 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks using SAT solvers
Jun 10, 2022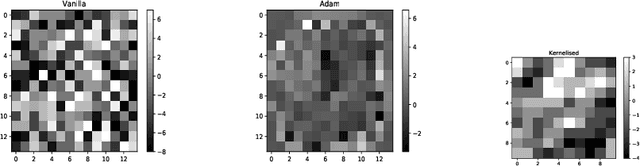
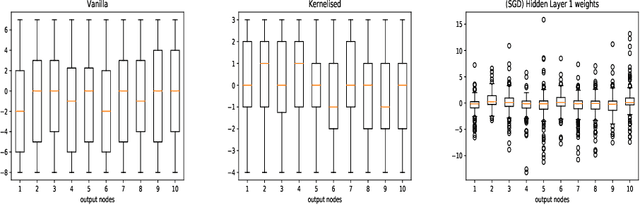
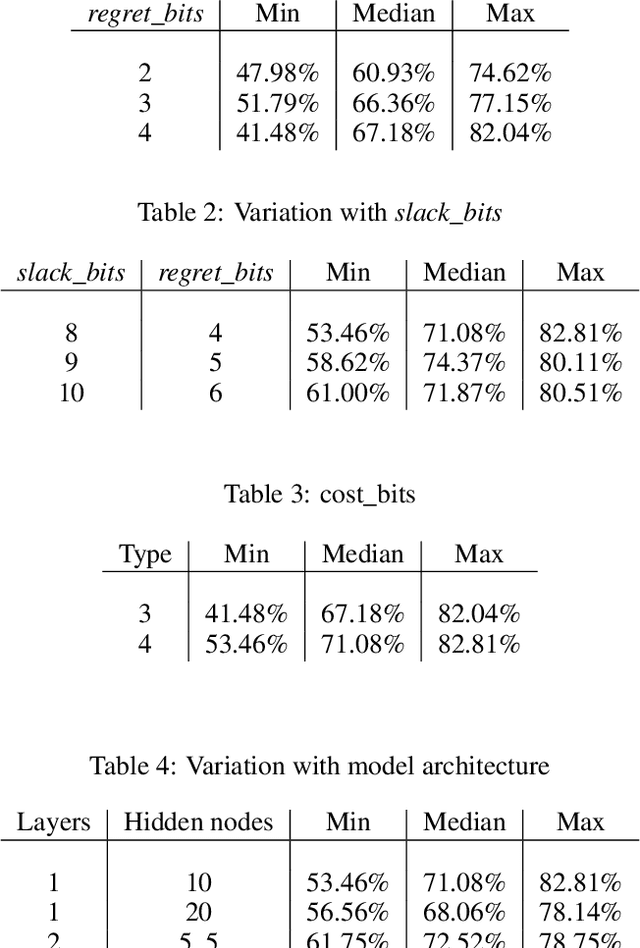
We propose an algorithm to explore the global optimization method, using SAT solvers, for training a neural net. Deep Neural Networks have achieved great feats in tasks like-image recognition, speech recognition, etc. Much of their success can be attributed to the gradient-based optimisation methods, which scale well to huge datasets while still giving solutions, better than any other existing methods. However, there exist learning problems like the parity function and the Fast Fourier Transform, where a neural network using gradient-based optimisation algorithm can not capture the underlying structure of the learning task properly. Thus, exploring global optimisation methods is of utmost interest as the gradient-based methods get stuck in local optima. In the experiments, we demonstrate the effectiveness of our algorithm against the ADAM optimiser in certain tasks like parity learning. However, in the case of image classification on the MNIST Dataset, the performance of our algorithm was less than satisfactory. We further discuss the role of the size of the training dataset and the hyper-parameter settings in keeping things scalable for a SAT solver.
Learning Equations for Extrapolation and Control
Jun 19, 2018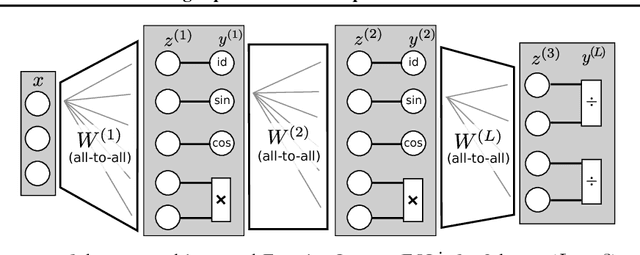
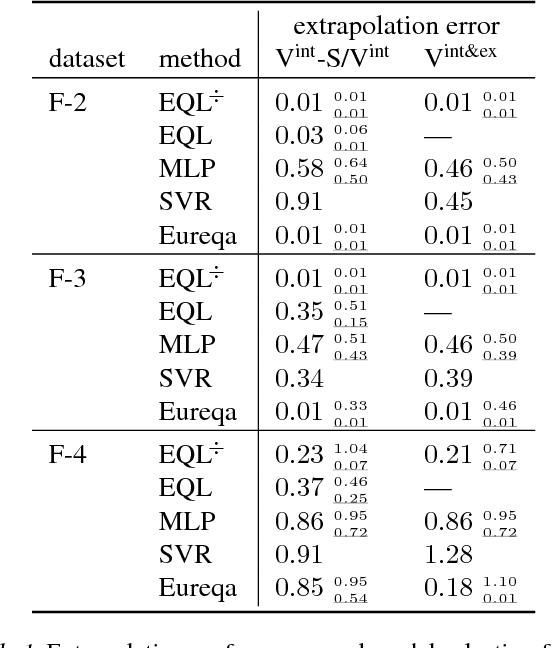
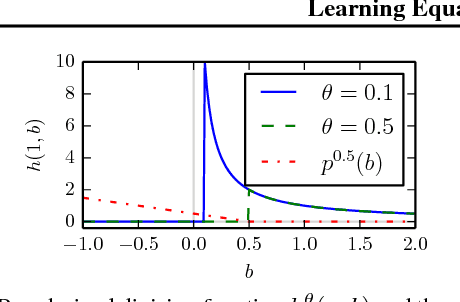

We present an approach to identify concise equations from data using a shallow neural network approach. In contrast to ordinary black-box regression, this approach allows understanding functional relations and generalizing them from observed data to unseen parts of the parameter space. We show how to extend the class of learnable equations for a recently proposed equation learning network to include divisions, and we improve the learning and model selection strategy to be useful for challenging real-world data. For systems governed by analytical expressions, our method can in many cases identify the true underlying equation and extrapolate to unseen domains. We demonstrate its effectiveness by experiments on a cart-pendulum system, where only 2 random rollouts are required to learn the forward dynamics and successfully achieve the swing-up task.