 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoded but Not Routed: Explaining the Table-Chart Gap in Scientific Claim Verification
Jun 01, 2026Multimodal LLMs are increasingly used to assist scientific peer review, where a core requirement is verifying whether claims in a paper are supported by its evidence. Prior work has shown that models perform substantially better at this task when the evidence is a table than when it is a chart of the same underlying data. This raises the question of whether models fail to extract information from charts, or do they extract it but fail to use it when forming their prediction? We study this question through layer-wise linear probing and attention analysis on three open-weight VLMs over table and chart evidence, representing the same underlying data. We find consistent evidence for the latter. Chart information is encoded in the models' intermediate representations but does not reach the prediction position, a gap that is absent for tables and holds across all conditions tested. Attention analysis further reveals that this disconnect takes two architecturally distinct forms across model families. These findings reframe the table-chart gap as a failure of how encoded visual information is routed at prediction time, rather than a failure of encoding itself.
SciClaimEval: Cross-modal Claim Verification in Scientific Papers
Feb 07, 2026We present SciClaimEval, a new scientific dataset for the claim verification task. Unlike existing resources, SciClaimEval features authentic claims, including refuted ones, directly extracted from published papers. To create refuted claims, we introduce a novel approach that modifies the supporting evidence (figures and tables), rather than altering the claims or relying on large language models (LLMs) to fabricate contradictions. The dataset provides cross-modal evidence with diverse representations: figures are available as images, while tables are provided in multiple formats, including images, LaTeX source, HTML, and JSON. SciClaimEval contains 1,664 annotated samples from 180 papers across three domains, machine learning, natural language processing, and medicine, validated through expert annotation. We benchmark 11 multimodal foundation models, both open-source and proprietary, across the dataset. Results show that figure-based verification remains particularly challenging for all models, as a substantial performance gap remains between the best system and human baseline.
Format Matters: The Robustness of Multimodal LLMs in Reviewing Evidence from Tables and Charts
Nov 13, 2025



With the growing number of submitted scientific papers, there is an increasing demand for systems that can assist reviewers in evaluating research claims. Experimental results are a core component of scientific work, often presented in varying formats such as tables or charts. Understanding how robust current multimodal large language models (multimodal LLMs) are at verifying scientific claims across different evidence formats remains an important and underexplored challenge. In this paper, we design and conduct a series of experiments to assess the ability of multimodal LLMs to verify scientific claims using both tables and charts as evidence. To enable this evaluation, we adapt two existing datasets of scientific papers by incorporating annotations and structures necessary for a multimodal claim verification task. Using this adapted dataset, we evaluate 12 multimodal LLMs and find that current models perform better with table-based evidence while struggling with chart-based evidence. We further conduct human evaluations and observe that humans maintain strong performance across both formats, unlike the models. Our analysis also reveals that smaller multimodal LLMs (under 8B) show weak correlation in performance between table-based and chart-based tasks, indicating limited cross-modal generalization. These findings highlight a critical gap in current models' multimodal reasoning capabilities. We suggest that future multimodal LLMs should place greater emphasis on improving chart understanding to better support scientific claim verification.
Table-Text Alignment: Explaining Claim Verification Against Tables in Scientific Papers
Jun 12, 2025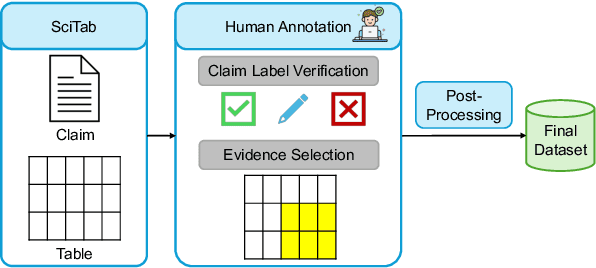



Scientific claim verification against tables typically requires predicting whether a claim is supported or refuted given a table. However, we argue that predicting the final label alone is insufficient: it reveals little about the model's reasoning and offers limited interpretability. To address this, we reframe table-text alignment as an explanation task, requiring models to identify the table cells essential for claim verification. We build a new dataset by extending the SciTab benchmark with human-annotated cell-level rationales. Annotators verify the claim label and highlight the minimal set of cells needed to support their decision. After the annotation process, we utilize the collected information and propose a taxonomy for handling ambiguous cases. Our experiments show that (i) incorporating table alignment information improves claim verification performance, and (ii) most LLMs, while often predicting correct labels, fail to recover human-aligned rationales, suggesting that their predictions do not stem from faithful reasoning.
Cross-Lingual NER for Financial Transaction Data in Low-Resource Languages
Jul 16, 2023



We propose an efficient modeling framework for cross-lingual named entity recognition in semi-structured text data. Our approach relies on both knowledge distillation and consistency training. The modeling framework leverages knowledge from a large language model (XLMRoBERTa) pre-trained on the source language, with a student-teacher relationship (knowledge distillation). The student model incorporates unsupervised consistency training (with KL divergence loss) on the low-resource target language. We employ two independent datasets of SMSs in English and Arabic, each carrying semi-structured banking transaction information, and focus on exhibiting the transfer of knowledge from English to Arabic. With access to only 30 labeled samples, our model can generalize the recognition of merchants, amounts, and other fields from English to Arabic. We show that our modeling approach, while efficient, performs best overall when compared to state-of-the-art approaches like DistilBERT pre-trained on the target language or a supervised model directly trained on labeled data in the target language. Our experiments show that it is enough to learn to recognize entities in English to reach reasonable performance in a low-resource language in the presence of a few labeled samples of semi-structured data. The proposed framework has implications for developing multi-lingual applications, especially in geographies where digital endeavors rely on both English and one or more low-resource language(s), sometimes mixed with English or employed singly.