 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Form Adaptive-Landmark Kernel for Certified Point-Cloud and Graph Classification
May 05, 2026We introduce PALACE (Persistence Adaptive-Landmark Analytic Classification Engine), the data-adaptive companion to PLACE, paying a small cross-validation tier on three knobs (budget, radii, bandwidth; $\leq 5$ choices each). A cover-theoretic core (Lebesgue-number criterion on the landmark cover) yields four closed-form guarantees. (i) A structural lower distortion bound $λ(τ;ν)$ on $\mathcal{D}_n$ under cross-diagram non-interference, with a $(D/L)^2$ budget reduction over the uniform grid when diagrams concentrate. (ii) Equal weights $w_k = K^{-1/2}$ maximizing $λ$, and farthest-point-sampling positions $2$-approximating the optimal $k$-center covering radius; both derived from training labels alone, no gradient training. (iii) A kernel-RKHS classification rate $O((k-1)\sqrt{K}/(γ\sqrt{m_{\min}}))$ with binary necessity threshold $m = Ω(\sqrt K/γ)$ from a matching Le Cam lower bound, and a closed-form filtration-selection rule. The kernel-Mahalanobis margin $\hatρ_{\mathrm{Mah}}$ is the strongest closed-form ranker across the chemical-graph pool (mean Spearman $ρ\approx +0.60$); the isotropic surrogate $\hatγ/\sqrt{K}$ admits a selection-consistency rate, and $\widehatλ$ from (i) provides an independent data-level signal (positive on COX2 and PTC). (iv) A per-prediction certificate, in non-asymptotic Pinelis and asymptotic Gaussian forms, with no calibration split. Empirically, PALACE is the strongest closed-form diagram-based method on Orbit5k ($91.3 \pm 1.0\%$, matching Persformer), leads every diagram-based competitor on COX2 and MUTAG, and is competitive on DHFR (within 1 pp of ECP). At $8\times$ domain inflation, adaptive placement maintains $94\%$ while the uniform grid collapses to chance ($25\%$ on 4-class data).
A Closed-Form Persistence-Landmark Pipeline for Certified Point-Cloud and Graph Classification
May 04, 2026We introduce PLACE (Persistence-Landmark Analytic Classification Engine), a closed-form pipeline for classifying point clouds and graphs through their persistent-homology signatures. Three quantitative guarantees -- a margin-based excess-risk rate, a closed-form descriptor-selection rule, and a per-prediction certificate -- are derived from training labels alone, with no learned weights or held-out calibration. The embedding sums Mitra-Virk single-point coordinate functions over a sparse landmark grid; closed-form weights maximize a structural distortion constant $λ(ν)$ (a Lipschitz lower bound on $\mathcal{D}_n$ under non-interference). (i) An $O(kR/(Δ\sqrt{m_{\min}}))$ margin bound, driven by class-mean separation $Δ$ and embedding radius $R$, matched by a sample-starved minimax lower bound. (ii) The Mahalanobis margin under Ledoit-Wolf-shrunk covariance is the strongest closed-form descriptor selector on a heterogeneous 64-descriptor chemical-graph pool (mean Spearman $ρ\approx +0.54$ across 10 benchmarks, positive on 9 of 10); the isotropic surrogate $Δ/\sqrt\ell$ admits a closed-form selection-consistency rate on homogeneous (14-15 descriptor) protein/social pools. (iii) A training-time-decided certificate with no per-prediction overhead, in non-asymptotic Pinelis and asymptotic Gaussian plug-in forms. Empirically, PLACE is the strongest diagram-based method on Orbit5k and matches the strongest topology-based baseline within statistical noise on MUTAG and COX2. The remaining gaps fall into two diagnosable regimes: descriptor blindness on NCI1/NCI109, and pool-coverage limits elsewhere. Both radii exceed the firing threshold $\hatΔ/2$ on every benchmark at our training-set sizes, dominated by the $\sqrt\ell$ scaling of the multivariate-norm bound; the per-prediction certificate is constructive but not yet operational at these sizes.
Topological Characterization of Churn Flow and Unsupervised Correction to the Wu Flow-Regime Map in Small-Diameter Vertical Pipes
Apr 07, 2026Churn flow-the chaotic, oscillatory regime in vertical two-phase flow-has lacked a quantitative mathematical definition for over $40$ years. We introduce the first topology-based characterization using Euler Characteristic Surfaces (ECS). We formulate unsupervised regime discovery as Multiple Kernel Learning (MKL), blending two complementary ECS-derived kernels-temporal alignment ($L^1$ distance on the $χ(s,t)$ surface) and amplitude statistics (scale-wise mean, standard deviation, max, min)-with gas velocity. Applied to $37$ unlabeled air-water trials from Montana Tech, the self-calibrating framework learns weights $β_{ECS}=0.14$, $β_{amp}=0.50$, $β_{ugs}=0.36$, placing $64\%$ of total weight on topology-derived features ($β_{ECS} + β_{amp}$). The ECS-inferred slug/churn transition lies $+3.81$ m/s above Wu et al.'s (2017) prediction in $2$-in. tubing, quantifying reports that existing models under-predict slug persistence in small-diameter pipes where interfacial tension and wall-to-wall interactions dominate flow. Cross-facility validation on $947$ Texas A&M University images confirms $1.9\times$ higher topological complexity in churn vs. slug ($p < 10^{-5}$). Applied to $45$ TAMU pseudo-trials, the same unsupervised framework achieves $95.6\%$ $4$-class accuracy and $100\%$ churn recall-without any labeled training data-matching or exceeding supervised baselines that require thousands of annotated examples. This work provides the first mathematical definition of churn flow and demonstrates that unsupervised topological descriptors can challenge and correct widely adopted mechanistic models.
Graph Mover's Distance: An Efficiently Computable Distance Measure for Geometric Graphs
Jun 03, 2023



Many applications in pattern recognition represent patterns as a geometric graph. The geometric graph distance (GGD) has recently been studied as a meaningful measure of similarity between two geometric graphs. Since computing the GGD is known to be $\mathcal{NP}$-hard, the distance measure proves an impractical choice for applications. As a computationally tractable alternative, we propose in this paper the Graph Mover's Distance (GMD), which has been formulated as an instance of the earth mover's distance. The computation of the GMD between two geometric graphs with at most $n$ vertices takes only $O(n^3)$-time. Alongside studying the metric properties of the GMD, we investigate the stability of the GGD and GMD. The GMD also demonstrates extremely promising empirical evidence at recognizing letter drawings from the {\tt LETTER} dataset \cite{da_vitoria_lobo_iam_2008}.
Distance Measures for Geometric Graphs
Sep 26, 2022
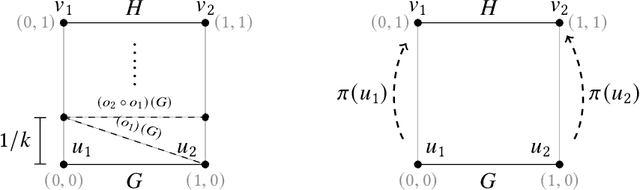
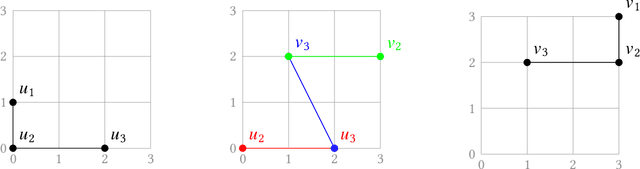
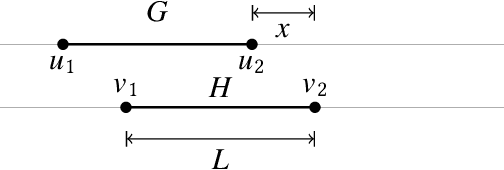
A geometric graph is a combinatorial graph, endowed with a geometry that is inherited from its embedding in a Euclidean space. Formulation of a meaningful measure of (dis-)similarity in both the combinatorial and geometric structures of two such geometric graphs is a challenging problem in pattern recognition. We study two notions of distance measures for geometric graphs, called the geometric edit distance (GED) and geometric graph distance (GGD). While the former is based on the idea of editing one graph to transform it into the other graph, the latter is inspired by inexact matching of the graphs. For decades, both notions have been lending themselves well as measures of similarity between attributed graphs. If used without any modification, however, they fail to provide a meaningful distance measure for geometric graphs -- even cease to be a metric. We have curated their associated cost functions for the context of geometric graphs. Alongside studying the metric properties of GED and GGD, we investigate how the two notions compare. We further our understanding of the computational aspects of GGD by showing that the distance is $\mathcal{NP}$-hard to compute, even if the graphs are planar and arbitrary cost coefficients are allowed.