 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Matrices for MBAT Vector Symbolic Architectures, and a "Soft" VSA Representation for JSON
Feb 08, 2022Vector Symbolic Architectures (VSAs) give a way to represent a complex object as a single fixed-length vector, so that similar objects have similar vector representations. These vector representations then become easy to use for machine learning or nearest-neighbor search. We review a previously proposed VSA method, MBAT (Matrix Binding of Additive Terms), which uses multiplication by random matrices for binding related terms. However, multiplying by such matrices introduces instabilities which can harm performance. Making the random matrices be orthogonal matrices provably fixes this problem. With respect to larger scale applications, we see how to apply MBAT vector representations for any data expressed in JSON. JSON is used in numerous programming languages to express complex data, but its native format appears highly unsuited for machine learning. Expressing JSON as a fixed-length vector makes it readily usable for machine learning and nearest-neighbor search. Creating such JSON vectors also shows that a VSA needs to employ binding operations that are non-commutative. VSAs are now ready to try with full-scale practical applications, including healthcare, pharmaceuticals, and genomics. Keywords: MBAT (Matrix Binding of Additive Terms), VSA (Vector Symbolic Architecture), HDC (Hyperdimensional Computing), Distributed Representations, Binding, Orthogonal Matrices, Recurrent Connections, Machine Learning, Search, JSON, VSA Applications
DataWords: Getting Contrarian with Text, Structured Data and Explanations
Nov 09, 2021Our goal is to build classification models using a combination of free-text and structured data. To do this, we represent structured data by text sentences, DataWords, so that similar data items are mapped into the same sentence. This permits modeling a mixture of text and structured data by using only text-modeling algorithms. Several examples illustrate that it is possible to improve text classification performance by first running extraction tools (named entity recognition), then converting the output to DataWords, and adding the DataWords to the original text -- before model building and classification. This approach also allows us to produce explanations for inferences in terms of both free text and structured data.
Predicting Severe Sepsis Using Text from the Electronic Health Record
Nov 30, 2017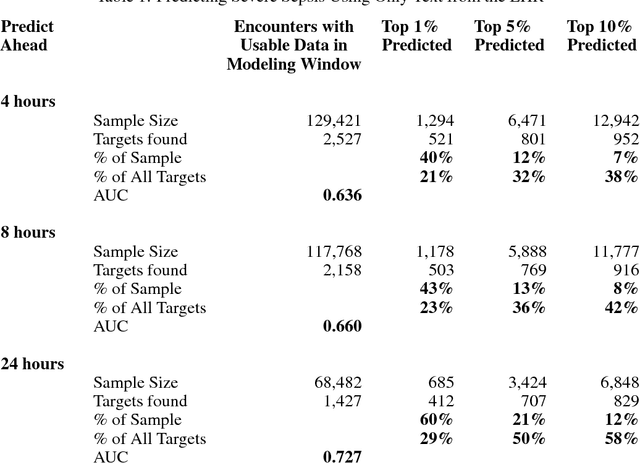
Employing a machine learning approach we predict, up to 24 hours prior, a diagnosis of severe sepsis. Strongly predictive models are possible that use only text reports from the Electronic Health Record (EHR), and omit structured numerical data. Unstructured text alone gives slightly better performance than structured data alone, and the combination further improves performance. We also discuss advantages of using unstructured EHR text for modeling, as compared to structured EHR data.
Representing Objects, Relations, and Sequences
Jan 29, 2015Vector Symbolic Architectures (VSAs) are high-dimensional vector representations of objects (eg., words, image parts), relations (eg., sentence structures), and sequences for use with machine learning algorithms. They consist of a vector addition operator for representing a collection of unordered objects, a Binding operator for associating groups of objects, and a methodology for encoding complex structures. We first develop Constraints that machine learning imposes upon VSAs: for example, similar structures must be represented by similar vectors. The constraints suggest that current VSAs should represent phrases ("The smart Brazilian girl") by binding sums of terms, in addition to simply binding the terms directly. We show that matrix multiplication can be used as the binding operator for a VSA, and that matrix elements can be chosen at random. A consequence for living systems is that binding is mathematically possible without the need to specify, in advance, precise neuron-to-neuron connection properties for large numbers of synapses. A VSA that incorporates these ideas, MBAT (Matrix Binding of Additive Terms), is described that satisfies all Constraints. With respect to machine learning, for some types of problems appropriate VSA representations permit us to prove learnability, rather than relying on simulations. We also propose dividing machine (and neural) learning and representation into three Stages, with differing roles for learning in each stage. For neural modeling, we give "representational reasons" for nervous systems to have many recurrent connections, as well as for the importance of phrases in language processing. Sizing simulations and analyses suggest that VSAs in general, and MBAT in particular, are ready for real-world applications.
* 41 pages
Automated Generation of Connectionist Expert Systems for Problems Involving Noise and Redundancy
Mar 27, 2013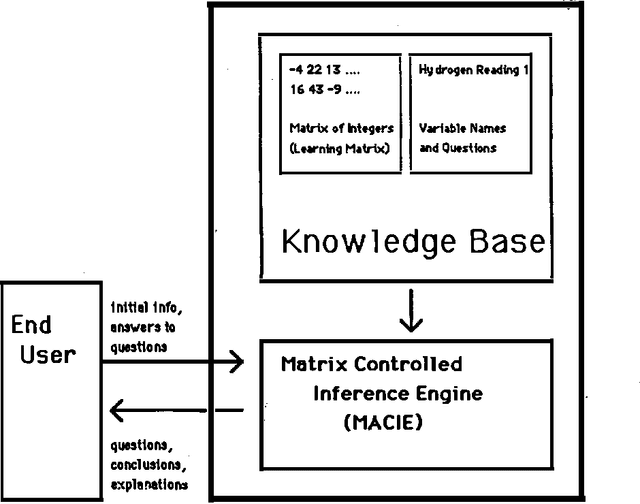
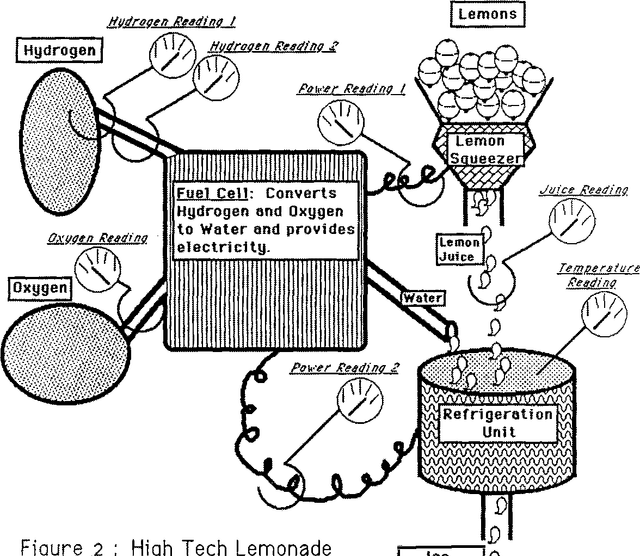

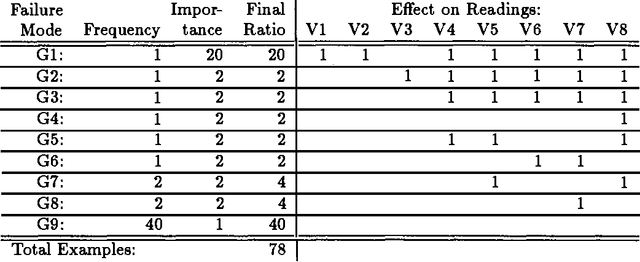
When creating an expert system, the most difficult and expensive task is constructing a knowledge base. This is particularly true if the problem involves noisy data and redundant measurements. This paper shows how to modify the MACIE process for generating connectionist expert systems from training examples so that it can accommodate noisy and redundant data. The basic idea is to dynamically generate appropriate training examples by constructing both a 'deep' model and a noise model for the underlying problem. The use of winner-take-all groups of variables is also discussed. These techniques are illustrated with a small example that would be very difficult for standard expert system approaches.
Bayesian Assessment of a Connectionist Model for Fault Detection
Mar 27, 2013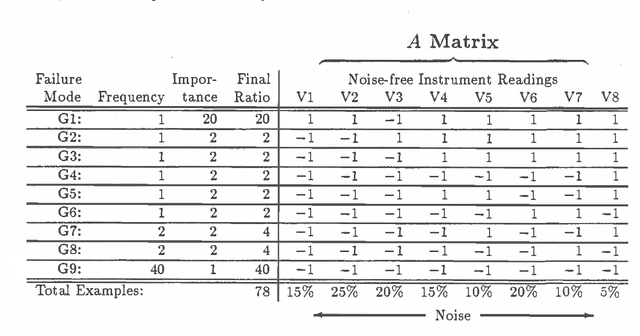
A previous paper [2] showed how to generate a linear discriminant network (LDN) that computes likely faults for a noisy fault detection problem by using a modification of the perceptron learning algorithm called the pocket algorithm. Here we compare the performance of this connectionist model with performance of the optimal Bayesian decision rule for the example that was previously described. We find that for this particular problem the connectionist model performs about 97% as well as the optimal Bayesian procedure. We then define a more general class of noisy single-pattern boolean (NSB) fault detection problems where each fault corresponds to a single :pattern of boolean instrument readings and instruments are independently noisy. This is equivalent to specifying that instrument readings are probabilistic but conditionally independent given any particular fault. We prove: 1. The optimal Bayesian decision rule for every NSB fault detection problem is representable by an LDN containing no intermediate nodes. (This slightly extends a result first published by Minsky & Selfridge.) 2. Given an NSB fault detection problem, then with arbitrarily high probability after sufficient iterations the pocket algorithm will generate an LDN that computes an optimal Bayesian decision rule for that problem. In practice we find that a reasonable number of iterations of the pocket algorithm produces a network with good, but not optimal, performance.