 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective Annotations for Vision-Based Attention Level Estimation
Dec 12, 2018
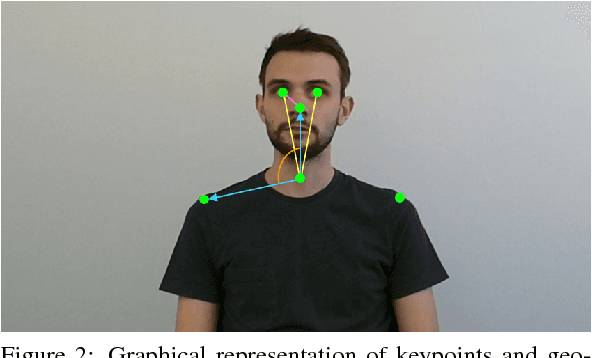
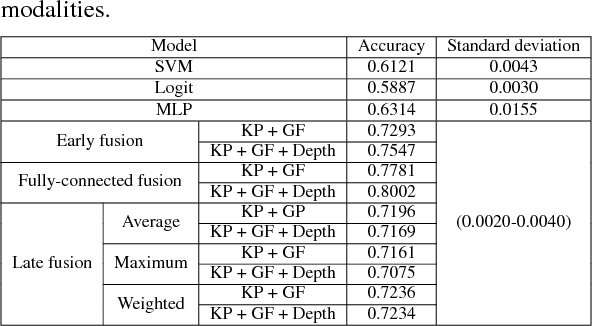
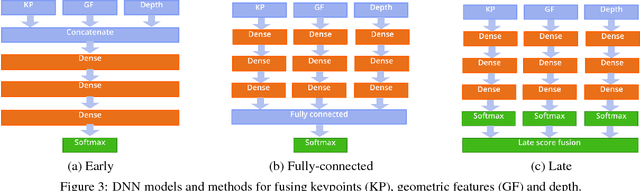
Attention level estimation systems have a high potential in many use cases, such as human-robot interaction, driver modeling and smart home systems, since being able to measure a person's attention level opens the possibility to natural interaction between humans and computers. The topic of estimating a human's visual focus of attention has been actively addressed recently in the field of HCI. However, most of these previous works do not consider attention as a subjective, cognitive attentive state. New research within the field also faces the problem of the lack of annotated datasets regarding attention level in a certain context. The novelty of our work is two-fold: First, we introduce a new annotation framework that tackles the subjective nature of attention level and use it to annotate more than 100,000 images with three attention levels and second, we introduce a novel method to estimate attention levels, relying purely on extracted geometric features from RGB and depth images, and evaluate it with a deep learning fusion framework. The system achieves an overall accuracy of 80.02%. Our framework and attention level annotations are made publicly available.
The Importance of Context When Recommending TV Content: Dataset and Algorithms
Jul 30, 2018
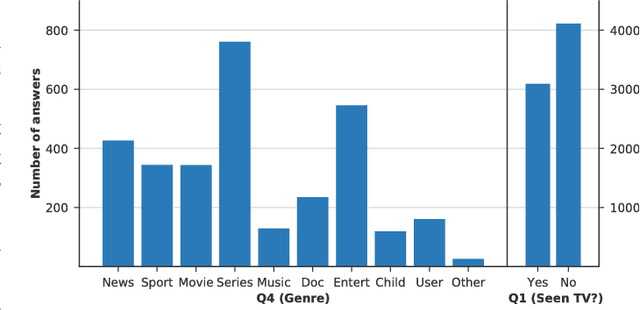
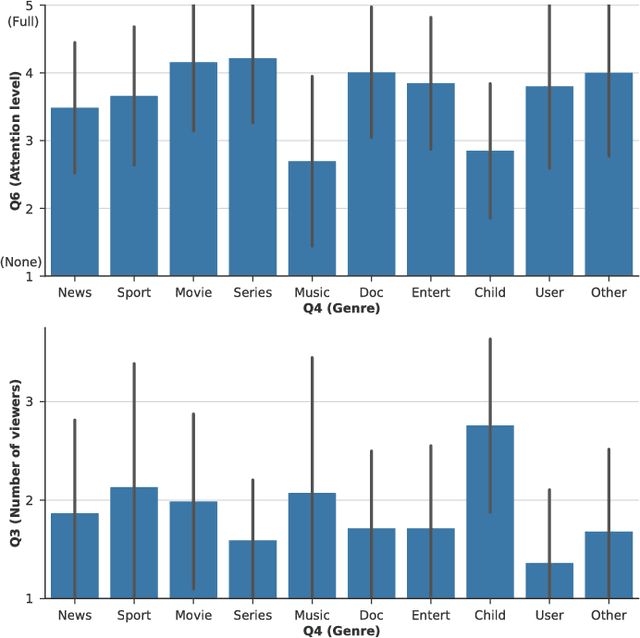
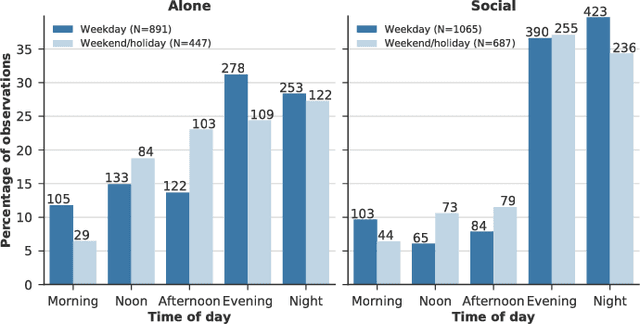
Home entertainment systems feature in a variety of usage scenarios with one or more simultaneous users, for whom the complexity of choosing media to consume has increased rapidly over the last decade. Users' decision processes are complex and highly influenced by contextual settings, but data supporting the development and evaluation of context-aware recommender systems are scarce. In this paper we present a dataset of self-reported TV consumption enriched with contextual information of viewing situations. We show how choice of genre associates with, among others, the number of present users and users' attention levels. Furthermore, we evaluate the performance of predicting chosen genres given different configurations of contextual information, and compare the results to contextless predictions. The results suggest that including contextual features in the prediction cause notable improvements, and both temporal and social context show significant contributions.