 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Benchmarks the Benchmarks? A Case Study of LLM Evaluation in Icelandic
Mar 17, 2026This paper evaluates current Large Language Model (LLM) benchmarking for Icelandic, identifies problems, and calls for improved evaluation methods in low/medium-resource languages in particular. We show that benchmarks that include synthetic or machine-translated data that have not been verified in any way, commonly contain severely flawed test examples that are likely to skew the results and undermine the tests' validity. We warn against the use of such methods without verification in low/medium-resource settings as the translation quality can, at best, only be as good as MT quality for a given language at any given time. Indeed, the results of our quantitative error analysis on existing benchmarks for Icelandic show clear differences between human-authored/-translated benchmarks vs. synthetic or machine-translated benchmarks.
Hotter and Colder: A New Approach to Annotating Sentiment, Emotions, and Bias in Icelandic Blog Comments
Feb 24, 2025



This paper presents Hotter and Colder, a dataset designed to analyze various types of online behavior in Icelandic blog comments. Building on previous work, we used GPT-4o mini to annotate approximately 800,000 comments for 25 tasks, including sentiment analysis, emotion detection, hate speech, and group generalizations. Each comment was automatically labeled on a 5-point Likert scale. In a second annotation stage, comments with high or low probabilities of containing each examined behavior were subjected to manual revision. By leveraging crowdworkers to refine these automatically labeled comments, we ensure the quality and accuracy of our dataset resulting in 12,232 uniquely annotated comments and 19,301 annotations. Hotter and Colder provides an essential resource for advancing research in content moderation and automatically detectiong harmful online behaviors in Icelandic.
Building an Icelandic Entity Linking Corpus
Jun 10, 2022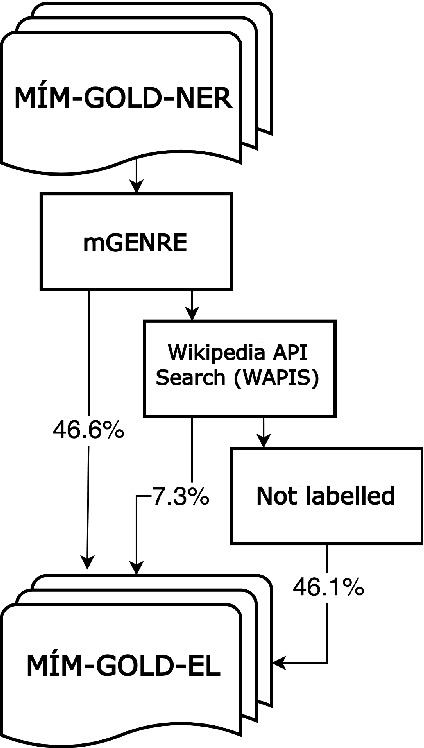
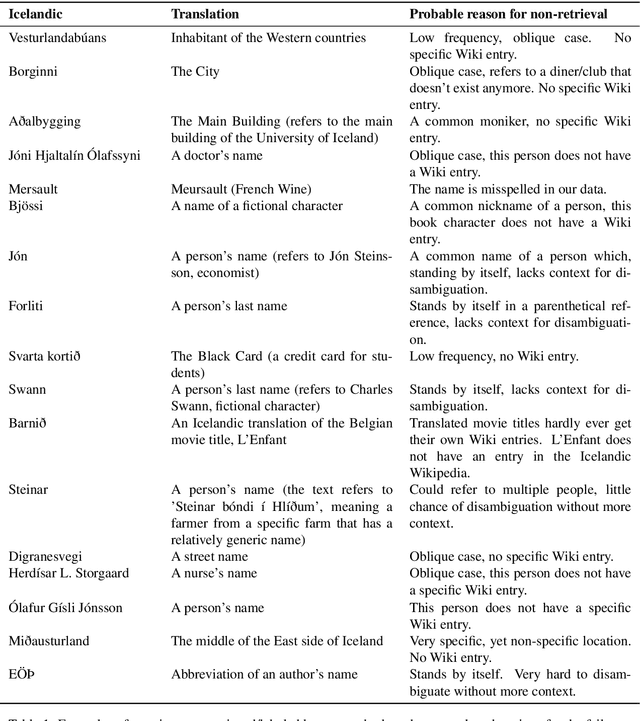
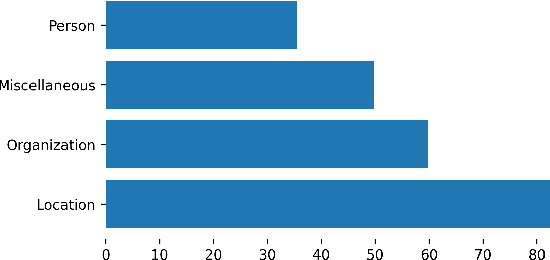
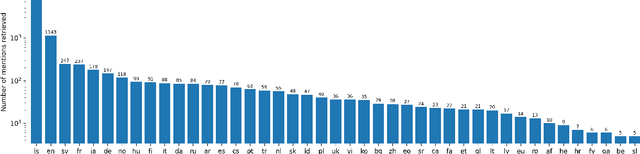
In this paper, we present the first Entity Linking corpus for Icelandic. We describe our approach of using a multilingual entity linking model (mGENRE) in combination with Wikipedia API Search (WAPIS) to label our data and compare it to an approach using WAPIS only. We find that our combined method reaches 53.9% coverage on our corpus, compared to 30.9% using only WAPIS. We analyze our results and explain the value of using a multilingual system when working with Icelandic. Additionally, we analyze the data that remain unlabeled, identify patterns and discuss why they may be more difficult to annotate.