 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Ternary Coding and Three-Valued Logic
Jul 13, 2018
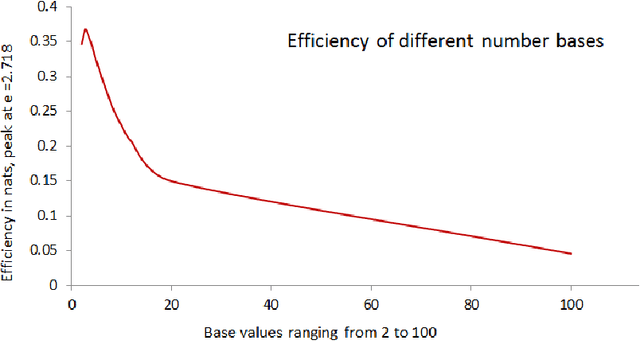

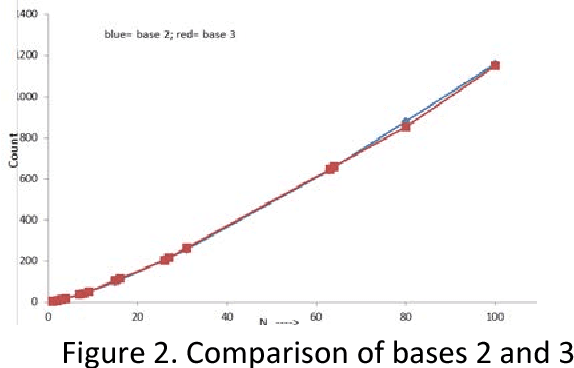
Mathematically, ternary coding is more efficient than binary coding. It is little used in computation because technology for binary processing is already established and the implementation of ternary coding is more complicated, but remains relevant in algorithms that use decision trees and in communications. In this paper we present a new comparison of binary and ternary coding and their relative efficiencies are computed both for number representation and decision trees. The implications of our inability to use optimal representation through mathematics or logic are examined. Apart from considerations of representation efficiency, ternary coding appears preferable to binary coding in classification of many real-world problems of artificial intelligence (AI) and medicine. We examine the problem of identifying appropriate three classes for domain-specific applications.
Order Effects for Queries in Intelligent Systems
Apr 08, 2018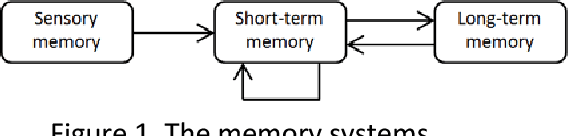

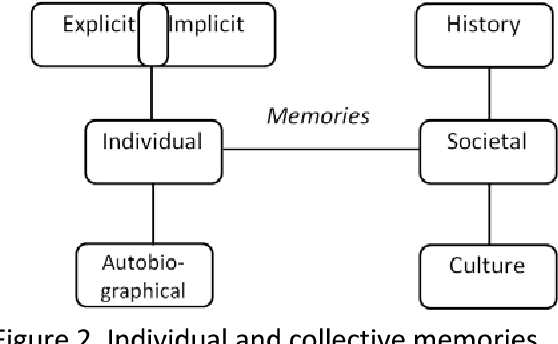
This paper examines common assumptions regarding the decision-making internal environment for intelligent agents and investigates issues related to processing of memory and belief states to help obtain better understanding of the responses. In specific, we consider order effects and discuss both classical and non-classical explanations for them. We also consider implicit cognition and explore if certain inaccessible states may be best modeled as quantum states. We propose that the hypothesis that quantum states are at the basis of order effects be tested on large databases such as those related to medical treatment and drug efficacy. A problem involving a maze network is considered and comparisons made between classical and quantum decision scenarios for it.
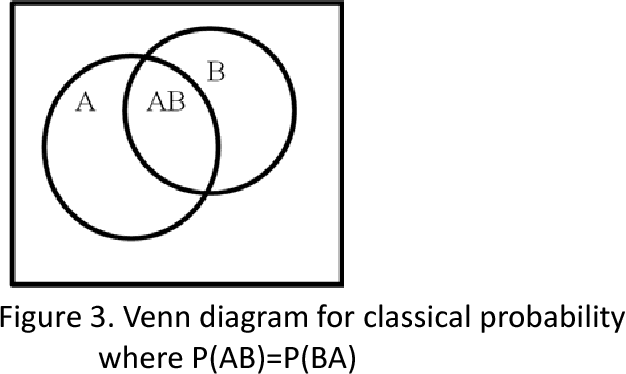
On the Algebra in Boole's Laws of Thought
Mar 13, 2018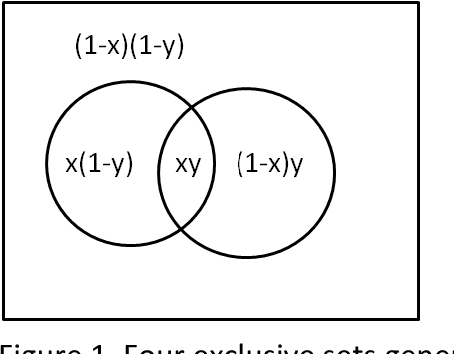
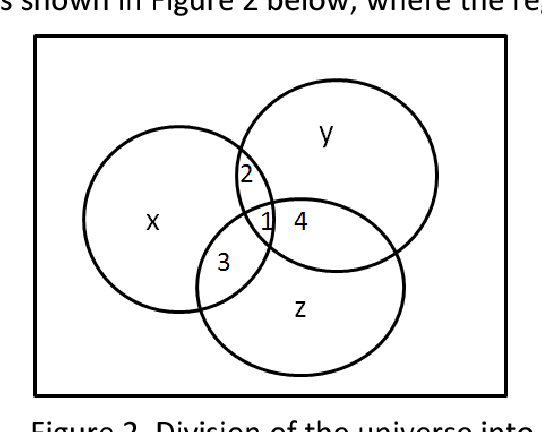
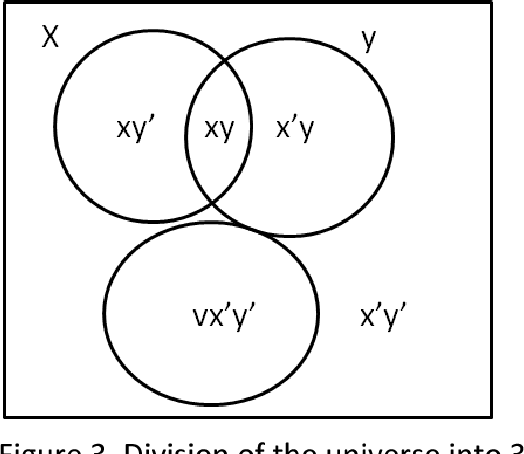
This article explores the ideas that went into George Boole's development of an algebra for logical inference in his book The Laws of Thought. We explore in particular his wife Mary Boole's claim that he was deeply influenced by Indian logic and argue that his work was more than a framework for processing propositions. By exploring parallels between his work and Indian logic, we are able to explain several peculiarities of this work.
Reasoning in a Hierarchical System with Missing Group Size Information
Feb 07, 2018

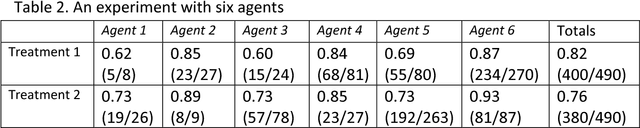
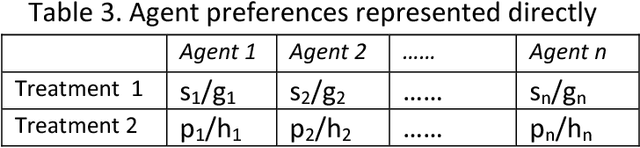
The paper analyzes the problem of judgments or preferences subsequent to initial analysis by autonomous agents in a hierarchical system where the higher level agents does not have access to group size information. We propose methods that reduce instances of preference reversal of the kind encountered in Simpson's paradox.
Learning Based on CC1 and CC4 Neural Networks
Dec 22, 2017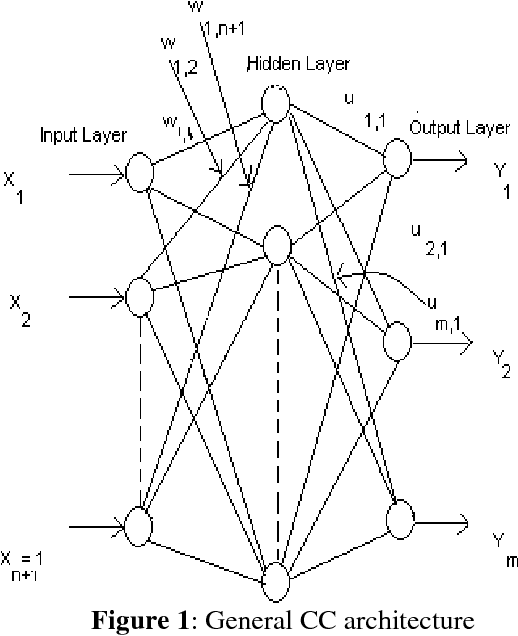
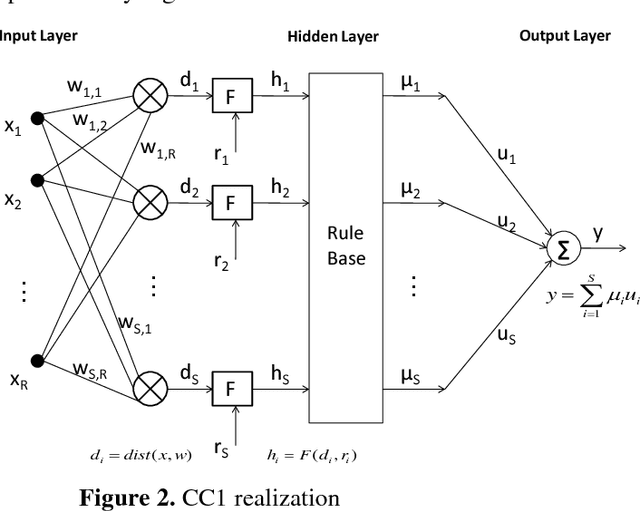
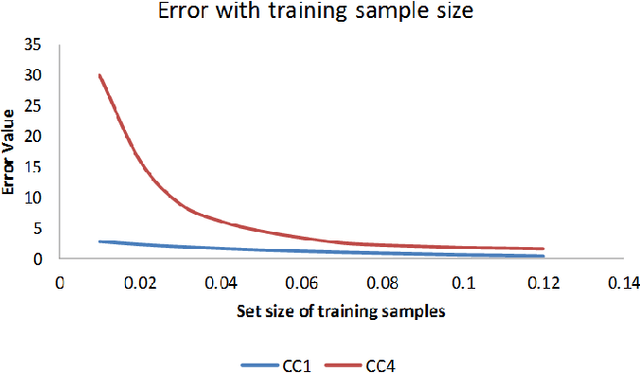
We propose that a general learning system should have three kinds of agents corresponding to sensory, short-term, and long-term memory that implicitly will facilitate context-free and context-sensitive aspects of learning. These three agents perform mututally complementary functions that capture aspects of the human cognition system. We investigate the use of CC1 and CC4 networks for use as models of short-term and sensory memory.
Reasoning in Systems with Elements that Randomly Switch Characteristics
Dec 13, 2017
We examine the issue of stability of probability in reasoning about complex systems with uncertainty in structure. Normally, propositions are viewed as probability functions on an abstract random graph where it is implicitly assumed that the nodes of the graph have stable properties. But what if some of the nodes change their characteristics? This is a situation that cannot be covered by abstractions of either static or dynamic sets when these changes take place at regular intervals. We propose the use of sets with elements that change, and modular forms are proposed to account for one type of such change. An expression for the dependence of the mean on the probability of the switching elements has been determined. The system is also analyzed from the perspective of decision between different hypotheses. Such sets are likely to be of use in complex system queries and in analysis of surveys.
Probability Reversal and the Disjunction Effect in Reasoning Systems
Sep 12, 2017
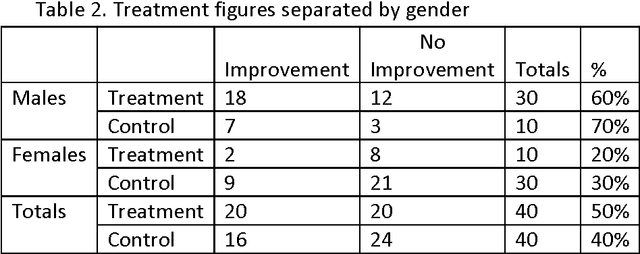
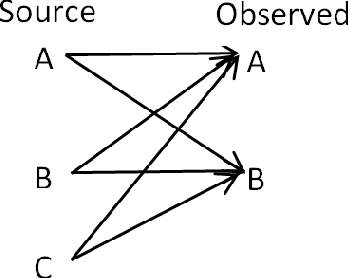
Data based judgments go into artificial intelligence applications but they undergo paradoxical reversal when seemingly unnecessary additional data is provided. Examples of this are Simpson's reversal and the disjunction effect where the beliefs about the data change once it is presented or aggregated differently. Sometimes the significance of the difference can be evaluated using statistical tests such as Pearson's chi-squared or Fisher's exact test, but this may not be helpful in threshold-based decision systems that operate with incomplete information. To mitigate risks in the use of algorithms in decision-making, we consider the question of modeling of beliefs. We argue that evidence supports that beliefs are not classical statistical variables and they should, in the general case, be considered as superposition states of disjoint or polar outcomes. We analyze the disjunction effect from the perspective of the belief as a quantum vector.
On Quantum Decision Trees
Mar 08, 2017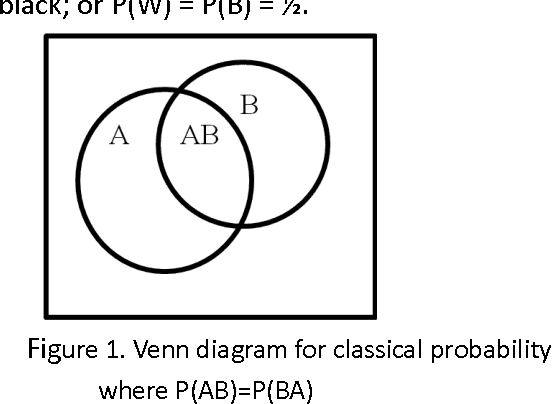
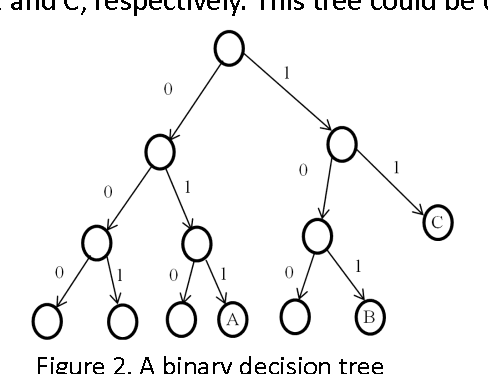
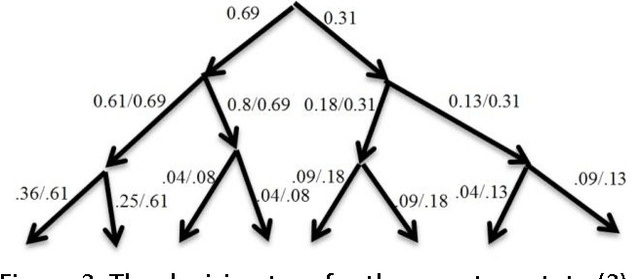
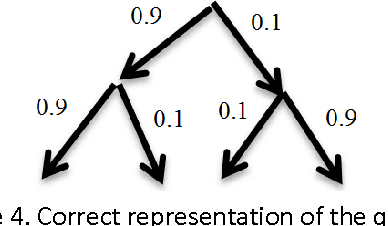
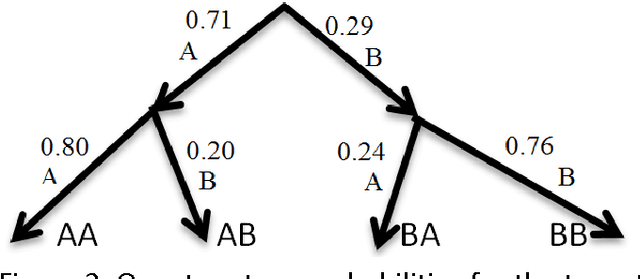
Quantum decision systems are being increasingly considered for use in artificial intelligence applications. Classical and quantum nodes can be distinguished based on certain correlations in their states. This paper investigates some properties of the states obtained in a decision tree structure. How these correlations may be mapped to the decision tree is considered. Classical tree representations and approximations to quantum states are provided.
The Absent-Minded Driver Problem Redux
Feb 19, 2017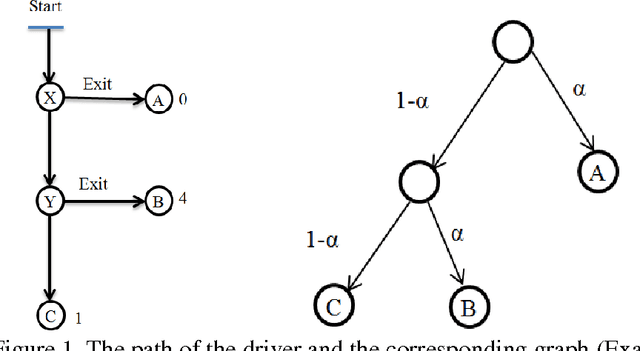
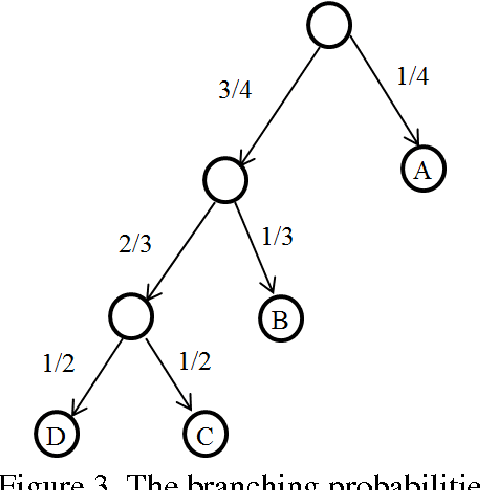
This paper reconsiders the problem of the absent-minded driver who must choose between alternatives with different payoff with imperfect recall and varying degrees of knowledge of the system. The classical absent-minded driver problem represents the case with limited information and it has bearing on the general area of communication and learning, social choice, mechanism design, auctions, theories of knowledge, belief, and rational agency. Within the framework of extensive games, this problem has applications to many artificial intelligence scenarios. It is obvious that the performance of the agent improves as information available increases. It is shown that a non-uniform assignment strategy for successive choices does better than a fixed probability strategy. We consider both classical and quantum approaches to the problem. We argue that the superior performance of quantum decisions with access to entanglement cannot be fairly compared to a classical algorithm. If the cognitive systems of agents are taken to have access to quantum resources, or have a quantum mechanical basis, then that can be leveraged into superior performance.
Spread Unary Coding
Dec 02, 2014
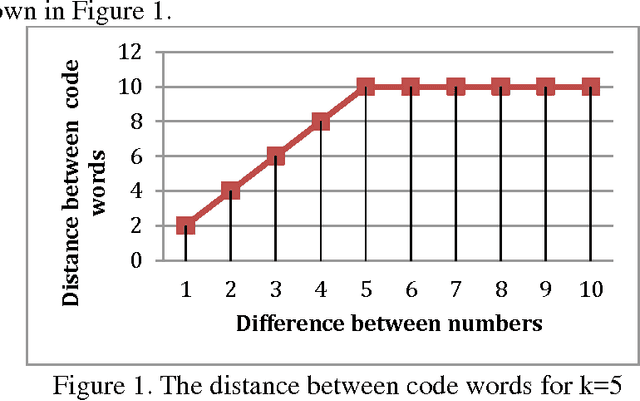

Unary coding is useful but it is redundant in its standard form. Unary coding can also be seen as spatial coding where the value of the number is determined by its place in an array. Motivated by biological finding that several neurons in the vicinity represent the same number, we propose a variant of unary numeration in its spatial form, where each number is represented by several 1s. We call this spread unary coding where the number of 1s used is the spread of the code. Spread unary coding is associated with saturation of the Hamming distance between code words.