 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual interpretation of transient image classifications from large language models
Oct 08, 2025Modern astronomical surveys deliver immense volumes of transient detections, yet distinguishing real astrophysical signals (for example, explosive events) from bogus imaging artefacts remains a challenge. Convolutional neural networks are effectively used for real versus bogus classification; however, their reliance on opaque latent representations hinders interpretability. Here we show that large language models (LLMs) can approach the performance level of a convolutional neural network on three optical transient survey datasets (Pan-STARRS, MeerLICHT and ATLAS) while simultaneously producing direct, human-readable descriptions for every candidate. Using only 15 examples and concise instructions, Google's LLM, Gemini, achieves a 93% average accuracy across datasets that span a range of resolution and pixel scales. We also show that a second LLM can assess the coherence of the output of the first model, enabling iterative refinement by identifying problematic cases. This framework allows users to define the desired classification behaviour through natural language and examples, bypassing traditional training pipelines. Furthermore, by generating textual descriptions of observed features, LLMs enable users to query classifications as if navigating an annotated catalogue, rather than deciphering abstract latent spaces. As next-generation telescopes and surveys further increase the amount of data available, LLM-based classification could help bridge the gap between automated detection and transparent, human-level understanding.
MeerCRAB: MeerLICHT Classification of Real and Bogus Transients using Deep Learning
Apr 28, 2021

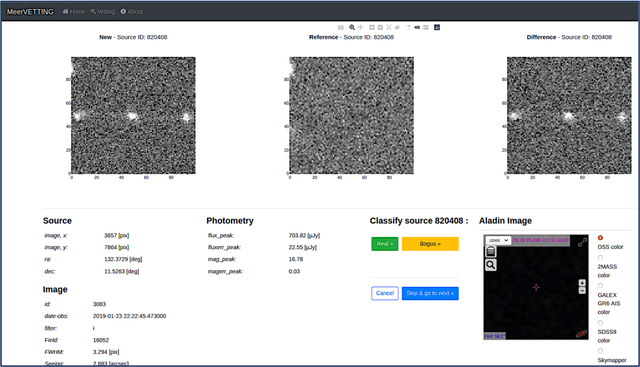
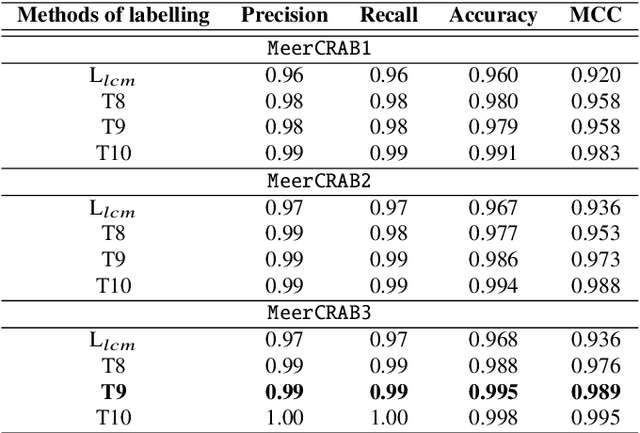
Astronomers require efficient automated detection and classification pipelines when conducting large-scale surveys of the (optical) sky for variable and transient sources. Such pipelines are fundamentally important, as they permit rapid follow-up and analysis of those detections most likely to be of scientific value. We therefore present a deep learning pipeline based on the convolutional neural network architecture called $\texttt{MeerCRAB}$. It is designed to filter out the so called 'bogus' detections from true astrophysical sources in the transient detection pipeline of the MeerLICHT telescope. Optical candidates are described using a variety of 2D images and numerical features extracted from those images. The relationship between the input images and the target classes is unclear, since the ground truth is poorly defined and often the subject of debate. This makes it difficult to determine which source of information should be used to train a classification algorithm. We therefore used two methods for labelling our data (i) thresholding and (ii) latent class model approaches. We deployed variants of $\texttt{MeerCRAB}$ that employed different network architectures trained using different combinations of input images and training set choices, based on classification labels provided by volunteers. The deepest network worked best with an accuracy of 99.5$\%$ and Matthews correlation coefficient (MCC) value of 0.989. The best model was integrated to the MeerLICHT transient vetting pipeline, enabling the accurate and efficient classification of detected transients that allows researchers to select the most promising candidates for their research goals.