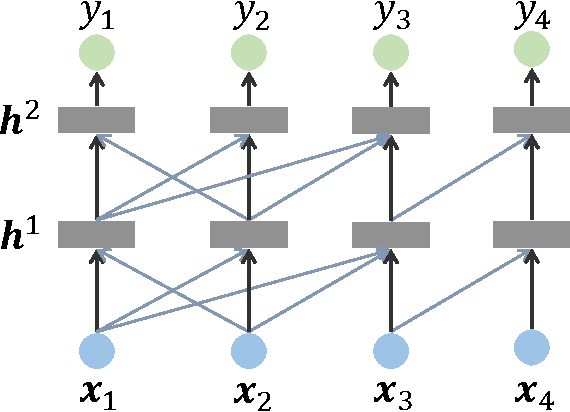
One Size Fits Many: Column Bundle for Multi-X Learning
Mar 14, 2017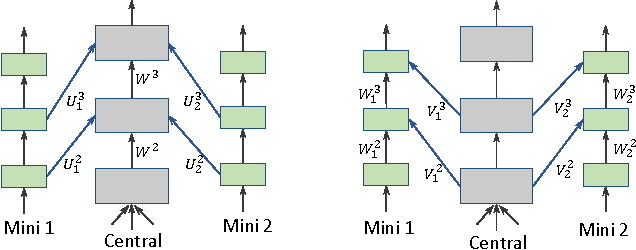
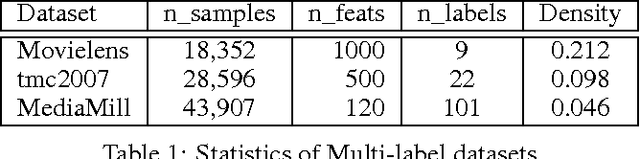
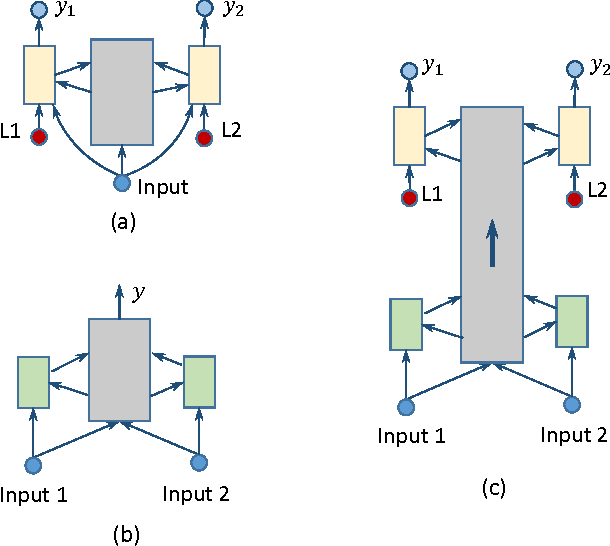
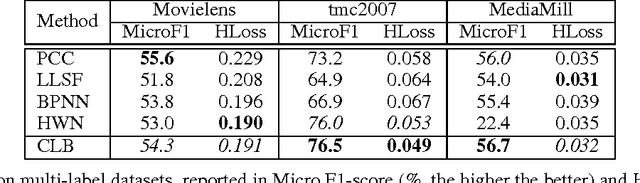
Much recent machine learning research has been directed towards leveraging shared statistics among labels, instances and data views, commonly referred to as multi-label, multi-instance and multi-view learning. The underlying premises are that there exist correlations among input parts and among output targets, and the predictive performance would increase when the correlations are incorporated. In this paper, we propose Column Bundle (CLB), a novel deep neural network for capturing the shared statistics in data. CLB is generic that the same architecture can be applied for various types of shared statistics by changing only input and output handling. CLB is capable of scaling to thousands of input parts and output labels by avoiding explicit modeling of pairwise relations. We evaluate CLB on different types of data: (a) multi-label, (b) multi-view, (c) multi-view/multi-label and (d) multi-instance. CLB demonstrates a comparable and competitive performance in all datasets against state-of-the-art methods designed specifically for each type.
Control Matching via Discharge Code Sequences
Dec 02, 2016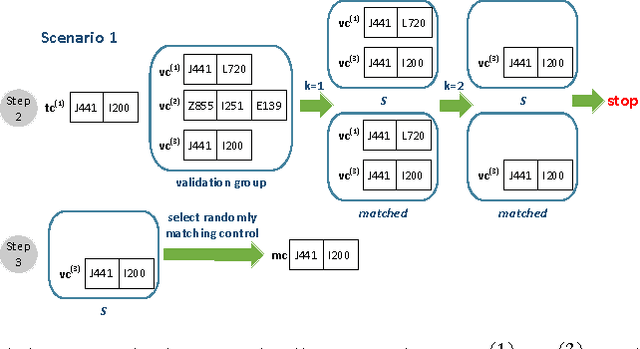
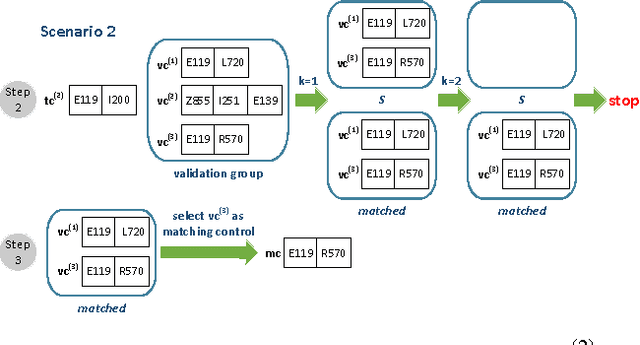
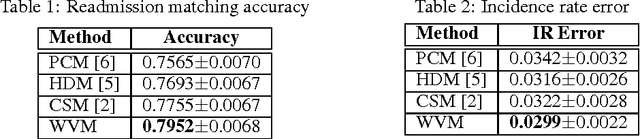
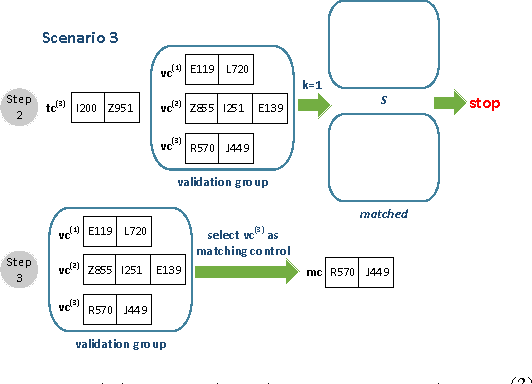
In this paper, we consider the patient similarity matching problem over a cancer cohort of more than 220,000 patients. Our approach first leverages on Word2Vec framework to embed ICD codes into vector-valued representation. We then propose a sequential algorithm for case-control matching on this representation space of diagnosis codes. The novel practice of applying the sequential matching on the vector representation lifted the matching accuracy measured through multiple clinical outcomes. We reported the results on a large-scale dataset to demonstrate the effectiveness of our method. For such a large dataset where most clinical information has been codified, the new method is particularly relevant.
Column Networks for Collective Classification
Nov 29, 2016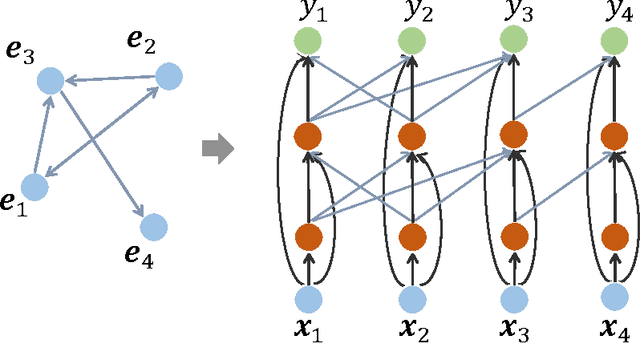

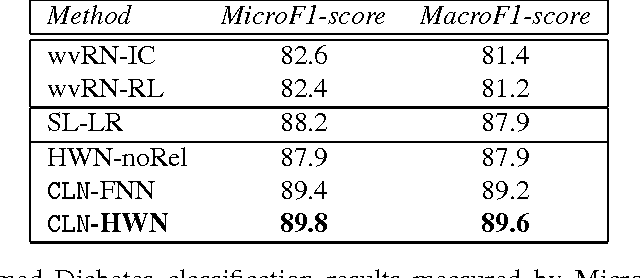
Relational learning deals with data that are characterized by relational structures. An important task is collective classification, which is to jointly classify networked objects. While it holds a great promise to produce a better accuracy than non-collective classifiers, collective classification is computational challenging and has not leveraged on the recent breakthroughs of deep learning. We present Column Network (CLN), a novel deep learning model for collective classification in multi-relational domains. CLN has many desirable theoretical properties: (i) it encodes multi-relations between any two instances; (ii) it is deep and compact, allowing complex functions to be approximated at the network level with a small set of free parameters; (iii) local and relational features are learned simultaneously; (iv) long-range, higher-order dependencies between instances are supported naturally; and (v) crucially, learning and inference are efficient, linear in the size of the network and the number of relations. We evaluate CLN on multiple real-world applications: (a) delay prediction in software projects, (b) PubMed Diabetes publication classification and (c) film genre classification. In all applications, CLN demonstrates a higher accuracy than state-of-the-art rivals.
Multilevel Anomaly Detection for Mixed Data
Oct 20, 2016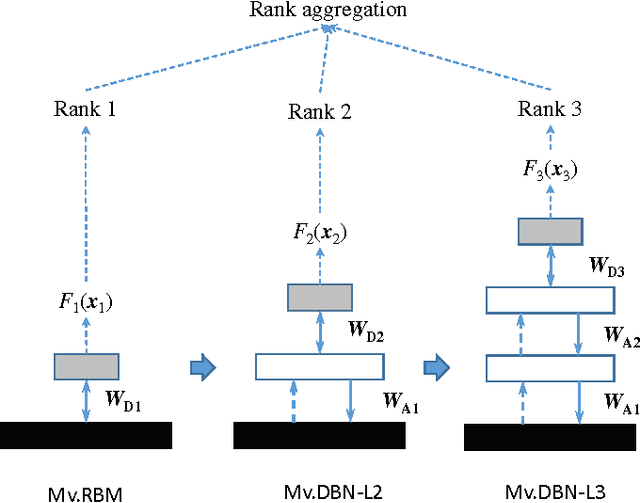
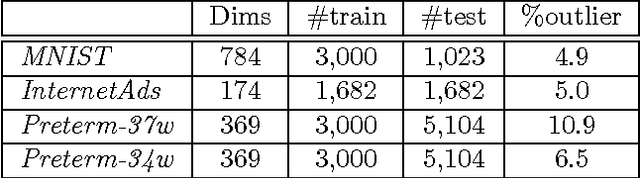


Anomalies are those deviating from the norm. Unsupervised anomaly detection often translates to identifying low density regions. Major problems arise when data is high-dimensional and mixed of discrete and continuous attributes. We propose MIXMAD, which stands for MIXed data Multilevel Anomaly Detection, an ensemble method that estimates the sparse regions across multiple levels of abstraction of mixed data. The hypothesis is for domains where multiple data abstractions exist, a data point may be anomalous with respect to the raw representation or more abstract representations. To this end, our method sequentially constructs an ensemble of Deep Belief Nets (DBNs) with varying depths. Each DBN is an energy-based detector at a predefined abstraction level. At the bottom level of each DBN, there is a Mixed-variate Restricted Boltzmann Machine that models the density of mixed data. Predictions across the ensemble are finally combined via rank aggregation. The proposed MIXMAD is evaluated on high-dimensional realworld datasets of different characteristics. The results demonstrate that for anomaly detection, (a) multilevel abstraction of high-dimensional and mixed data is a sensible strategy, and (b) empirically, MIXMAD is superior to popular unsupervised detection methods for both homogeneous and mixed data.
Stabilizing Linear Prediction Models using Autoencoder
Sep 28, 2016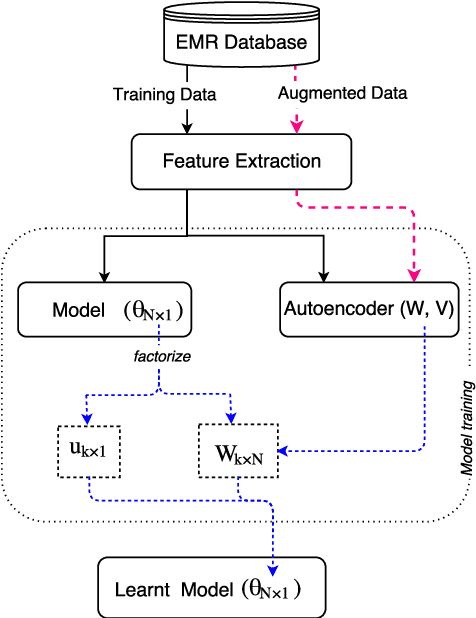
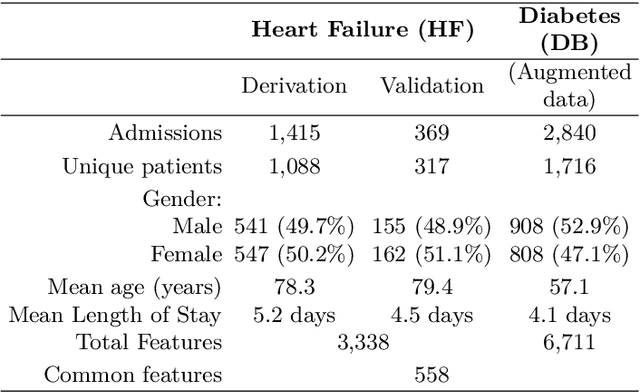
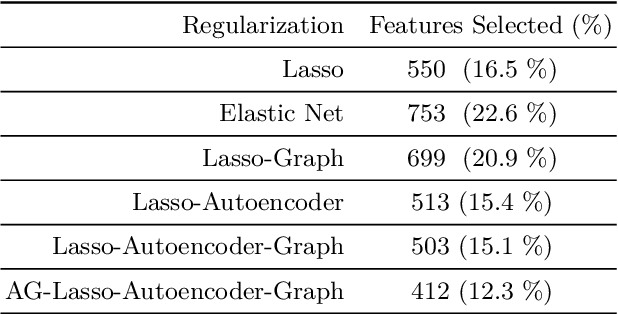
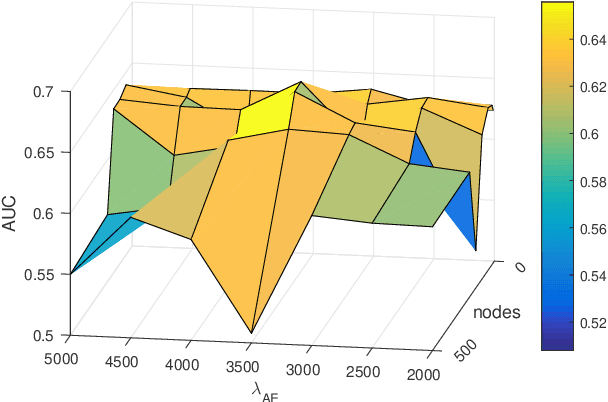
To date, the instability of prognostic predictors in a sparse high dimensional model, which hinders their clinical adoption, has received little attention. Stable prediction is often overlooked in favour of performance. Yet, stability prevails as key when adopting models in critical areas as healthcare. Our study proposes a stabilization scheme by detecting higher order feature correlations. Using a linear model as basis for prediction, we achieve feature stability by regularising latent correlation in features. Latent higher order correlation among features is modelled using an autoencoder network. Stability is enhanced by combining a recent technique that uses a feature graph, and augmenting external unlabelled data for training the autoencoder network. Our experiments are conducted on a heart failure cohort from an Australian hospital. Stability was measured using Consistency index for feature subsets and signal-to-noise ratio for model parameters. Our methods demonstrated significant improvement in feature stability and model estimation stability when compared to baselines.
Outlier Detection on Mixed-Type Data: An Energy-based Approach
Aug 17, 2016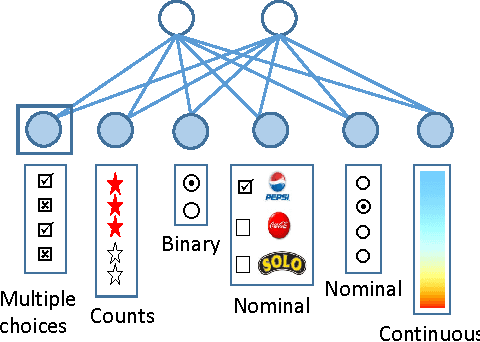
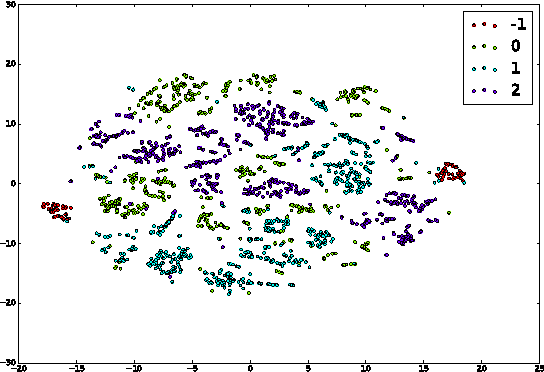
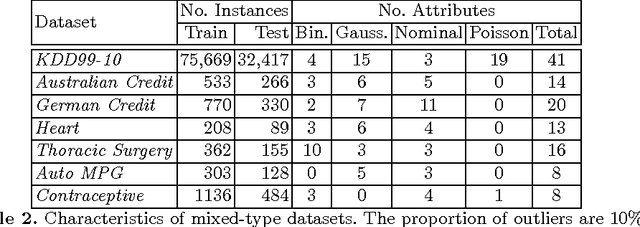
Outlier detection amounts to finding data points that differ significantly from the norm. Classic outlier detection methods are largely designed for single data type such as continuous or discrete. However, real world data is increasingly heterogeneous, where a data point can have both discrete and continuous attributes. Handling mixed-type data in a disciplined way remains a great challenge. In this paper, we propose a new unsupervised outlier detection method for mixed-type data based on Mixed-variate Restricted Boltzmann Machine (Mv.RBM). The Mv.RBM is a principled probabilistic method that models data density. We propose to use \emph{free-energy} derived from Mv.RBM as outlier score to detect outliers as those data points lying in low density regions. The method is fast to learn and compute, is scalable to massive datasets. At the same time, the outlier score is identical to data negative log-density up-to an additive constant. We evaluate the proposed method on synthetic and real-world datasets and demonstrate that (a) a proper handling mixed-types is necessary in outlier detection, and (b) free-energy of Mv.RBM is a powerful and efficient outlier scoring method, which is highly competitive against state-of-the-arts.
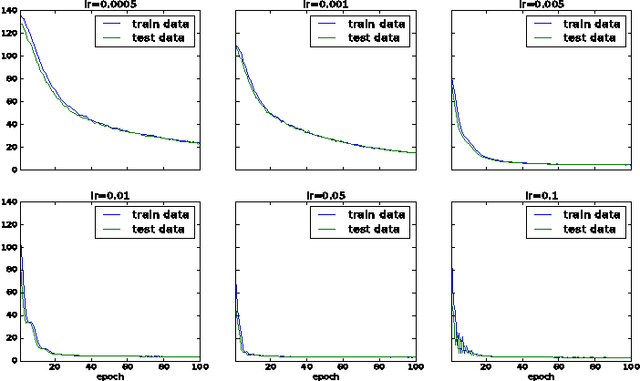
Faster Training of Very Deep Networks Via p-Norm Gates
Aug 11, 2016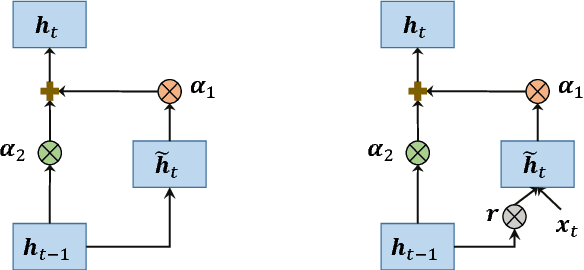
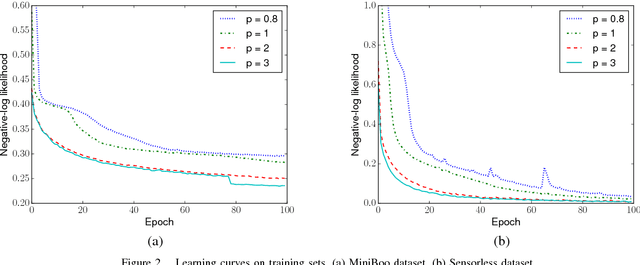
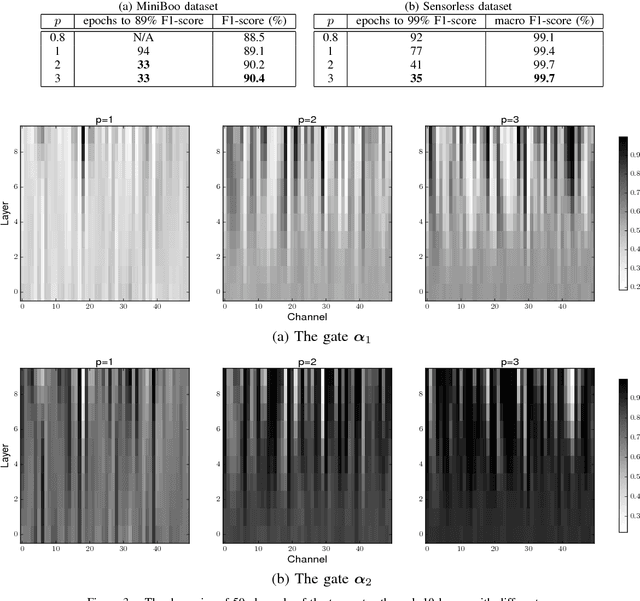
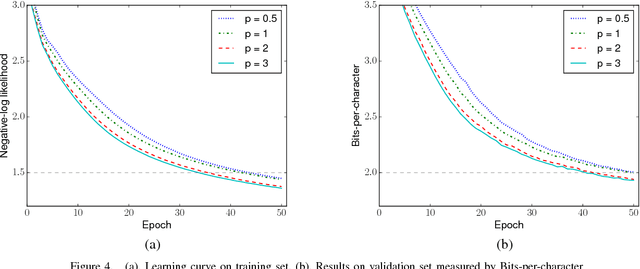
A major contributing factor to the recent advances in deep neural networks is structural units that let sensory information and gradients to propagate easily. Gating is one such structure that acts as a flow control. Gates are employed in many recent state-of-the-art recurrent models such as LSTM and GRU, and feedforward models such as Residual Nets and Highway Networks. This enables learning in very deep networks with hundred layers and helps achieve record-breaking results in vision (e.g., ImageNet with Residual Nets) and NLP (e.g., machine translation with GRU). However, there is limited work in analysing the role of gating in the learning process. In this paper, we propose a flexible $p$-norm gating scheme, which allows user-controllable flow and as a consequence, improve the learning speed. This scheme subsumes other existing gating schemes, including those in GRU, Highway Networks and Residual Nets as special cases. Experiments on large sequence and vector datasets demonstrate that the proposed gating scheme helps improve the learning speed significantly without extra overhead.
Preterm Birth Prediction: Deriving Stable and Interpretable Rules from High Dimensional Data
Jul 28, 2016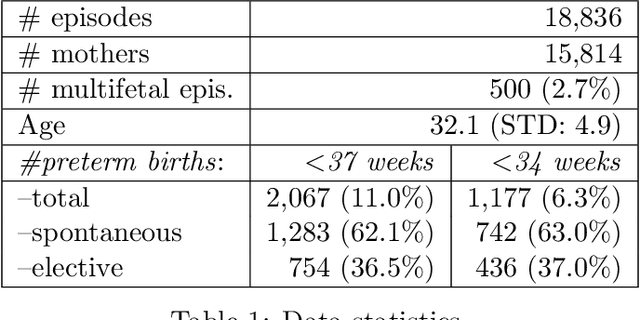

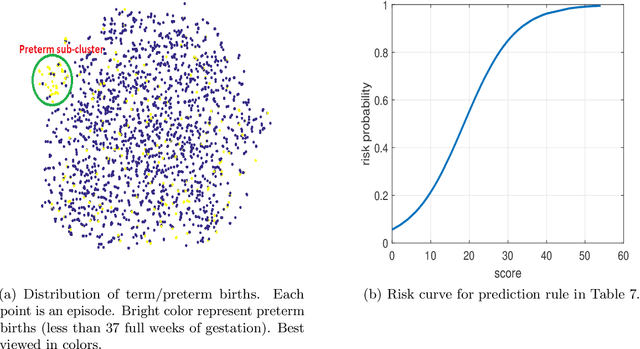
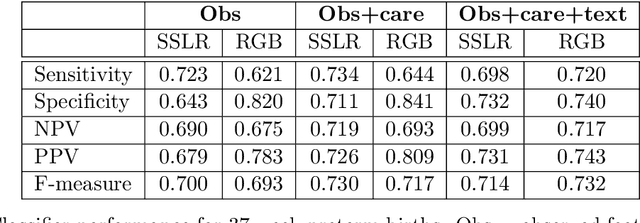
Preterm births occur at an alarming rate of 10-15%. Preemies have a higher risk of infant mortality, developmental retardation and long-term disabilities. Predicting preterm birth is difficult, even for the most experienced clinicians. The most well-designed clinical study thus far reaches a modest sensitivity of 18.2-24.2% at specificity of 28.6-33.3%. We take a different approach by exploiting databases of normal hospital operations. We aims are twofold: (i) to derive an easy-to-use, interpretable prediction rule with quantified uncertainties, and (ii) to construct accurate classifiers for preterm birth prediction. Our approach is to automatically generate and select from hundreds (if not thousands) of possible predictors using stability-aware techniques. Derived from a large database of 15,814 women, our simplified prediction rule with only 10 items has sensitivity of 62.3% at specificity of 81.5%.
Deepr: A Convolutional Net for Medical Records
Jul 26, 2016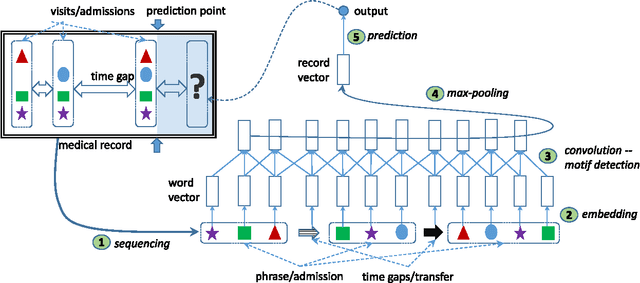
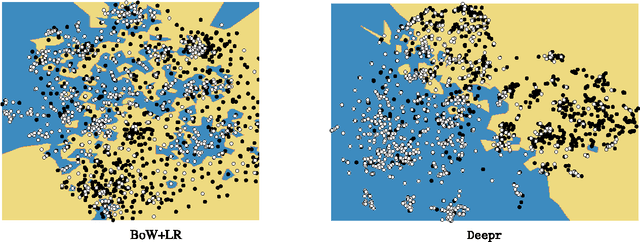
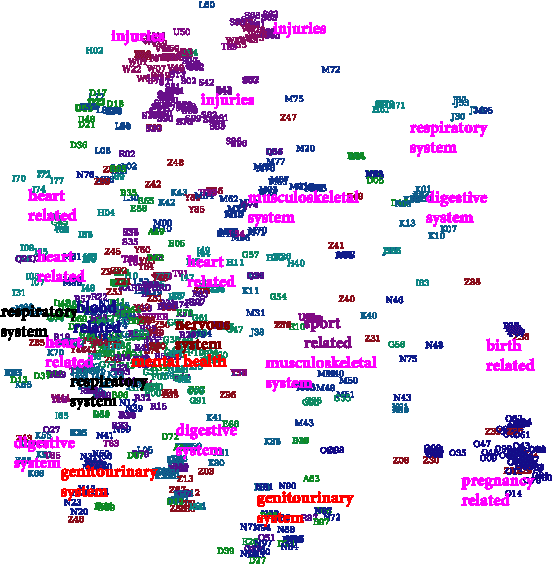

Feature engineering remains a major bottleneck when creating predictive systems from electronic medical records. At present, an important missing element is detecting predictive regular clinical motifs from irregular episodic records. We present Deepr (short for Deep record), a new end-to-end deep learning system that learns to extract features from medical records and predicts future risk automatically. Deepr transforms a record into a sequence of discrete elements separated by coded time gaps and hospital transfers. On top of the sequence is a convolutional neural net that detects and combines predictive local clinical motifs to stratify the risk. Deepr permits transparent inspection and visualization of its inner working. We validate Deepr on hospital data to predict unplanned readmission after discharge. Deepr achieves superior accuracy compared to traditional techniques, detects meaningful clinical motifs, and uncovers the underlying structure of the disease and intervention space.