 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Work of Art in an Age of Mechanical Generation
Jan 27, 2021Can we define what it means to be "creative," and if so, can our definition drive artificial intelligence (AI) systems to feats of creativity indistinguishable from human efforts? This mixed question is considered from technological and social perspectives. Beginning with an exploration of the value we attach to authenticity in works of art, the article considers the ability of AI to detect forgeries of renowned paintings and, in so doing, somehow reveal the quiddity of a work of art. We conclude by considering whether evolving technical capability can revise traditional relationships among art, artist, and the market.
A Neural Network Looks at Leonardo's Salvator Mundi
May 21, 2020


We use convolutional neural networks (CNNs) to analyze authorship questions surrounding the works of Leonardo da Vinci -- in particular, Salvator Mundi, the world's most expensive painting and among the most controversial. Trained on the works of an artist under study and visually comparable works of other artists, our system can identify likely forgeries and shed light on attribution controversies. Leonardo's few extant paintings test the limits of our system and require corroborative techniques of testing and analysis.
Image Entropy for Classification and Analysis of Pathology Slides
Feb 16, 2020Pathology slides of lung malignancies are classified using the "Salient Slices" technique described in Frank et al., 2020. A four-fold cross-validation study using a small image set (42 adenocarcinoma slides and 42 squamous cell carcinoma slides) produced fully correct classifications in each fold. Probability maps enable visualization of the underlying basis for a classification.
Rembrandts and Robots: Using Neural Networks to Explore Authorship in Painting
Feb 12, 2020



We use convolutional neural networks to analyze authorship questions surrounding works of representational art. Trained on the works of an artist under study and visually comparable works of other artists, our system can identify forgeries and provide attributions. Our system can also assign classification probabilities within a painting, revealing mixed authorship and identifying regions painted by different hands.
Salient Slices: Improved Neural Network Training and Performance with Image Entropy
Jul 29, 2019

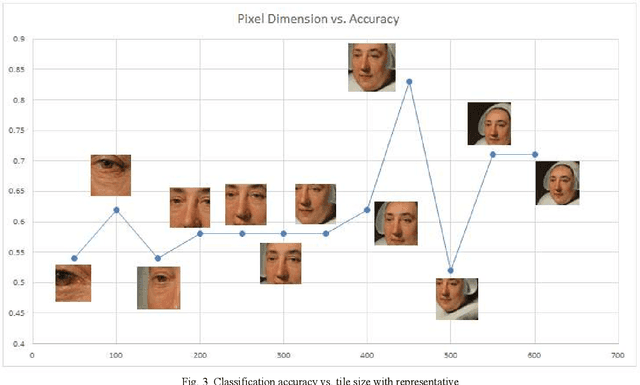

As a training and analysis strategy for convolutional neural networks (CNNs), we slice images into tiled segments and use, for training and prediction, segments that both satisfy a criterion of information diversity and contain sufficient content to support classification. In particular, we utilize image entropy as the diversity criterion. This ensures that each tile carries as much information diversity as the original image, and for many applications serves as an indicator of usefulness in classification. To make predictions, a probability aggregation framework is applied to probabilities assigned by the CNN to the input image tiles. This technique facilitates the use of large, high-resolution images that would be impractical to analyze unmodified; provides data augmentation for training, which is particularly valuable when image availability is limited; and the ensemble nature of the input for prediction enhances its accuracy.