 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Characterization of Non-Uniformly Sampled Time Series using Stochastic Differential Equations
Jul 02, 2020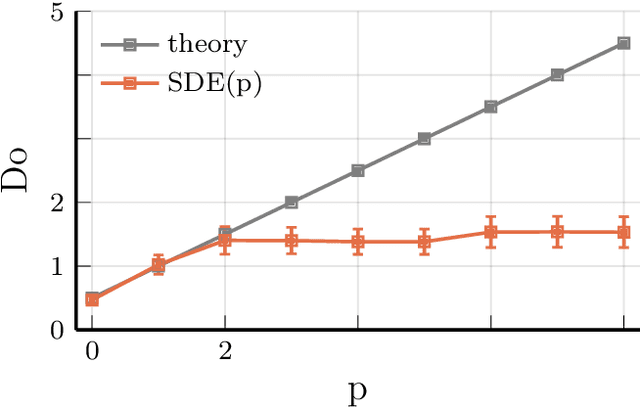
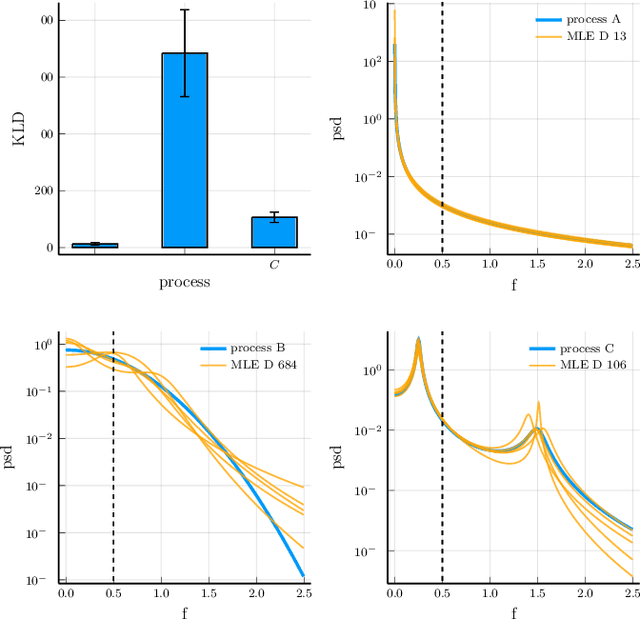
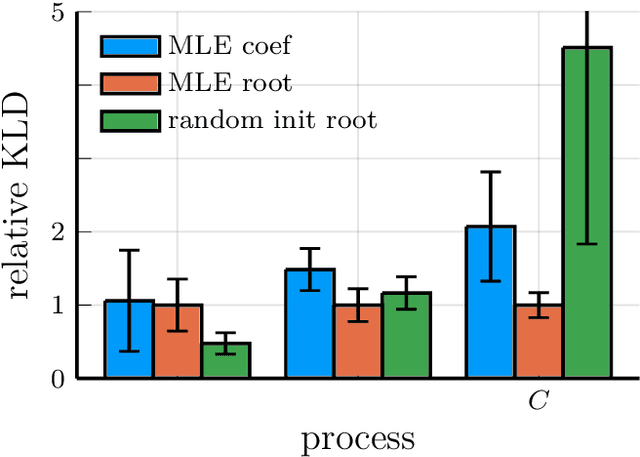
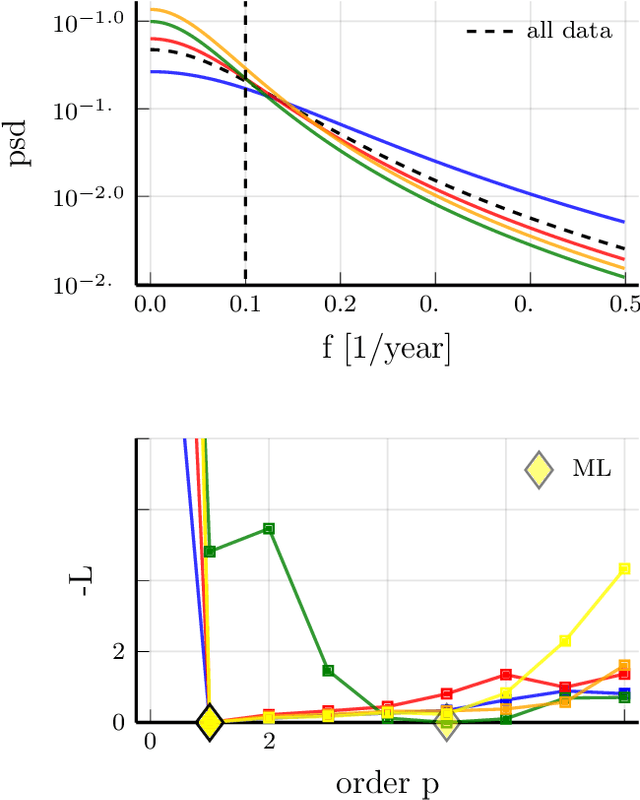
Non-uniform sampling arises when an experimenter does not have full control over the sampling characteristics of the process under investigation. Moreover, it is introduced intentionally in algorithms such as Bayesian optimization and compressive sensing. We argue that Stochastic Differential Equations (SDEs) are especially well-suited for characterizing second order moments of such time series. We introduce new initial estimates for the numerical optimization of the likelihood, based on incremental estimation and initialization from autoregressive models. Furthermore, we introduce model truncation as a purely data-driven method to reduce the order of the estimated model based on the SDE likelihood. We show the increased accuracy achieved with the new estimator in simulation experiments, covering all challenging circumstances that may be encountered in characterizing a non-uniformly sampled time series. Finally, we apply the new estimator to experimental rainfall variability data.
Accurate Kernel Learning for Linear Gaussian Markov Processes using a Scalable Likelihood Computation
May 18, 2018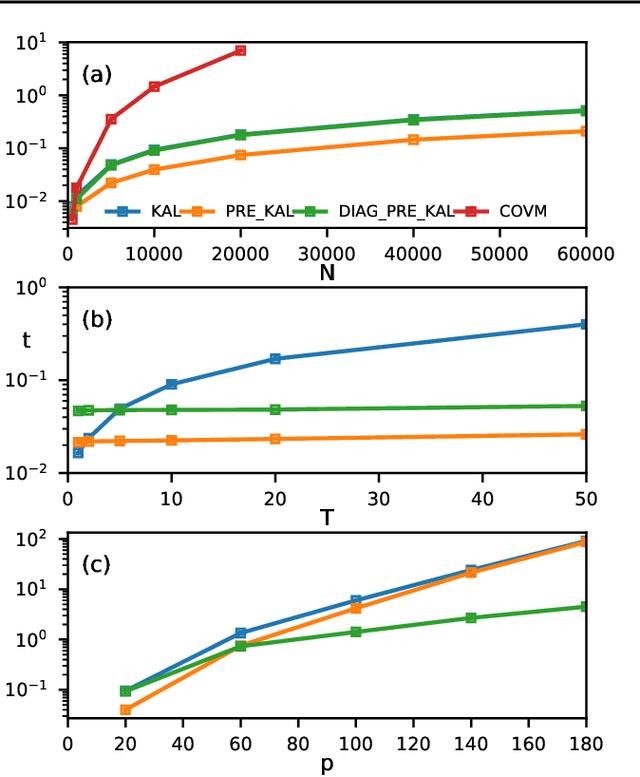
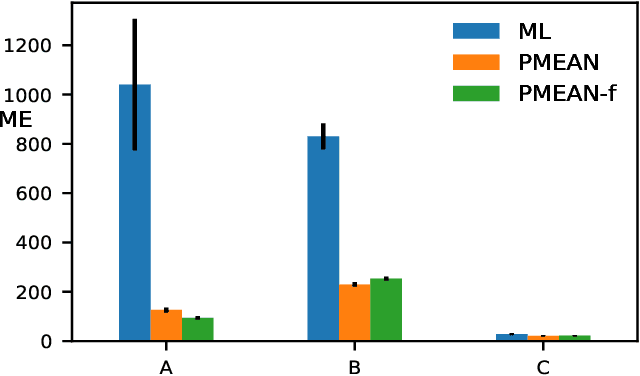
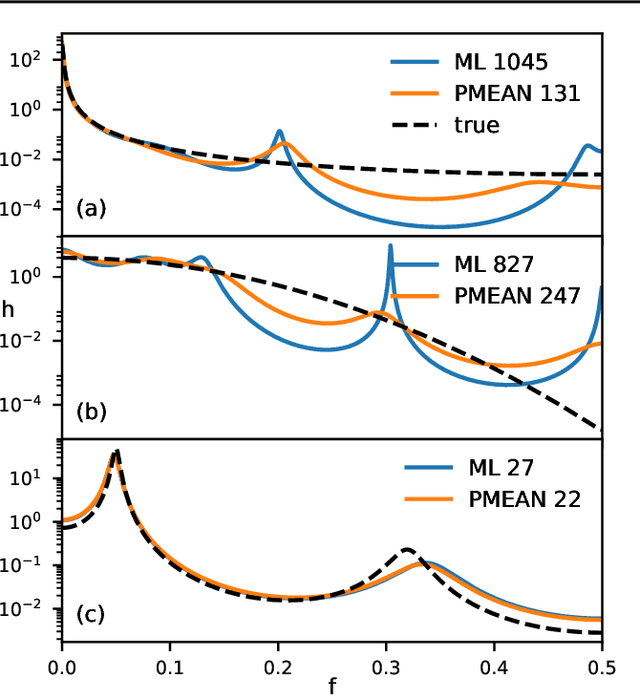
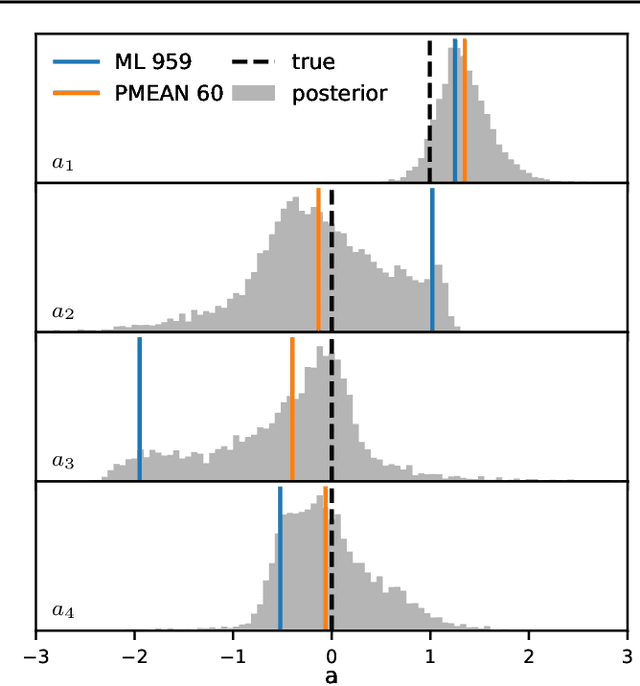
We report an exact likelihood computation for Linear Gaussian Markov processes that is more scalable than existing algorithms for complex models and sparsely sampled signals. Better scaling is achieved through elimination of repeated computations in the Kalman likelihood, and by using the diagonalized form of the state transition equation. Using this efficient computation, we study the accuracy of kernel learning using maximum likelihood and the posterior mean in a simulation experiment. The posterior mean with a reference prior is more accurate for complex models and sparse sampling. Because of its lower computation load, the maximum likelihood estimator is an attractive option for more densely sampled signals and lower order models. We confirm estimator behavior in experimental data through their application to speleothem data.