 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Syntax and Semantics of Prepositions via Tensor Decomposition
May 23, 2018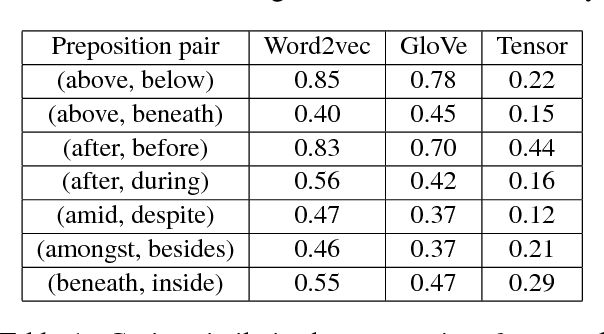

Prepositions are among the most frequent words in English and play complex roles in the syntax and semantics of sentences. Not surprisingly, they pose well-known difficulties in automatic processing of sentences (prepositional attachment ambiguities and idiosyncratic uses in phrases). Existing methods on preposition representation treat prepositions no different from content words (e.g., word2vec and GloVe). In addition, recent studies aiming at solving prepositional attachment and preposition selection problems depend heavily on external linguistic resources and use dataset-specific word representations. In this paper we use word-triple counts (one of the triples being a preposition) to capture a preposition's interaction with its attachment and complement. We then derive preposition embeddings via tensor decomposition on a large unlabeled corpus. We reveal a new geometry involving Hadamard products and empirically demonstrate its utility in paraphrasing phrasal verbs. Furthermore, our preposition embeddings are used as simple features in two challenging downstream tasks: preposition selection and prepositional attachment disambiguation. We achieve results comparable to or better than the state-of-the-art on multiple standardized datasets.
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
Mar 19, 2018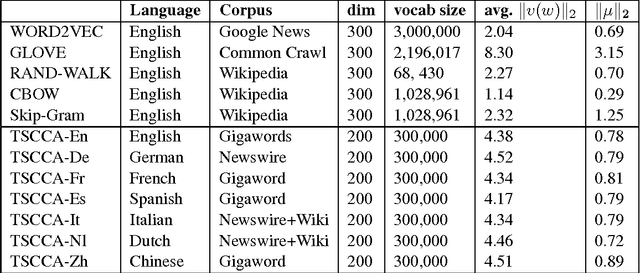
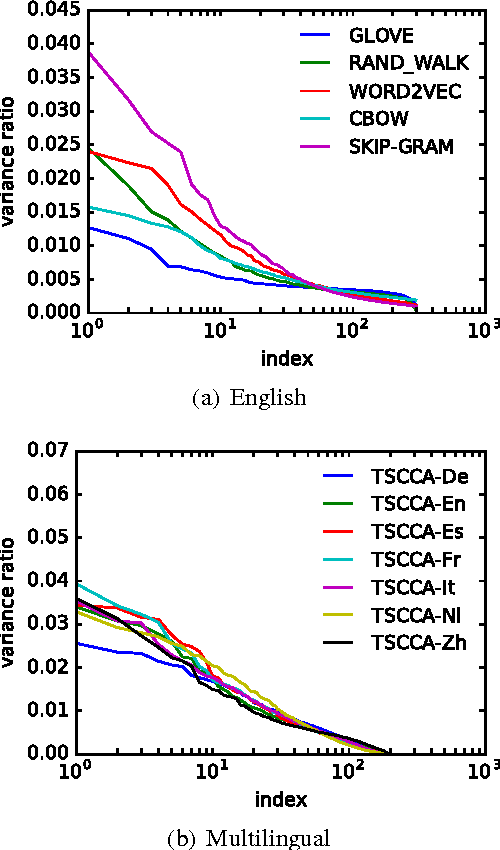
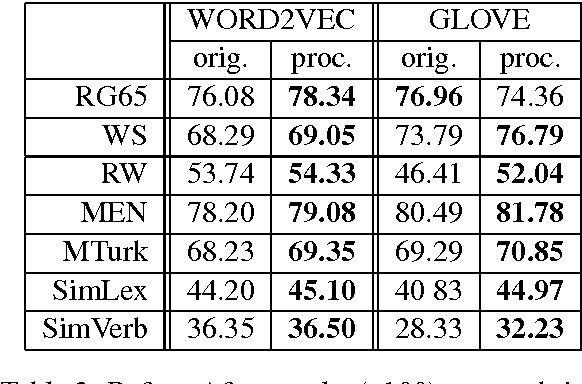
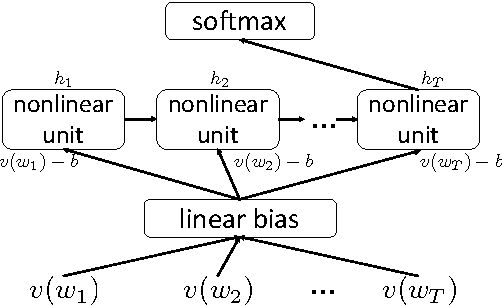
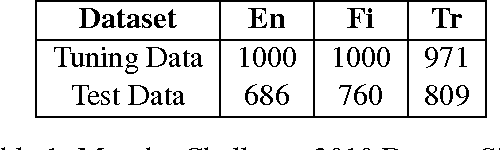
Real-valued word representations have transformed NLP applications; popular examples are word2vec and GloVe, recognized for their ability to capture linguistic regularities. In this paper, we demonstrate a {\em very simple}, and yet counter-intuitive, postprocessing technique -- eliminate the common mean vector and a few top dominating directions from the word vectors -- that renders off-the-shelf representations {\em even stronger}. The postprocessing is empirically validated on a variety of lexical-level intrinsic tasks (word similarity, concept categorization, word analogy) and sentence-level tasks (semantic textural similarity and { text classification}) on multiple datasets and with a variety of representation methods and hyperparameter choices in multiple languages; in each case, the processed representations are consistently better than the original ones.
MORSE: Semantic-ally Drive-n MORpheme SEgment-er
May 01, 2017
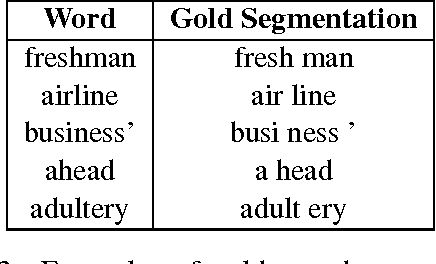
We present in this paper a novel framework for morpheme segmentation which uses the morpho-syntactic regularities preserved by word representations, in addition to orthographic features, to segment words into morphemes. This framework is the first to consider vocabulary-wide syntactico-semantic information for this task. We also analyze the deficiencies of available benchmarking datasets and introduce our own dataset that was created on the basis of compositionality. We validate our algorithm across datasets and present state-of-the-art results.
Representing Sentences as Low-Rank Subspaces
Apr 18, 2017
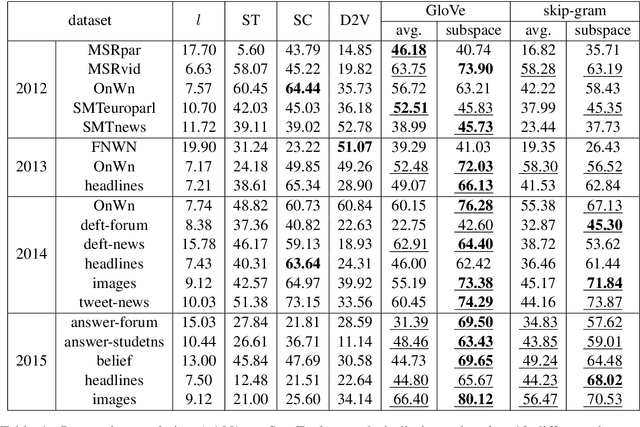
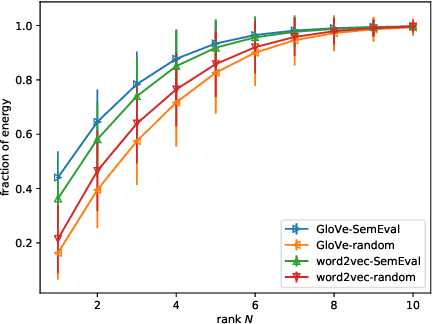
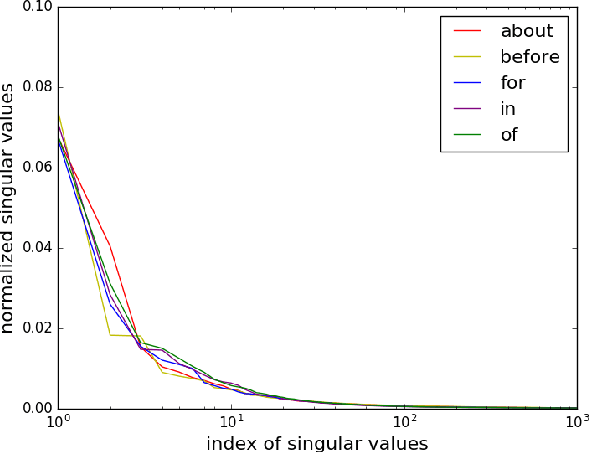
Sentences are important semantic units of natural language. A generic, distributional representation of sentences that can capture the latent semantics is beneficial to multiple downstream applications. We observe a simple geometry of sentences -- the word representations of a given sentence (on average 10.23 words in all SemEval datasets with a standard deviation 4.84) roughly lie in a low-rank subspace (roughly, rank 4). Motivated by this observation, we represent a sentence by the low-rank subspace spanned by its word vectors. Such an unsupervised representation is empirically validated via semantic textual similarity tasks on 19 different datasets, where it outperforms the sophisticated neural network models, including skip-thought vectors, by 15% on average.
Fixing the Infix: Unsupervised Discovery of Root-and-Pattern Morphology
Feb 11, 2017

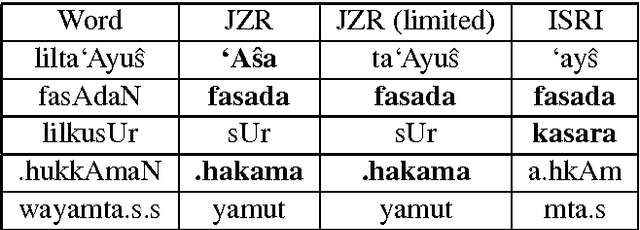

We present an unsupervised and language-agnostic method for learning root-and-pattern morphology in Semitic languages. This form of morphology, abundant in Semitic languages, has not been handled in prior unsupervised approaches. We harness the syntactico-semantic information in distributed word representations to solve the long standing problem of root-and-pattern discovery in Semitic languages. Moreover, we construct an unsupervised root extractor based on the learned rules. We prove the validity of learned rules across Arabic, Hebrew, and Amharic, alongside showing that our root extractor compares favorably with a widely used, carefully engineered root extractor: ISRI.
Prepositions in Context
Feb 05, 2017
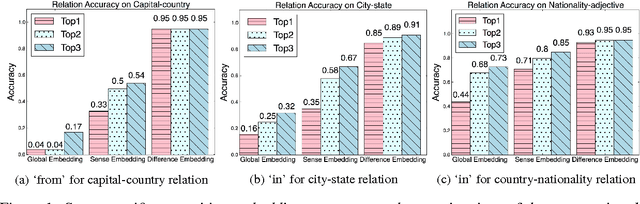
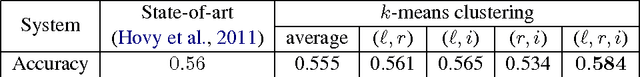
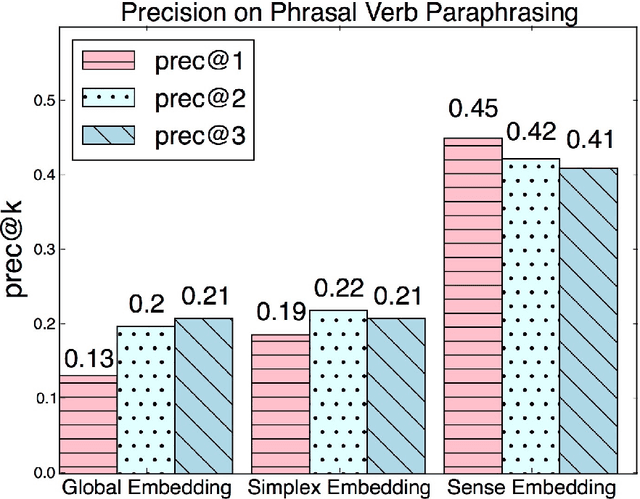
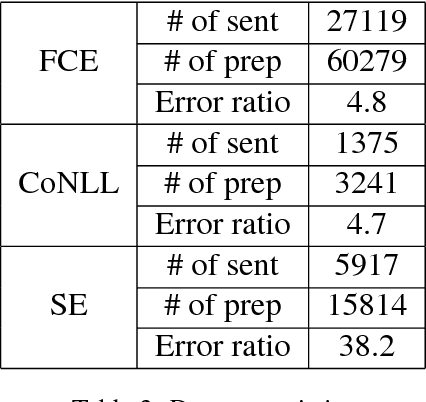
Prepositions are highly polysemous, and their variegated senses encode significant semantic information. In this paper we match each preposition's complement and attachment and their interplay crucially to the geometry of the word vectors to the left and right of the preposition. Extracting such features from the vast number of instances of each preposition and clustering them makes for an efficient preposition sense disambigution (PSD) algorithm, which is comparable to and better than state-of-the-art on two benchmark datasets. Our reliance on no external linguistic resource allows us to scale the PSD algorithm to a large WikiCorpus and learn sense-specific preposition representations -- which we show to encode semantic relations and paraphrasing of verb particle compounds, via simple vector operations.
Geometry of Compositionality
Nov 29, 2016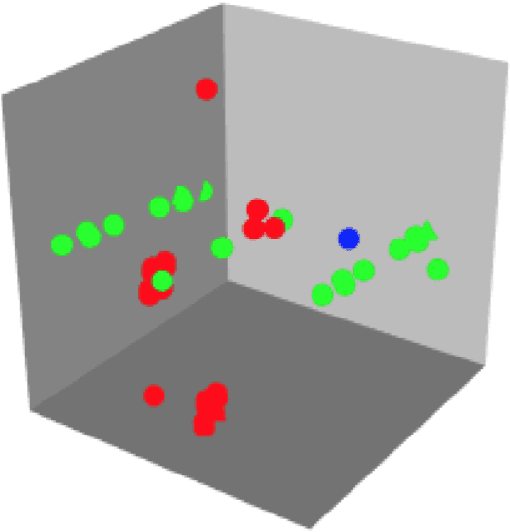
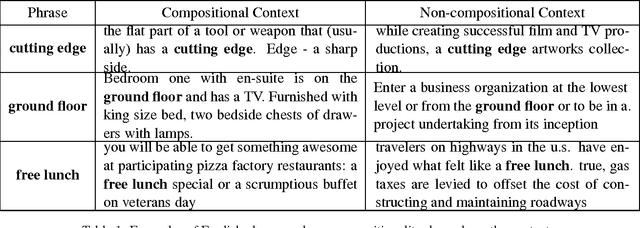
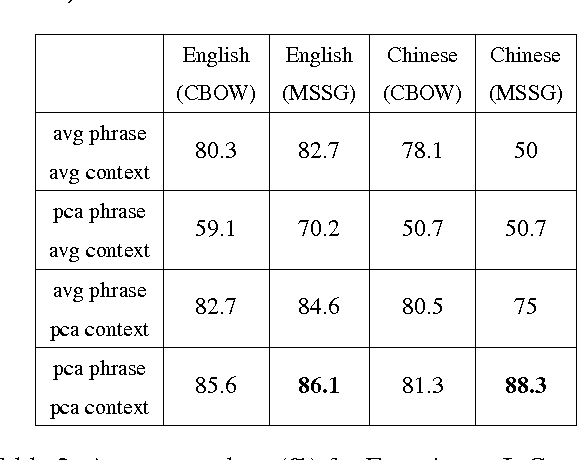
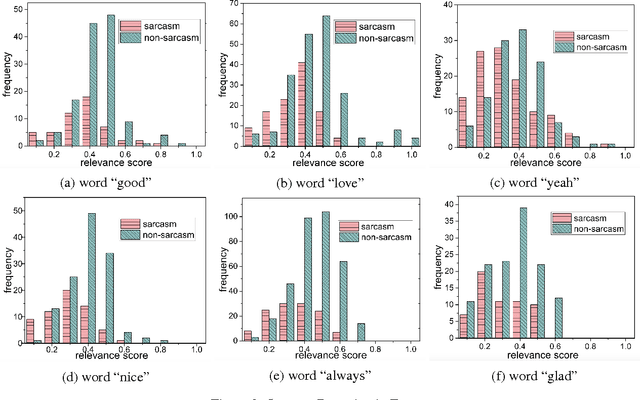
This paper proposes a simple test for compositionality (i.e., literal usage) of a word or phrase in a context-specific way. The test is computationally simple, relying on no external resources and only uses a set of trained word vectors. Experiments show that the proposed method is competitive with state of the art and displays high accuracy in context-specific compositionality detection of a variety of natural language phenomena (idiomaticity, sarcasm, metaphor) for different datasets in multiple languages. The key insight is to connect compositionality to a curious geometric property of word embeddings, which is of independent interest.
Geometry of Polysemy
Oct 24, 2016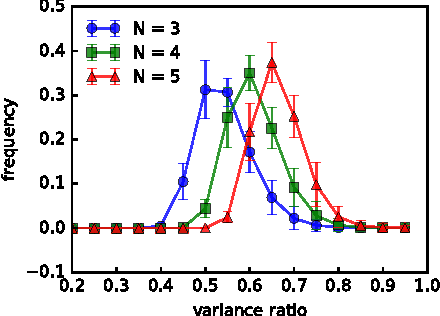

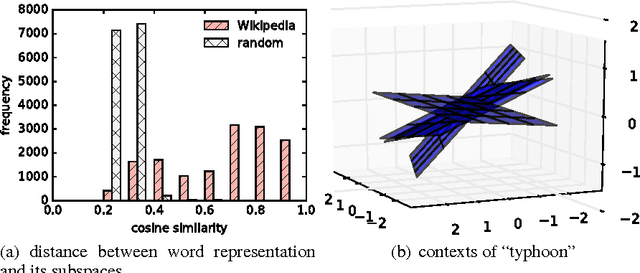
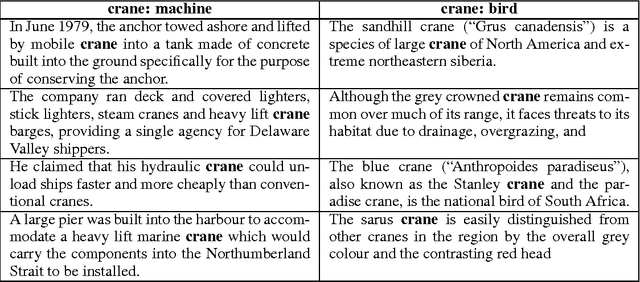
Vector representations of words have heralded a transformational approach to classical problems in NLP; the most popular example is word2vec. However, a single vector does not suffice to model the polysemous nature of many (frequent) words, i.e., words with multiple meanings. In this paper, we propose a three-fold approach for unsupervised polysemy modeling: (a) context representations, (b) sense induction and disambiguation and (c) lexeme (as a word and sense pair) representations. A key feature of our work is the finding that a sentence containing a target word is well represented by a low rank subspace, instead of a point in a vector space. We then show that the subspaces associated with a particular sense of the target word tend to intersect over a line (one-dimensional subspace), which we use to disambiguate senses using a clustering algorithm that harnesses the Grassmannian geometry of the representations. The disambiguation algorithm, which we call $K$-Grassmeans, leads to a procedure to label the different senses of the target word in the corpus -- yielding lexeme vector representations, all in an unsupervised manner starting from a large (Wikipedia) corpus in English. Apart from several prototypical target (word,sense) examples and a host of empirical studies to intuit and justify the various geometric representations, we validate our algorithms on standard sense induction and disambiguation datasets and present new state-of-the-art results.