 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Explanations: Interpretable Diabetic Retinopathy Grading with CNN-Transformer Ensembles, Visual Explainability and Vision-Language Models
Apr 25, 2026The quality of diabetic retinopathy (DR) screening relies on the ability to correctly grade severity; however, many deep-learning (DL) classifiers cannot be easily interpreted in the clinical context. This study presents a methodology that combines strong discriminative models with multimodal explanations, converting retinal pixels into clinically interpretable outputs. Using the APTOS 2019 benchmark, we evaluated six representative CNN- and transformer-based backbones under a controlled protocol with stratified five-fold cross-validation. We then compared ensembling strategies (hard voting, weighted soft voting, stacking) and investigated a hybrid class-level fusion variant to exploit grade-specific advantages. For interpretability, we produced Grad-CAM++ visual attribution maps and short textual rationales using vision-language models (VLMs) conditioned on the fundus image and classifier outputs under conservative prompting constraints. Modern CNN backbones (ResNet-50 and ConvNeXt-Tiny) provided the strongest single-model baselines, with cross-validated QWK up to 0.919 and 0.914, respectively. Ensembling improved ordinal agreement, and weighted soft voting was the most consistent across folds (QWK 0.934 +/- 0.017). Hybrid class-level fusion was competitive but did not yield a statistically reliable improvement over standard fusion in paired fold comparisons (Holm-adjusted p >= 1.000). For explanation quality, Grad-CAM++ offered plausible but coarse localization, and VLM rationales were generally grade-consistent. Quantitatively, VLM variants showed a trade-off between clinical completeness and template-level semantic similarity (coverage 0.700 vs. BERTScore 0.072), while image-text alignment was comparable (CLIPScore approximately 0.34).
When Handcrafted Features and Deep Features Meet Mismatched Training and Test Sets for Deepfake Detection
Sep 27, 2022
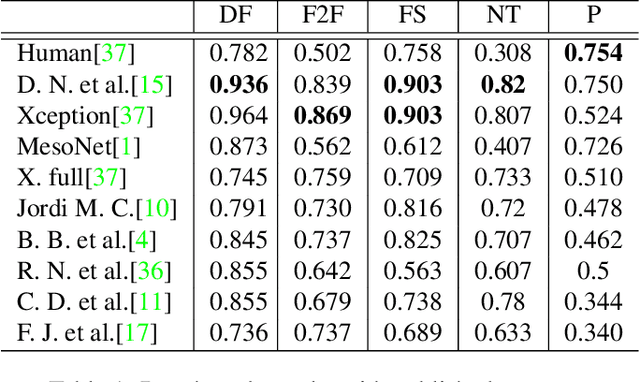
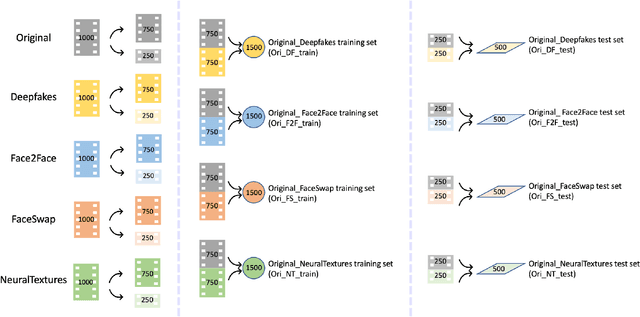
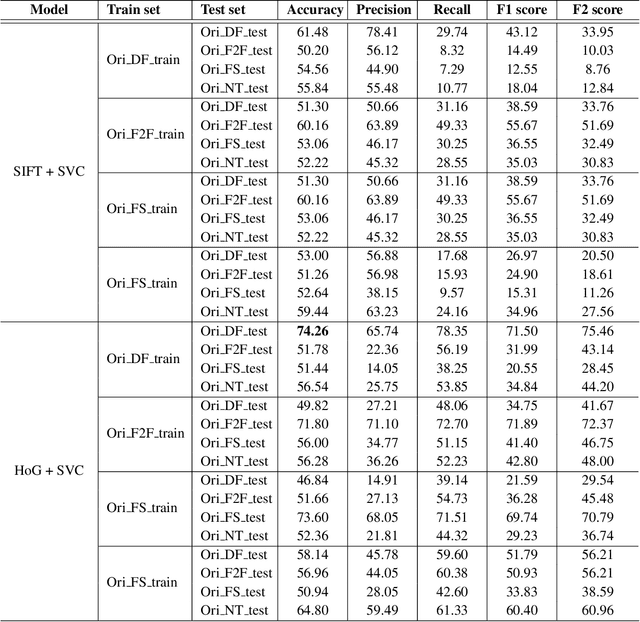
The accelerated growth in synthetic visual media generation and manipulation has now reached the point of raising significant concerns and posing enormous intimidations towards society. There is an imperative need for automatic detection networks towards false digital content and avoid the spread of dangerous artificial information to contend with this threat. In this paper, we utilize and compare two kinds of handcrafted features(SIFT and HoG) and two kinds of deep features(Xception and CNN+RNN) for the deepfake detection task. We also check the performance of these features when there are mismatches between training sets and test sets. Evaluation is performed on the famous FaceForensics++ dataset, which contains four sub-datasets, Deepfakes, Face2Face, FaceSwap and NeuralTextures. The best results are from Xception, where the accuracy could surpass over 99\% when the training and test set are both from the same sub-dataset. In comparison, the results drop dramatically when the training set mismatches the test set. This phenomenon reveals the challenge of creating a universal deepfake detection system.