 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenPalm: Contactless Palmprint Generation with Diffusion Models
Jun 01, 2024



The scarcity of large-scale palmprint databases poses a significant bottleneck to advancements in contactless palmprint recognition. To address this, researchers have turned to synthetic data generation. While Generative Adversarial Networks (GANs) have been widely used, they suffer from instability and mode collapse. Recently, diffusion probabilistic models have emerged as a promising alternative, offering stable training and better distribution coverage. This paper introduces a novel palmprint generation method using diffusion probabilistic models, develops an end-to-end framework for synthesizing multiple palm identities, and validates the realism and utility of the generated palmprints. Experimental results demonstrate the effectiveness of our approach in generating palmprint images which enhance contactless palmprint recognition performance across several test databases utilizing challenging cross-database and time-separated evaluation protocols.
Universal Fingerprint Generation: Controllable Diffusion Model with Multimodal Conditions
Apr 21, 2024



The utilization of synthetic data for fingerprint recognition has garnered increased attention due to its potential to alleviate privacy concerns surrounding sensitive biometric data. However, current methods for generating fingerprints have limitations in creating impressions of the same finger with useful intra-class variations. To tackle this challenge, we present GenPrint, a framework to produce fingerprint images of various types while maintaining identity and offering humanly understandable control over different appearance factors such as fingerprint class, acquisition type, sensor device, and quality level. Unlike previous fingerprint generation approaches, GenPrint is not confined to replicating style characteristics from the training dataset alone: it enables the generation of novel styles from unseen devices without requiring additional fine-tuning. To accomplish these objectives, we developed GenPrint using latent diffusion models with multimodal conditions (text and image) for consistent generation of style and identity. Our experiments leverage a variety of publicly available datasets for training and evaluation. Results demonstrate the benefits of GenPrint in terms of identity preservation, explainable control, and universality of generated images. Importantly, the GenPrint-generated images yield comparable or even superior accuracy to models trained solely on real data and further enhances performance when augmenting the diversity of existing real fingerprint datasets.
Mobile Contactless Palmprint Recognition: Use of Multiscale, Multimodel Embeddings
Jan 16, 2024



Contactless palmprints are comprised of both global and local discriminative features. Most prior work focuses on extracting global features or local features alone for palmprint matching, whereas this research introduces a novel framework that combines global and local features for enhanced palmprint matching accuracy. Leveraging recent advancements in deep learning, this study integrates a vision transformer (ViT) and a convolutional neural network (CNN) to extract complementary local and global features. Next, a mobile-based, end-to-end palmprint recognition system is developed, referred to as Palm-ID. On top of the ViT and CNN features, Palm-ID incorporates a palmprint enhancement module and efficient dimensionality reduction (for faster matching). Palm-ID balances the trade-off between accuracy and latency, requiring just 18ms to extract a template of size 516 bytes, which can be efficiently searched against a 10,000 palmprint gallery in 0.33ms on an AMD EPYC 7543 32-Core CPU utilizing 128-threads. Cross-database matching protocols and evaluations on large-scale operational datasets demonstrate the robustness of the proposed method, achieving a TAR of 98.06% at FAR=0.01% on a newly collected, time-separated dataset. To show a practical deployment of the end-to-end system, the entire recognition pipeline is embedded within a mobile device for enhanced user privacy and security.
ViT Unified: Joint Fingerprint Recognition and Presentation Attack Detection
May 12, 2023



A secure fingerprint recognition system must contain both a presentation attack (i.e., spoof) detection and recognition module in order to protect users against unwanted access by malicious users. Traditionally, these tasks would be carried out by two independent systems; however, recent studies have demonstrated the potential to have one unified system architecture in order to reduce the computational burdens on the system, while maintaining high accuracy. In this work, we leverage a vision transformer architecture for joint spoof detection and matching and report competitive results with state-of-the-art (SOTA) models for both a sequential system (two ViT models operating independently) and a unified architecture (a single ViT model for both tasks). ViT models are particularly well suited for this task as the ViT's global embedding encodes features useful for recognition, whereas the individual, local embeddings are useful for spoof detection. We demonstrate the capability of our unified model to achieve an average integrated matching (IM) accuracy of 98.87% across LivDet 2013 and 2015 CrossMatch sensors. This is comparable to IM accuracy of 98.95% of our sequential dual-ViT system, but with ~50% of the parameters and ~58% of the latency.
Child Palm-ID: Contactless Palmprint Recognition for Children
May 09, 2023



Effective distribution of nutritional and healthcare aid for children, particularly infants and toddlers, in some of the least developed and most impoverished countries of the world, is a major problem due to the lack of reliable identification documents. Biometric authentication technology has been investigated to address child recognition in the absence of reliable ID documents. We present a mobile-based contactless palmprint recognition system, called Child Palm-ID, which meets the requirements of usability, hygiene, cost, and accuracy for child recognition. Using a contactless child palmprint database, Child-PalmDB1, consisting of 19,158 images from 1,020 unique palms (in the age range of 6 mos. to 48 mos.), we report a TAR=94.11% @ FAR=0.1%. The proposed Child Palm-ID system is also able to recognize adults, achieving a TAR=99.4% on the CASIA contactless palmprint database and a TAR=100% on the COEP contactless adult palmprint database, both @ FAR=0.1%. These accuracies are competitive with the SOTA provided by COTS systems. Despite these high accuracies, we show that the TAR for time-separated child-palmprints is only 78.1% @ FAR=0.1%.
Latent Fingerprint Recognition: Fusion of Local and Global Embeddings
Apr 26, 2023



One of the most challenging problems in fingerprint recognition continues to be establishing the identity of a suspect associated with partial and smudgy fingerprints left at a crime scene (i.e., latent prints or fingermarks). Despite the success of fixed-length embeddings for rolled and slap fingerprint recognition, the features learned for latent fingerprint matching have mostly been limited to local minutiae-based embeddings and have not directly leveraged global representations for matching. In this paper, we combine global embeddings with local embeddings for state-of-the-art latent to rolled matching accuracy with high throughput. The combination of both local and global representations leads to improved recognition accuracy across NIST SD 27, NIST SD 302, MSP, MOLF DB1/DB4, and MOLF DB2/DB4 latent fingerprint datasets for both closed-set (84.11%, 54.36%, 84.35%, 70.43%, 62.86% rank-1 retrieval rate, respectively) and open-set (0.50, 0.74, 0.44, 0.60, 0.68 FNIR at FPIR=0.02, respectively) identification scenarios on a gallery of 100K rolled fingerprints. Not only do we fuse the complimentary representations, we also use the local features to guide the global representations to focus on discriminatory regions in two fingerprint images to be compared. This leads to a multi-stage matching paradigm in which subsets of the retrieved candidate lists for each probe image are passed to subsequent stages for further processing, resulting in a considerable reduction in latency (requiring just 0.068 ms per latent to rolled comparison on a AMD EPYC 7543 32-Core Processor, roughly 15K comparisons per second). Finally, we show the generalizability of the fused representations for improving authentication accuracy across several rolled, plain, and contactless fingerprint datasets.
AFR-Net: Attention-Driven Fingerprint Recognition Network
Dec 03, 2022



The use of vision transformers (ViT) in computer vision is increasing due to limited inductive biases (e.g., locality, weight sharing, etc.) and increased scalability compared to other deep learning methods. This has led to some initial studies on the use of ViT for biometric recognition, including fingerprint recognition. In this work, we improve on these initial studies for transformers in fingerprint recognition by i.) evaluating additional attention-based architectures, ii.) scaling to larger and more diverse training and evaluation datasets, and iii.) combining the complimentary representations of attention-based and CNN-based embeddings for improved state-of-the-art (SOTA) fingerprint recognition (both authentication and identification). Our combined architecture, AFR-Net (Attention-Driven Fingerprint Recognition Network), outperforms several baseline transformer and CNN-based models, including a SOTA commercial fingerprint system, Verifinger v12.3, across intra-sensor, cross-sensor, and latent to rolled fingerprint matching datasets. Additionally, we propose a realignment strategy using local embeddings extracted from intermediate feature maps within the networks to refine the global embeddings in low certainty situations, which boosts the overall recognition accuracy significantly across each of the models. This realignment strategy requires no additional training and can be applied as a wrapper to any existing deep learning network (including attention-based, CNN-based, or both) to boost its performance.
Minutiae-Guided Fingerprint Embeddings via Vision Transformers
Oct 26, 2022



Minutiae matching has long dominated the field of fingerprint recognition. However, deep networks can be used to extract fixed-length embeddings from fingerprints. To date, the few studies that have explored the use of CNN architectures to extract such embeddings have shown extreme promise. Inspired by these early works, we propose the first use of a Vision Transformer (ViT) to learn a discriminative fixed-length fingerprint embedding. We further demonstrate that by guiding the ViT to focus in on local, minutiae related features, we can boost the recognition performance. Finally, we show that by fusing embeddings learned by CNNs and ViTs we can reach near parity with a commercial state-of-the-art (SOTA) matcher. In particular, we obtain a TAR=94.23% @ FAR=0.1% on the NIST SD 302 public-domain dataset, compared to a SOTA commercial matcher which obtains TAR=96.71% @ FAR=0.1%. Additionally, our fixed-length embeddings can be matched orders of magnitude faster than the commercial system (2.5 million matches/second compared to 50K matches/second). We make our code and models publicly available to encourage further research on this topic: https://github.com/tba.
On Demographic Bias in Fingerprint Recognition
May 19, 2022
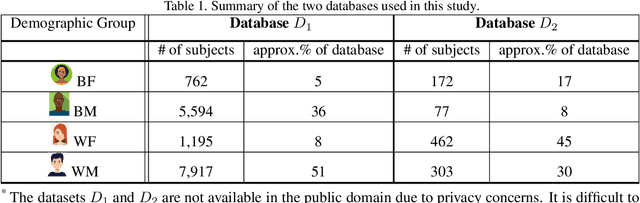
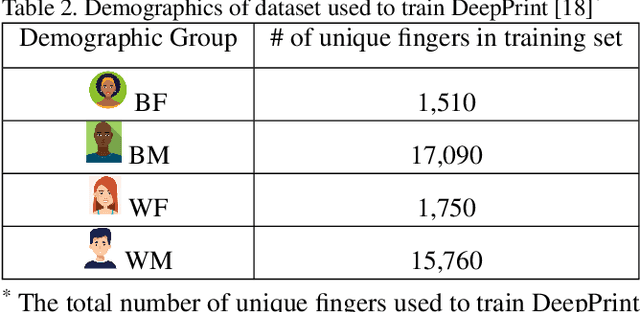
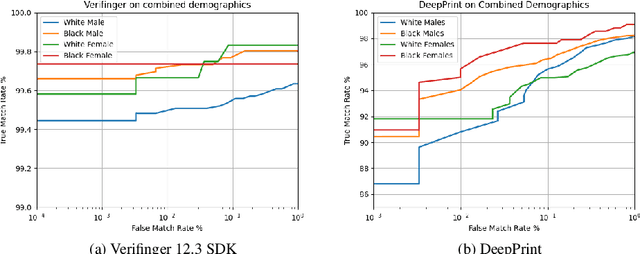
Fingerprint recognition systems have been deployed globally in numerous applications including personal devices, forensics, law enforcement, banking, and national identity systems. For these systems to be socially acceptable and trustworthy, it is critical that they perform equally well across different demographic groups. In this work, we propose a formal statistical framework to test for the existence of bias (demographic differentials) in fingerprint recognition across four major demographic groups (white male, white female, black male, and black female) for two state-of-the-art (SOTA) fingerprint matchers operating in verification and identification modes. Experiments on two different fingerprint databases (with 15,468 and 1,014 subjects) show that demographic differentials in SOTA fingerprint recognition systems decrease as the matcher accuracy increases and any small bias that may be evident is likely due to certain outlier, low-quality fingerprint images.
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022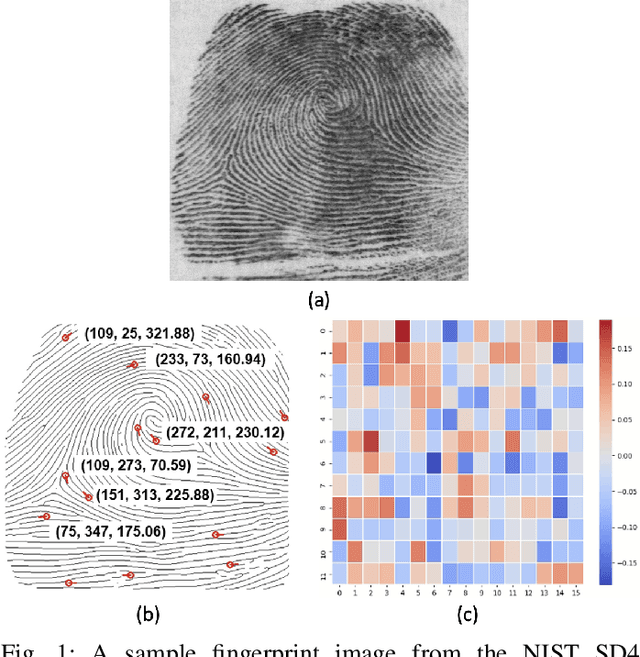

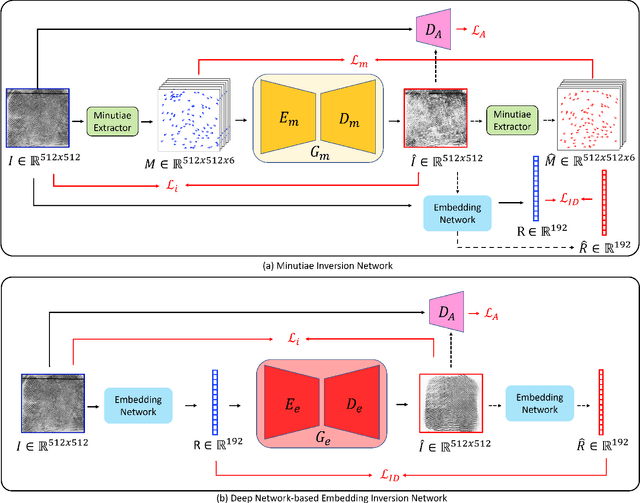

Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.