 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhanaNLP Parallel Corpora: Comprehensive Multilingual Resources for Low-Resource Ghanaian Languages
Mar 14, 2026Low resource languages present unique challenges for natural language processing due to the limited availability of digitized and well structured linguistic data. To address this gap, the GhanaNLP initiative has developed and curated 41,513 parallel sentence pairs for the Twi, Fante, Ewe, Ga, and Kusaal languages, which are widely spoken across Ghana yet remain underrepresented in digital spaces. Each dataset consists of carefully aligned sentence pairs between a local language and English. The data were collected, translated, and annotated by human professionals and enriched with standard structural metadata to ensure consistency and usability. These corpora are designed to support research, educational, and commercial applications, including machine translation, speech technologies, and language preservation. This paper documents the dataset creation methodology, structure, intended use cases, and evaluation, as well as their deployment in real world applications such as the Khaya AI translation engine. Overall, this work contributes to broader efforts to democratize AI by enabling inclusive and accessible language technologies for African languages.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

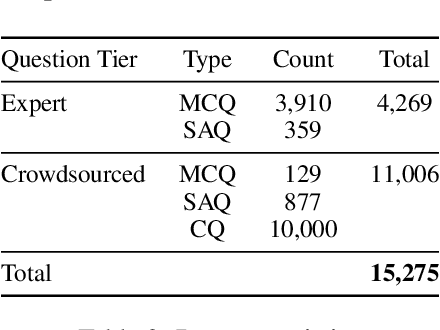

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.