 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounds on Agreement between Subjective and Objective Measurements
Mar 13, 2026Objective estimators of multimedia quality are often judged by comparing estimates with subjective "truth data," most often via Pearson correlation coefficient (PCC) or mean-squared error (MSE). But subjective test results contain noise, so striving for a PCC of 1.0 or an MSE of 0.0 is neither realistic nor repeatable. Numerous efforts have been made to acknowledge and appropriately accommodate subjective test noise in objective-subjective comparisons, typically resulting in new analysis frameworks and figures-of-merit. We take a different approach. By making only basic assumptions, we derive bounds on PCC and MSE that can be expected for a subjective test. Consistent with intuition, these bounds are functions of subjective vote variance. When a subjective test includes vote variance information, the calculation of the bounds is easy, and in this case we say the resulting bounds are "fully data-driven." We provide two options for calculating bounds in cases where vote variance information is not available. One option is to use vote variance information from other subjective tests that do provide such information, and the second option is to use a model for subjective votes. Thus we introduce a binomial-based model for subjective votes (BinoVotes) that naturally leads to a mean opinion score (MOS) model, named BinoMOS, with multiple unique desirable properties. BinoMOS reproduces the discrete nature of MOS values and its dependence on the number of votes per file. This modeling provides vote variance information required by the PCC and MSE bounds and we compare this modeling with data from 18 subjective tests. The modeling yields PCC and MSE bounds that agree very well with those found from the data directly. These results allow one to set expectations for the PCC and MSE that might be achieved for any subjective test, even those where vote variance information is not available.
Unseen but not Unknown: Using Dataset Concealment to Robustly Evaluate Speech Quality Estimation Models
Jan 28, 2026We introduce Dataset Concealment (DSC), a rigorous new procedure for evaluating and interpreting objective speech quality estimation models. DSC quantifies and decomposes the performance gap between research results and real-world application requirements, while offering context and additional insights into model behavior and dataset characteristics. We also show the benefits of addressing the corpus effect by using the dataset Aligner from AlignNet when training models with multiple datasets. We demonstrate DSC and the improvements from the Aligner using nine training datasets and nine unseen datasets with three well-studied models: MOSNet, NISQA, and a Wav2Vec2.0-based model. DSC provides interpretable views of the generalization capabilities and limitations of models, while allowing all available data to be used at training. An additional result is that adding the 1000 parameter dataset Aligner to the 94 million parameter Wav2Vec model during training does significantly improve the resulting model's ability to estimate speech quality for unseen data.
Why some audio signal short-time Fourier transform coefficients have nonuniform phase distributions
Sep 13, 2024The short-time Fourier transform (STFT) represents a window of audio samples as a set of complex coefficients. These are advantageously viewed as magnitudes and phases and the overall distribution of phases is very often assumed to be uniform. We show that when audio signal STFT phase distributions are analyzed per-frequency or per-magnitude range, they can be far from uniform. That is, the uniform phase distribution assumption obscures significant important details. We explain the significance of the nonuniform phase distributions and how they might be exploited, derive their source, and explain why the choice of the STFT window shape influences the nonuniformity of the resulting phase distributions.
WEnets: A Convolutional Framework for Evaluating Audio Waveforms
Sep 19, 2019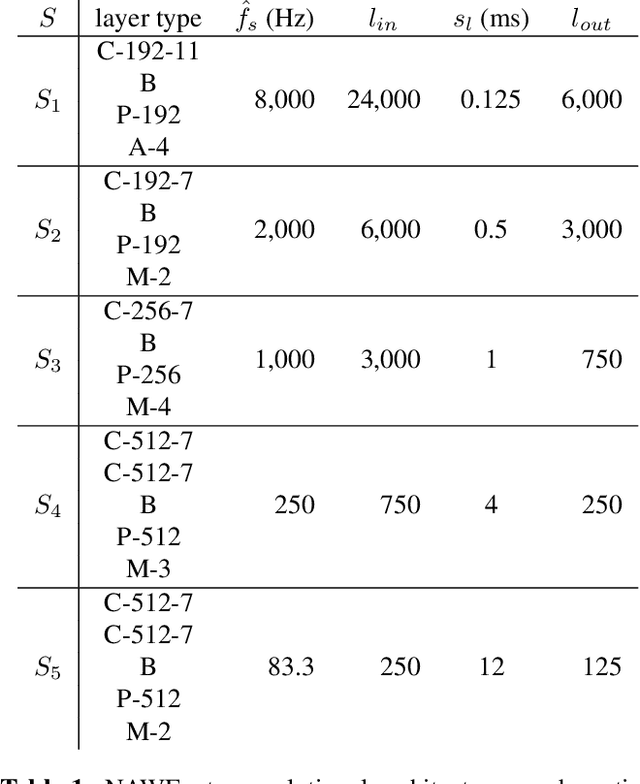

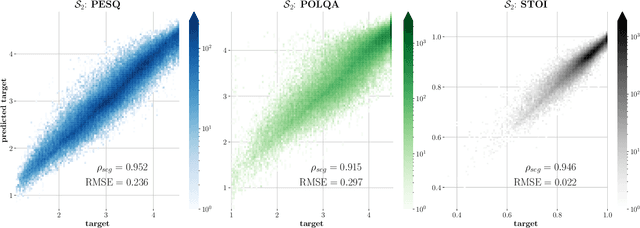
We describe a new convolutional framework for waveform evaluation, WEnets, and build a Narrowband Audio Waveform Evaluation Network, or NAWEnet, using this framework. NAWEnet is single-ended (or no-reference) and was trained three separate times in order to emulate PESQ, POLQA, or STOI with testing correlations 0.95, 0.92, and 0.95, respectively when training on only 50% of available data and testing on 40%. Stacks of 1-D convolutional layers and non-linear downsampling learn which features are important for quality or intelligibility estimation. This straightforward architecture simplifies the interpretation of its inner workings and paves the way for future investigations into higher sample rates and accurate no-reference subjective speech quality predictions.