 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced-Order Neural Network Synthesis with Robustness Guarantees
Feb 18, 2021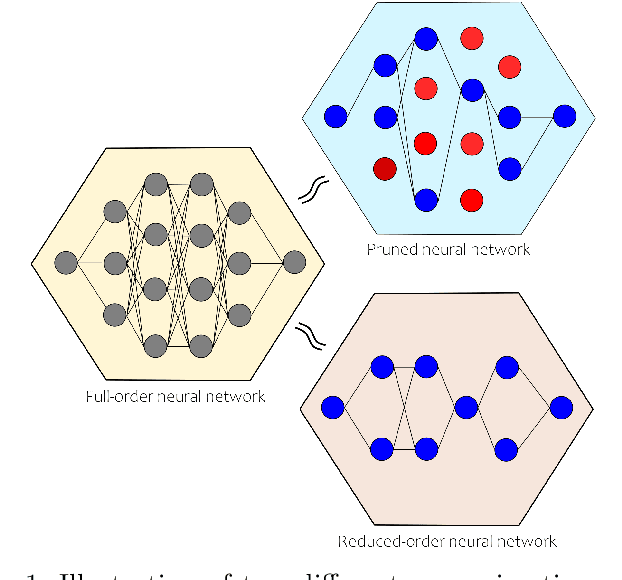
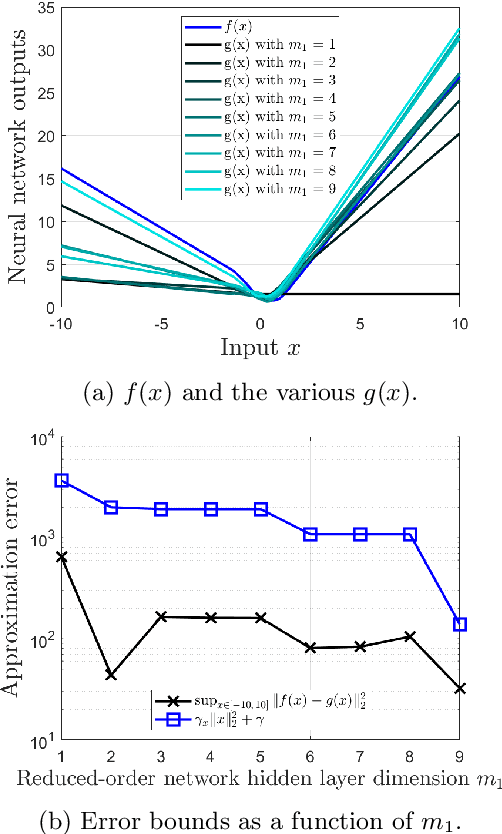
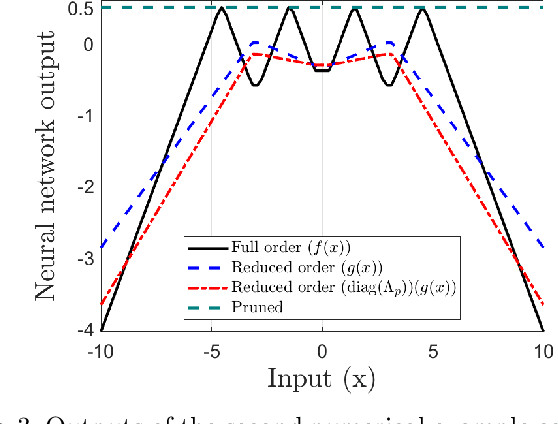

In the wake of the explosive growth in smartphones and cyberphysical systems, there has been an accelerating shift in how data is generated away from centralised data towards on-device generated data. In response, machine learning algorithms are being adapted to run locally on board, potentially hardware limited, devices to improve user privacy, reduce latency and be more energy efficient. However, our understanding of how these device orientated algorithms behave and should be trained is still fairly limited. To address this issue, a method to automatically synthesize reduced-order neural networks (having fewer neurons) approximating the input/output mapping of a larger one is introduced. The reduced-order neural network's weights and biases are generated from a convex semi-definite programme that minimises the worst-case approximation error with respect to the larger network. Worst-case bounds for this approximation error are obtained and the approach can be applied to a wide variety of neural networks architectures. What differentiates the proposed approach to existing methods for generating small neural networks, e.g. pruning, is the inclusion of the worst-case approximation error directly within the training cost function, which should add robustness. Numerical examples highlight the potential of the proposed approach. The overriding goal of this paper is to generalise recent results in the robustness analysis of neural networks to a robust synthesis problem for their weights and biases.
Robust error bounds for quantised and pruned neural networks
Nov 30, 2020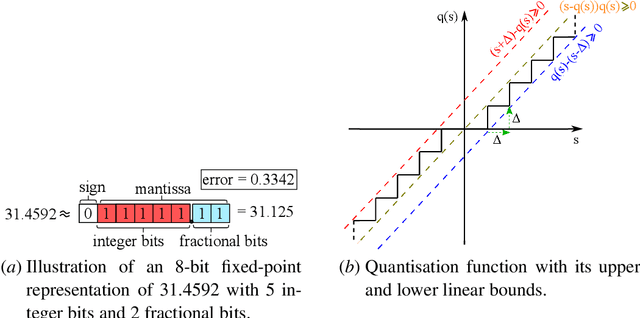
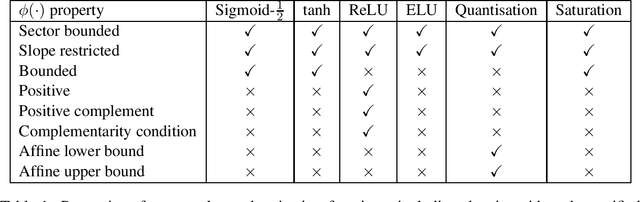
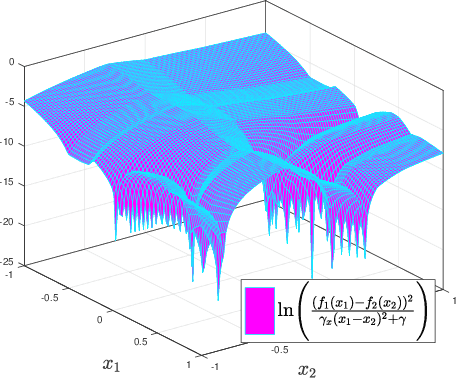
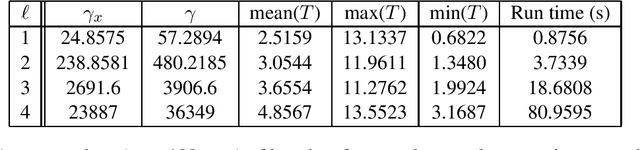
With the rise of smartphones and the internet-of-things, data is increasingly getting generated at the edge on local, personal devices. For privacy, latency and energy saving reasons, this shift is causing machine learning algorithms to move towards a decentralised approach, with the data and algorithms stored and even trained locally on devices. The device hardware becomes the main bottleneck for model performance in this set-up, creating a need for slimmed down, more efficient neural networks. Neural network pruning and quantisation are two methods that have been developed to achieve this, with both approaches demonstrating impressive results in reducing the computational cost without sacrificing too much on model performance. However, our understanding behind these methods remains underdeveloped. To address this issue, a semi-definite program to robustly bound the error caused by pruning and quantising a neural network is introduced in this paper. The method can be applied to generic neural networks, accounts for the many nonlinearities of the problem and holds robustly for all inputs in specified sets. It is hoped that the computed bounds will give certainty to software/control/machine learning engineers implementing these algorithms efficiently on limited hardware.