 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMono-SF: Multi-View Geometry Meets Single-View Depth for Monocular Scene Flow Estimation of Dynamic Traffic Scenes
Aug 17, 2019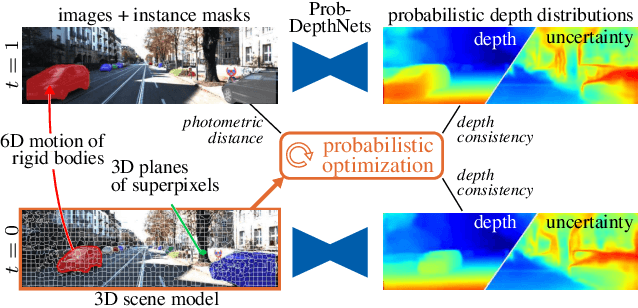
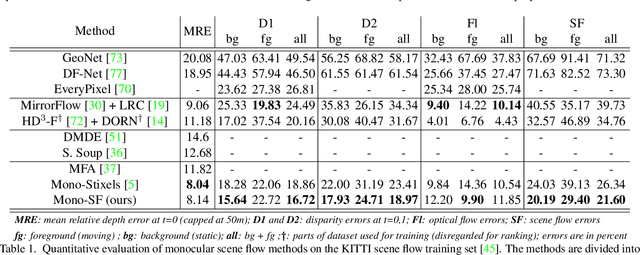
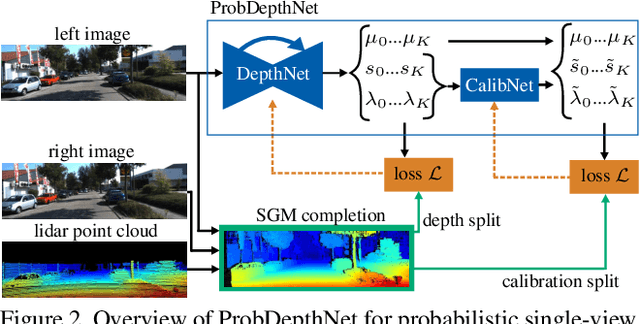
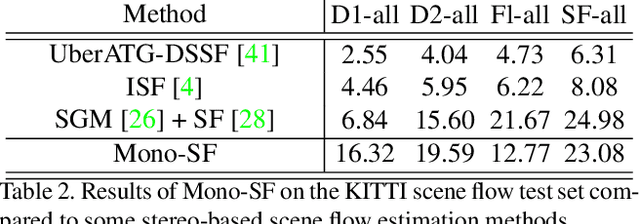
Existing 3D scene flow estimation methods provide the 3D geometry and 3D motion of a scene and gain a lot of interest, for example in the context of autonomous driving. These methods are traditionally based on a temporal series of stereo images. In this paper, we propose a novel monocular 3D scene flow estimation method, called Mono-SF. Mono-SF jointly estimates the 3D structure and motion of the scene by combining multi-view geometry and single-view depth information. Mono-SF considers that the scene flow should be consistent in terms of warping the reference image in the consecutive image based on the principles of multi-view geometry. For integrating single-view depth in a statistical manner, a convolutional neural network, called ProbDepthNet, is proposed. ProbDepthNet estimates pixel-wise depth distributions from a single image rather than single depth values. Additionally, as part of ProbDepthNet, a novel recalibration technique for regression problems is proposed to ensure well-calibrated distributions. Our experiments show that Mono-SF outperforms state-of-the-art monocular baselines and ablation studies support the Mono-SF approach and ProbDepthNet design.
Mono-Stixels: Monocular depth reconstruction of dynamic street scenes
Aug 07, 2019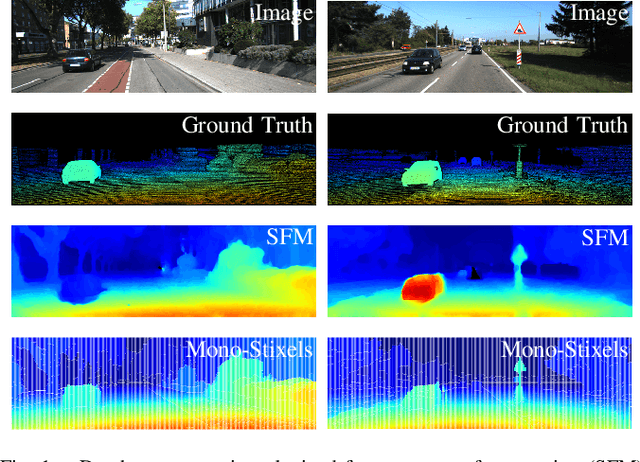


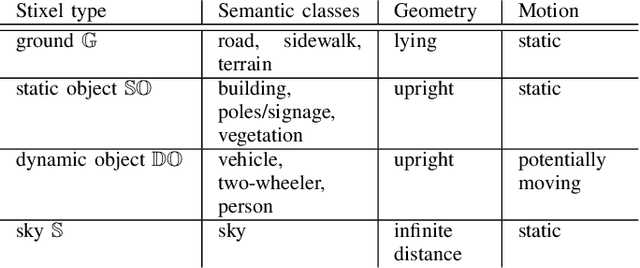
In this paper we present mono-stixels, a compact environment representation specially designed for dynamic street scenes. Mono-stixels are a novel approach to estimate stixels from a monocular camera sequence instead of the traditionally used stereo depth measurements. Our approach jointly infers the depth, motion and semantic information of the dynamic scene as a 1D energy minimization problem based on optical flow estimates, pixel-wise semantic segmentation and camera motion. The optical flow of a stixel is described by a homography. By applying the mono-stixel model the degrees of freedom of a stixel-homography are reduced to only up to two degrees of freedom. Furthermore, we exploit a scene model and semantic information to handle moving objects. In our experiments we use the public available DeepFlow for optical flow estimation and FCN8s for the semantic information as inputs and show on the KITTI 2015 dataset that mono-stixels provide a compact and reliable depth reconstruction of both the static and moving parts of the scene. Thereby, mono-stixels overcome the limitation to static scenes of previous structure-from-motion approaches.