 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Open Language Archives Community and Asian Language Resources
Oct 03, 2001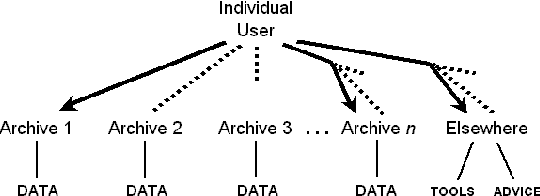
The Open Language Archives Community (OLAC) is a new project to build a worldwide system of federated language archives based on the Open Archives Initiative and the Dublin Core Metadata Initiative. This paper aims to disseminate the OLAC vision to the language resources community in Asia, and to show language technologists and linguists how they can document their tools and data in such a way that others can easily discover them. We describe OLAC and the OLAC Metadata Set, then discuss two key issues in the Asian context: language classification and multilingual resource classification.
* 8 pages, 2 figures
The OLAC Metadata Set and Controlled Vocabularies
May 21, 2001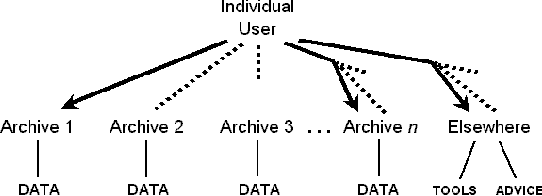
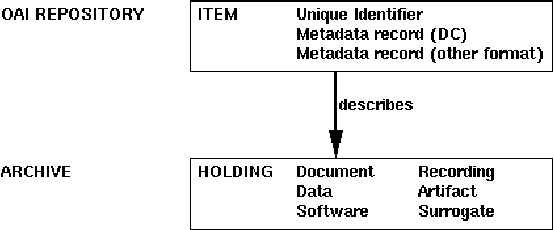
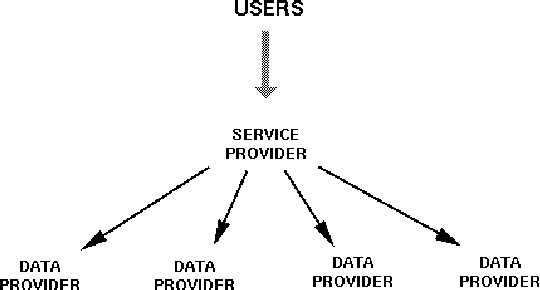
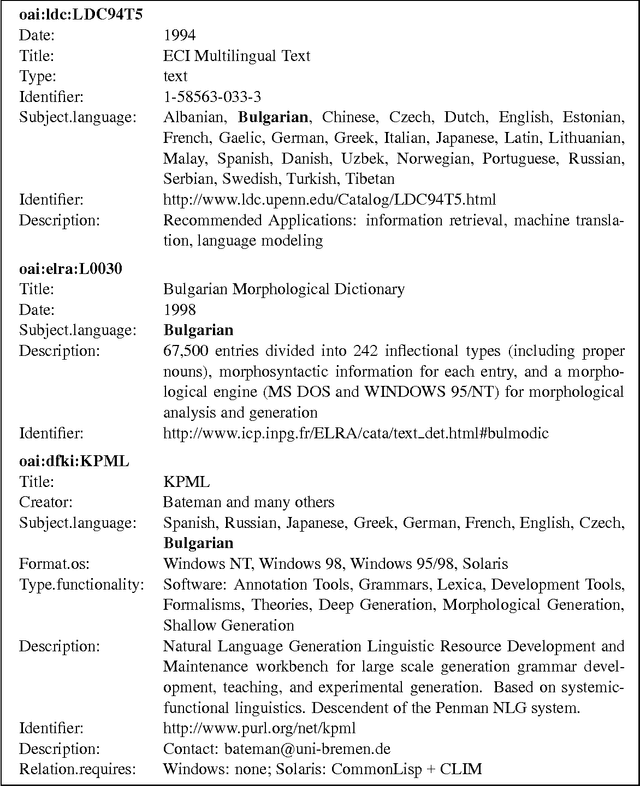
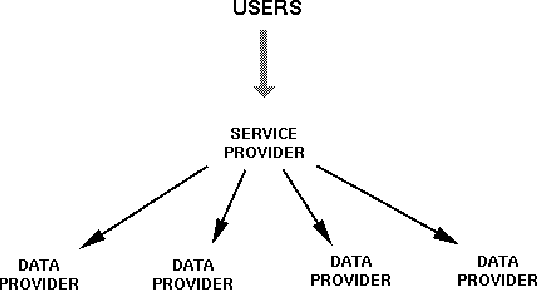
As language data and associated technologies proliferate and as the language resources community rapidly expands, it has become difficult to locate and reuse existing resources. Are there any lexical resources for such-and-such a language? What tool can work with transcripts in this particular format? What is a good format to use for linguistic data of this type? Questions like these dominate many mailing lists, since web search engines are an unreliable way to find language resources. This paper describes a new digital infrastructure for language resource discovery, based on the Open Archives Initiative, and called OLAC -- the Open Language Archives Community. The OLAC Metadata Set and the associated controlled vocabularies facilitate consistent description and focussed searching. We report progress on the metadata set and controlled vocabularies, describing current issues and soliciting input from the language resources community.
* 12 pages, 5 figures
A Formal Framework for Linguistic Annotation (revised version)
Oct 26, 2000


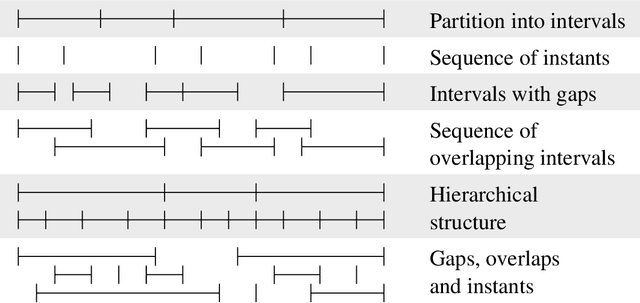
`Linguistic annotation' covers any descriptive or analytic notations applied to raw language data. The basic data may be in the form of time functions - audio, video and/or physiological recordings - or it may be textual. The added notations may include transcriptions of all sorts (from phonetic features to discourse structures), part-of-speech and sense tagging, syntactic analysis, `named entity' identification, co-reference annotation, and so on. While there are several ongoing efforts to provide formats and tools for such annotations and to publish annotated linguistic databases, the lack of widely accepted standards is becoming a critical problem. Proposed standards, to the extent they exist, have focused on file formats. This paper focuses instead on the logical structure of linguistic annotations. We survey a wide variety of existing annotation formats and demonstrate a common conceptual core, the annotation graph. This provides a formal framework for constructing, maintaining and searching linguistic annotations, while remaining consistent with many alternative data structures and file formats.
Many uses, many annotations for large speech corpora: Switchboard and TDT as case studies
Jul 13, 2000
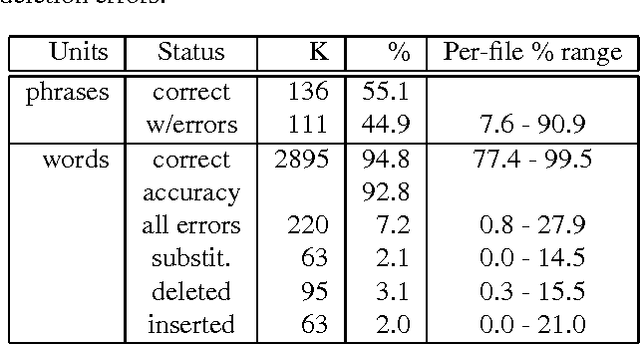
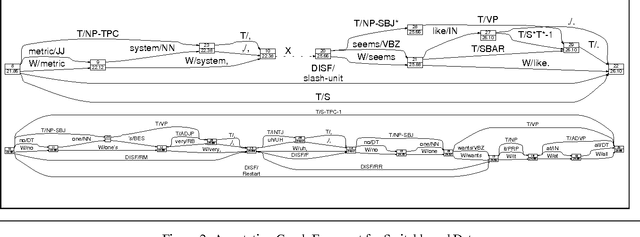
This paper discusses the challenges that arise when large speech corpora receive an ever-broadening range of diverse and distinct annotations. Two case studies of this process are presented: the Switchboard Corpus of telephone conversations and the TDT2 corpus of broadcast news. Switchboard has undergone two independent transcriptions and various types of additional annotation, all carried out as separate projects that were dispersed both geographically and chronologically. The TDT2 corpus has also received a variety of annotations, but all directly created or managed by a core group. In both cases, issues arise involving the propagation of repairs, consistency of references, and the ability to integrate annotations having different formats and levels of detail. We describe a general framework whereby these issues can be addressed successfully.
* 7 pages, 2 figures
Towards a query language for annotation graphs
Jul 13, 2000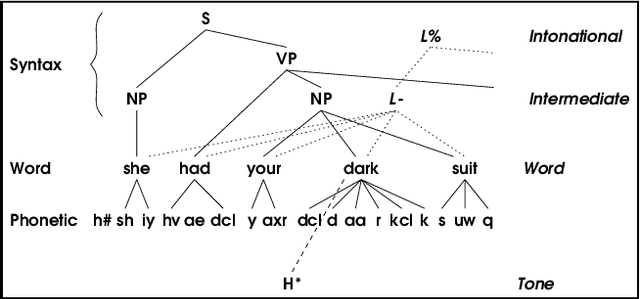
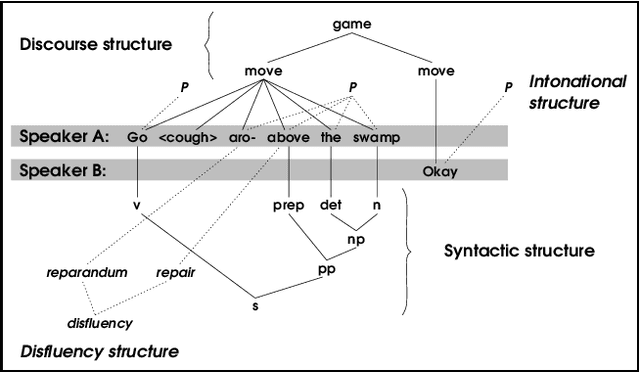

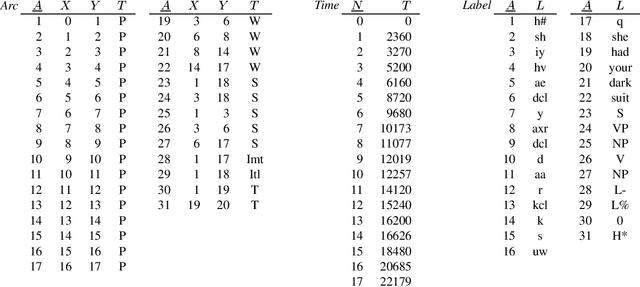
The multidimensional, heterogeneous, and temporal nature of speech databases raises interesting challenges for representation and query. Recently, annotation graphs have been proposed as a general-purpose representational framework for speech databases. Typical queries on annotation graphs require path expressions similar to those used in semistructured query languages. However, the underlying model is rather different from the customary graph models for semistructured data: the graph is acyclic and unrooted, and both temporal and inclusion relationships are important. We develop a query language and describe optimization techniques for an underlying relational representation.
* 8 pages, 10 figures
ATLAS: A flexible and extensible architecture for linguistic annotation
Jul 13, 2000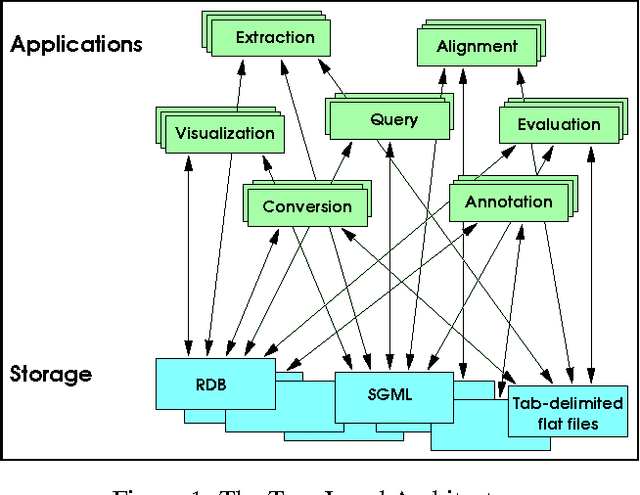
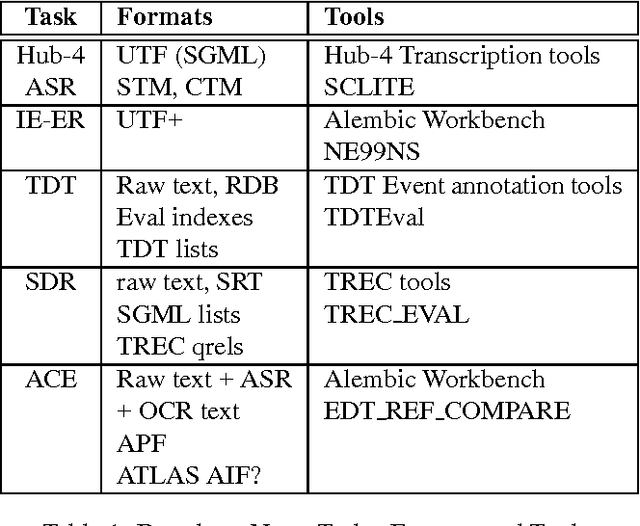
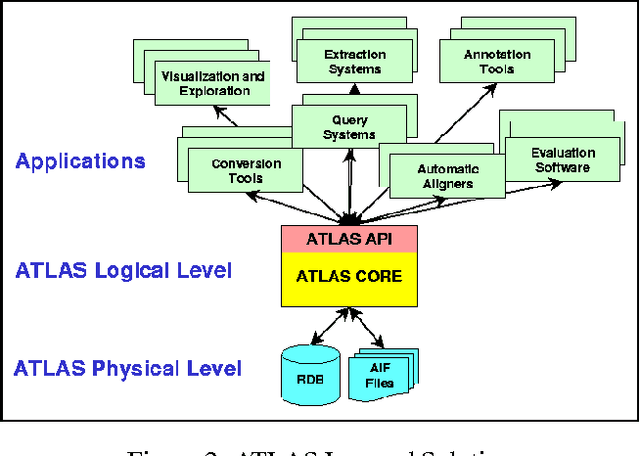
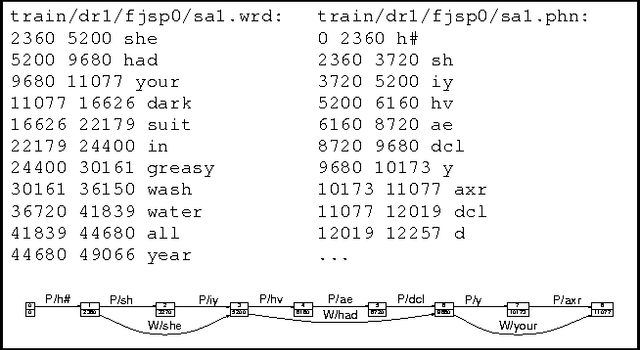
We describe a formal model for annotating linguistic artifacts, from which we derive an application programming interface (API) to a suite of tools for manipulating these annotations. The abstract logical model provides for a range of storage formats and promotes the reuse of tools that interact through this API. We focus first on ``Annotation Graphs,'' a graph model for annotations on linear signals (such as text and speech) indexed by intervals, for which efficient database storage and querying techniques are applicable. We note how a wide range of existing annotated corpora can be mapped to this annotation graph model. This model is then generalized to encompass a wider variety of linguistic ``signals,'' including both naturally occuring phenomena (as recorded in images, video, multi-modal interactions, etc.), as well as the derived resources that are increasingly important to the engineering of natural language processing systems (such as word lists, dictionaries, aligned bilingual corpora, etc.). We conclude with a review of the current efforts towards implementing key pieces of this architecture.
* 8 pages, 9 figures
Annotation graphs as a framework for multidimensional linguistic data analysis
Jul 05, 1999
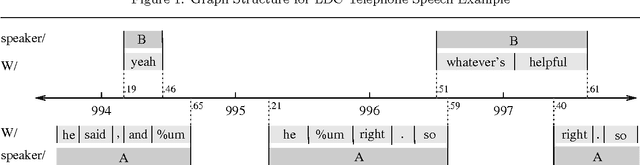


In recent work we have presented a formal framework for linguistic annotation based on labeled acyclic digraphs. These `annotation graphs' offer a simple yet powerful method for representing complex annotation structures incorporating hierarchy and overlap. Here, we motivate and illustrate our approach using discourse-level annotations of text and speech data drawn from the CALLHOME, COCONUT, MUC-7, DAMSL and TRAINS annotation schemes. With the help of domain specialists, we have constructed a hybrid multi-level annotation for a fragment of the Boston University Radio Speech Corpus which includes the following levels: segment, word, breath, ToBI, Tilt, Treebank, coreference and named entity. We show how annotation graphs can represent hybrid multi-level structures which derive from a diverse set of file formats. We also show how the approach facilitates substantive comparison of multiple annotations of a single signal based on different theoretical models. The discussion shows how annotation graphs open the door to wide-ranging integration of tools, formats and corpora.
A Formal Framework for Linguistic Annotation
Mar 02, 1999`Linguistic annotation' covers any descriptive or analytic notations applied to raw language data. The basic data may be in the form of time functions -- audio, video and/or physiological recordings -- or it may be textual. The added notations may include transcriptions of all sorts (from phonetic features to discourse structures), part-of-speech and sense tagging, syntactic analysis, `named entity' identification, co-reference annotation, and so on. While there are several ongoing efforts to provide formats and tools for such annotations and to publish annotated linguistic databases, the lack of widely accepted standards is becoming a critical problem. Proposed standards, to the extent they exist, have focussed on file formats. This paper focuses instead on the logical structure of linguistic annotations. We survey a wide variety of existing annotation formats and demonstrate a common conceptual core, the annotation graph. This provides a formal framework for constructing, maintaining and searching linguistic annotations, while remaining consistent with many alternative data structures and file formats.
A lexical database tool for quantitative phonological research
Jul 22, 1997
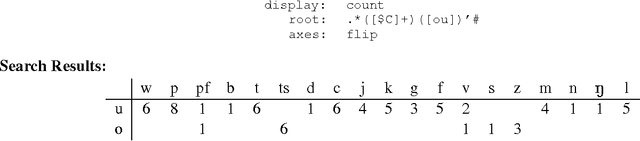

A lexical database tool tailored for phonological research is described. Database fields include transcriptions, glosses and hyperlinks to speech files. Database queries are expressed using HTML forms, and these permit regular expression search on any combination of fields. Regular expressions are passed directly to a Perl CGI program, enabling the full flexibility of Perl extended regular expressions. The regular expression notation is extended to better support phonological searches, such as search for minimal pairs. Search results are presented in the form of HTML or LaTeX tables, where each cell is either a number (representing frequency) or a designated subset of the fields. Tables have up to four dimensions, with an elegant system for specifying which fragments of which fields should be used for the row/column labels. The tool offers several advantages over traditional methods of analysis: (i) it supports a quantitative method of doing phonological research; (ii) it gives universal access to the same set of informants; (iii) it enables other researchers to hear the original speech data without having to rely on published transcriptions; (iv) it makes the full power of regular expression search available, and search results are full multimedia documents; and (v) it enables the early refutation of false hypotheses, shortening the analysis-hypothesis-test loop. A life-size application to an African tone language (Dschang) is used for exemplification throughout the paper. The database contains 2200 records, each with approximately 15 fields. Running on a PC laptop with a stand-alone web server, the `Dschang HyperLexicon' has already been used extensively in phonological fieldwork and analysis in Cameroon.
* 7 pages, uses ipamacs.sty
Automated tone transcription
Oct 25, 1994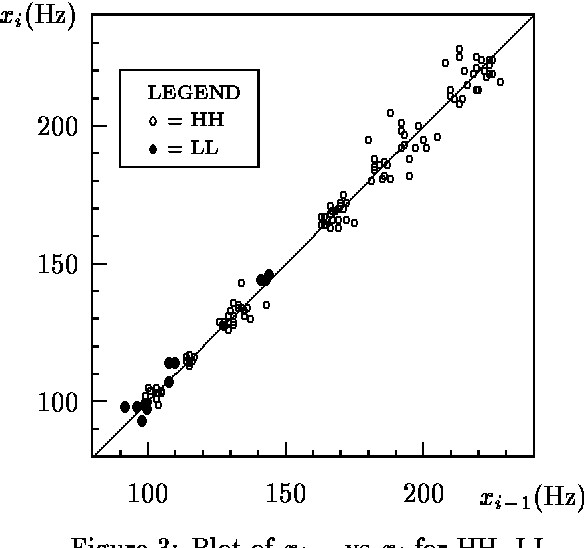
In this paper I report on an investigation into the problem of assigning tones to pitch contours. The proposed model is intended to serve as a tool for phonologists working on instrumentally obtained pitch data from tone languages. Motivation and exemplification for the model is provided by data taken from my fieldwork on Bamileke Dschang (Cameroon). Following recent work by Liberman and others, I provide a parametrised F_0 prediction function P which generates F_0 values from a tone sequence, and I explore the asymptotic behaviour of downstep. Next, I observe that transcribing a sequence X of pitch (i.e. F_0) values amounts to finding a tone sequence T such that P(T) {}~= X. This is a combinatorial optimisation problem, for which two non-deterministic search techniques are provided: a genetic algorithm and a simulated annealing algorithm. Finally, two implementations---one for each technique---are described and then compared using both artificial and real data for sequences of up to 20 tones. These programs can be adapted to other tone languages by adjusting the F_0 prediction function.
* 12 pages, 4 postscript figures, uses examples.sty, newapa.sty, latex-acl.sty, ipamacs.sty