 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextIQ: A Multimodal Expert-Based Video Retrieval System for Contextual Advertising
Oct 29, 2024



Contextual advertising serves ads that are aligned to the content that the user is viewing. The rapid growth of video content on social platforms and streaming services, along with privacy concerns, has increased the need for contextual advertising. Placing the right ad in the right context creates a seamless and pleasant ad viewing experience, resulting in higher audience engagement and, ultimately, better ad monetization. From a technology standpoint, effective contextual advertising requires a video retrieval system capable of understanding complex video content at a very granular level. Current text-to-video retrieval models based on joint multimodal training demand large datasets and computational resources, limiting their practicality and lacking the key functionalities required for ad ecosystem integration. We introduce ContextIQ, a multimodal expert-based video retrieval system designed specifically for contextual advertising. ContextIQ utilizes modality-specific experts-video, audio, transcript (captions), and metadata such as objects, actions, emotion, etc.-to create semantically rich video representations. We show that our system, without joint training, achieves better or comparable results to state-of-the-art models and commercial solutions on multiple text-to-video retrieval benchmarks. Our ablation studies highlight the benefits of leveraging multiple modalities for enhanced video retrieval accuracy instead of using a vision-language model alone. Furthermore, we show how video retrieval systems such as ContextIQ can be used for contextual advertising in an ad ecosystem while also addressing concerns related to brand safety and filtering inappropriate content.
Speaker-specific Thresholding for Robust Imposter Identification in Unseen Speaker Recognition
Jun 01, 2023



Speaker identification systems are deployed in diverse environments, often different from the lab conditions on which they are trained and tested. In this paper, first, we show the problem of generalization using fixed thresholds computed using the equal error rate metric. Secondly, we introduce a novel and generalizable speaker-specific thresholding technique for robust imposter identification in unseen speaker identification. We propose a speaker-specific adaptive threshold, which can be computed using the enrollment audio samples, for identifying imposters in unseen speaker identification. Furthermore, we show the efficacy of the proposed technique on VoxCeleb1, VCTK and the FFSVC 2022 datasets, beating the baseline fixed thresholding by up to 25%. Finally, we exhibit that the proposed algorithm is also generalizable, demonstrating its performance on ResNet50, ECAPA-TDNN and RawNet3 speaker encoders.
Robust and lightweight audio fingerprint for Automatic Content Recognition
May 17, 2023



This research paper presents a novel audio fingerprinting system for Automatic Content Recognition (ACR). By using signal processing techniques and statistical transformations, our proposed method generates compact fingerprints of audio segments that are robust to noise degradations present in real-world audio. The system is designed to be highly scalable, with the ability to identify thousands of hours of content using fingerprints generated from millions of TVs. The fingerprint's high temporal correlation and utilization of existing GPU-compatible Approximate Nearest Neighbour (ANN) search algorithms make this possible. Furthermore, the fingerprint generation can run on low-power devices with limited compute, making it accessible to a wide range of applications. Experimental results show improvements in our proposed system compared to a min-hash based audio fingerprint on all evaluated metrics, including accuracy on proprietary ACR datasets, retrieval speed, memory usage, and robustness to various noises. For similar retrieval accuracy, our system is 30x faster and uses 6x fewer fingerprints than the min-hash method.
Improved Relation Networks for End-to-End Speaker Verification and Identification
Mar 31, 2022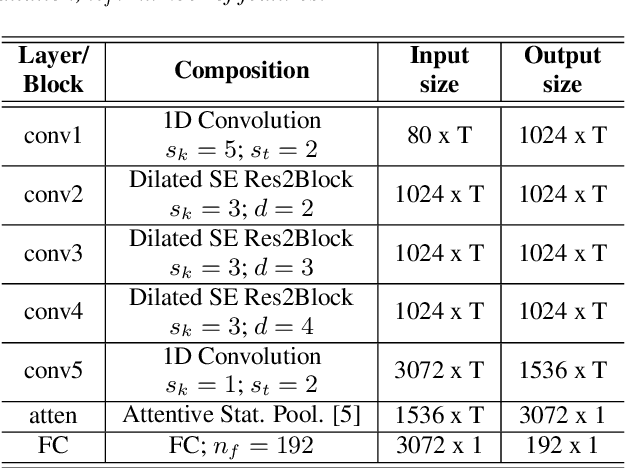
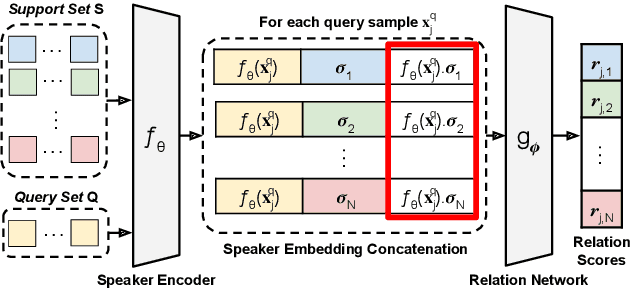

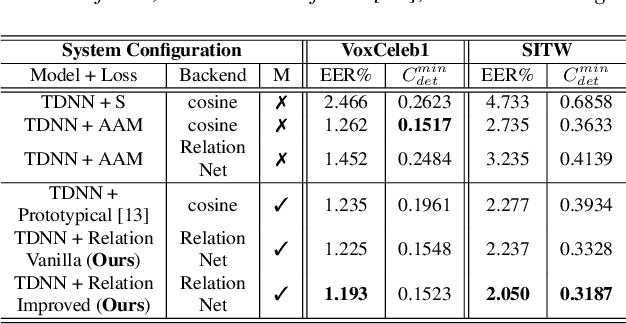
Speaker identification systems in a real-world scenario are tasked to identify a speaker amongst a set of enrolled speakers given just a few samples for each enrolled speaker. This paper demonstrates the effectiveness of meta-learning and relation networks for this use case. We propose improved relation networks for speaker verification and few-shot (unseen) speaker identification. The use of relation networks facilitates joint training of the frontend speaker encoder and the backend model. Inspired by the use of prototypical networks in speaker verification and to increase the discriminability of the speaker embeddings, we train the model to classify samples in the current episode amongst all speakers present in the training set. Furthermore, we propose a new training regime for faster model convergence by extracting more information from a given meta-learning episode with negligible extra computation. We evaluate the proposed techniques on VoxCeleb, SITW and VCTK datasets on the tasks of speaker verification and unseen speaker identification. The proposed approach outperforms the existing approaches consistently on both tasks.