 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Epidemic Forecasting: A Survey
Jul 20, 2022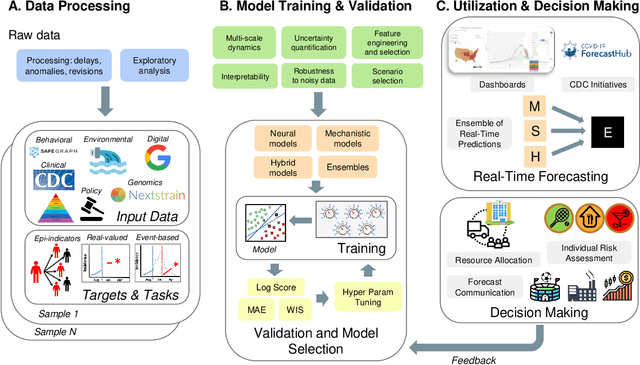
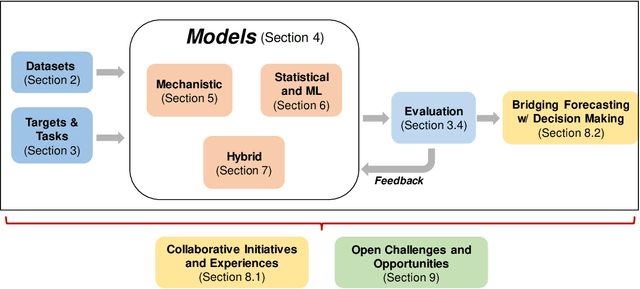
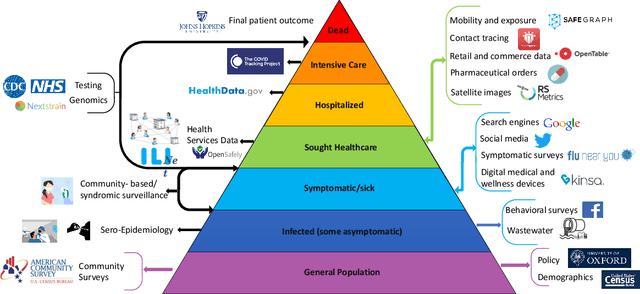
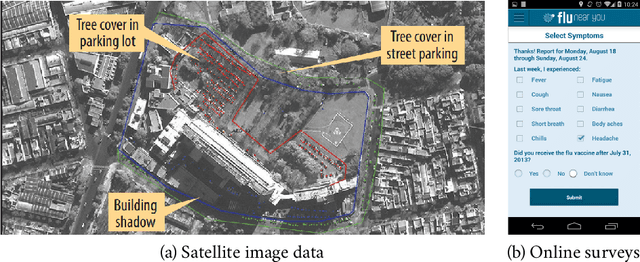
The COVID-19 pandemic has brought forth the importance of epidemic forecasting for decision makers in multiple domains, ranging from public health to the economy as a whole. While forecasting epidemic progression is frequently conceptualized as being analogous to weather forecasting, however it has some key differences and remains a non-trivial task. The spread of diseases is subject to multiple confounding factors spanning human behavior, pathogen dynamics, weather and environmental conditions. Research interest has been fueled by the increased availability of rich data sources capturing previously unobservable facets and also due to initiatives from government public health and funding agencies. This has resulted, in particular, in a spate of work on 'data-centered' solutions which have shown potential in enhancing our forecasting capabilities by leveraging non-traditional data sources as well as recent innovations in AI and machine learning. This survey delves into various data-driven methodological and practical advancements and introduces a conceptual framework to navigate through them. First, we enumerate the large number of epidemiological datasets and novel data streams that are relevant to epidemic forecasting, capturing various factors like symptomatic online surveys, retail and commerce, mobility, genomics data and more. Next, we discuss methods and modeling paradigms focusing on the recent data-driven statistical and deep-learning based methods as well as on the novel class of hybrid models that combine domain knowledge of mechanistic models with the effectiveness and flexibility of statistical approaches. We also discuss experiences and challenges that arise in real-world deployment of these forecasting systems including decision-making informed by forecasts. Finally, we highlight some challenges and open problems found across the forecasting pipeline.
A Robust Comparison of the KDDCup99 and NSL-KDD IoT Network Intrusion Detection Datasets Through Various Machine Learning Algorithms
Dec 31, 2019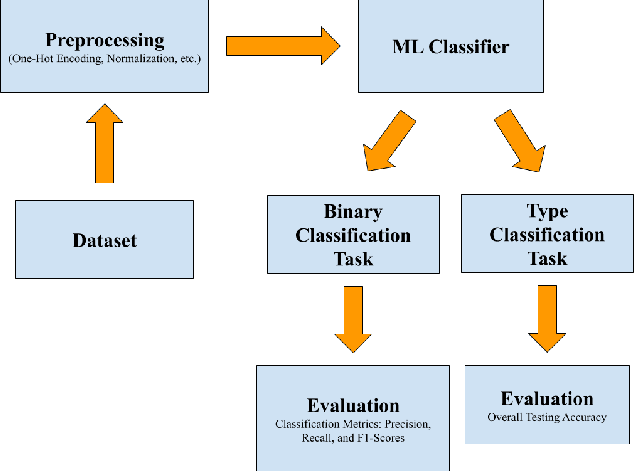
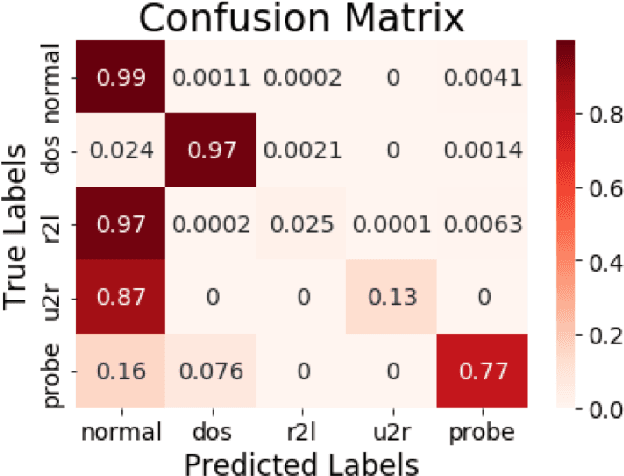
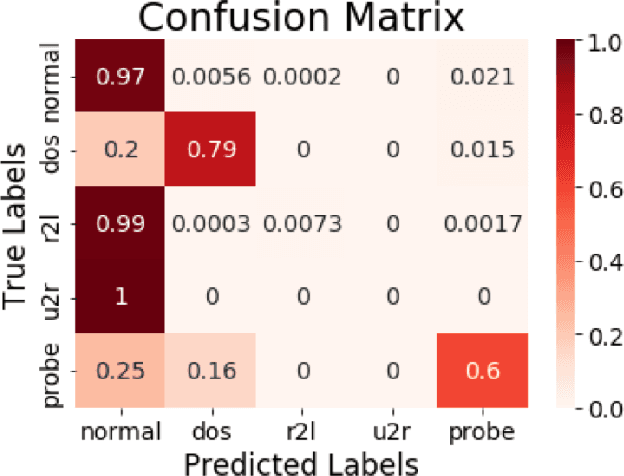
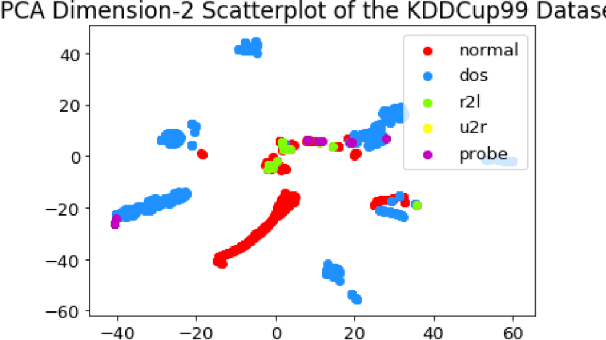
In recent years, as intrusion attacks on IoT networks have grown exponentially, there is an immediate need for sophisticated intrusion detection systems (IDSs). A vast majority of current IDSs are data-driven, which means that one of the most important aspects of this area of research is the quality of the data acquired from IoT network traffic. Two of the most cited intrusion detection datasets are the KDDCup99 and the NSL-KDD. The main goal of our project was to conduct a robust comparison of both datasets by evaluating the performance of various Machine Learning (ML) classifiers trained on them with a larger set of classification metrics than previous researchers. From our research, we were able to conclude that the NSL-KDD dataset is of a higher quality than the KDDCup99 dataset as the classifiers trained on it were on average 20.18% less accurate. This is because the classifiers trained on the KDDCup99 dataset exhibited a bias towards the redundancies within it, allowing them to achieve higher accuracies.