 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks with Optimal Double-Bayesian Learning
May 19, 2026Backpropagation with gradient descent is a common optimization strategy employed by most neural network architectures in machine learning. However, finding optimal hyperparameters to guide training has proven challenging. While it is widely acknowledged that selecting appropriate parameters is crucial for avoiding overfitting and achieving unbiased outcomes, this choice remains largely based on empirical experiments and experience. This paper presents a new probabilistic framework for the learning rate, a key parameter in stochastic gradient descent. The framework develops classic Bayesian statistics into a double-Bayesian decision mechanism involving two antagonistic Bayesian processes. A theoretically optimal learning rate can be derived from these two processes and used for stochastic gradient descent. Experiments across various classification, segmentation, and detection tasks corroborate the practical significance of the theoretically derived learning rate. The paper also discusses the ramifications of the proposed double-Bayesian framework for network training and model performance.
Double-Bayesian Learning
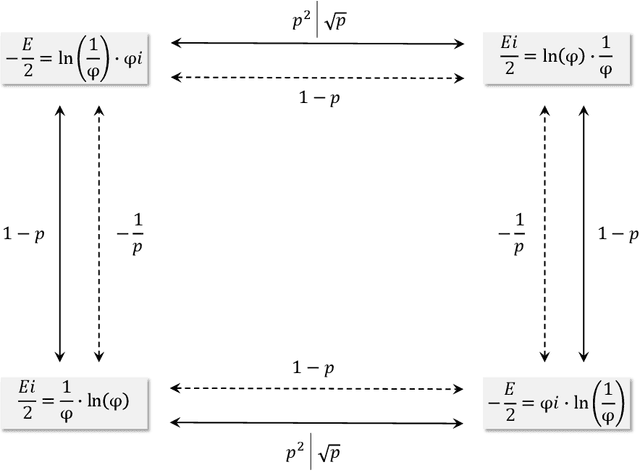
Oct 16, 2024Contemporary machine learning methods will try to approach the Bayes error, as it is the lowest possible error any model can achieve. This paper postulates that any decision is composed of not one but two Bayesian decisions and that decision-making is, therefore, a double-Bayesian process. The paper shows how this duality implies intrinsic uncertainty in decisions and how it incorporates explainability. The proposed approach understands that Bayesian learning is tantamount to finding a base for a logarithmic function measuring uncertainty, with solutions being fixed points. Furthermore, following this approach, the golden ratio describes possible solutions satisfying Bayes' theorem. The double-Bayesian framework suggests using a learning rate and momentum weight with values similar to those used in the literature to train neural networks with stochastic gradient descent.
A Dual Process Model for Optimizing Cross Entropy in Neural Networks
Apr 27, 2021
Minimizing cross-entropy is a widely used method for training artificial neural networks. Many training procedures based on backpropagation use cross-entropy directly as their loss function. Instead, this theoretical essay investigates a dual process model with two processes, in which one process minimizes the Kullback-Leibler divergence while its dual counterpart minimizes the Shannon entropy. Postulating that learning consists of two dual processes complementing each other, the model defines an equilibrium state for both processes in which the loss function assumes its minimum. An advantage of the proposed model is that it allows deriving the optimal learning rate and momentum weight to update network weights for backpropagation. Furthermore, the model introduces the golden ratio and complex numbers as important new concepts in machine learning.
The Golden Ratio of Learning and Momentum
Jun 08, 2020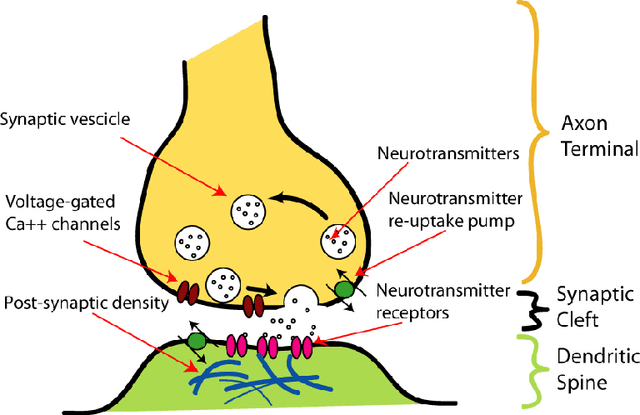

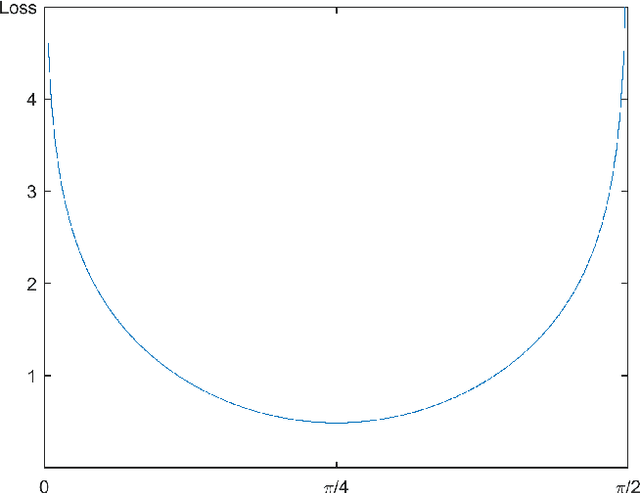
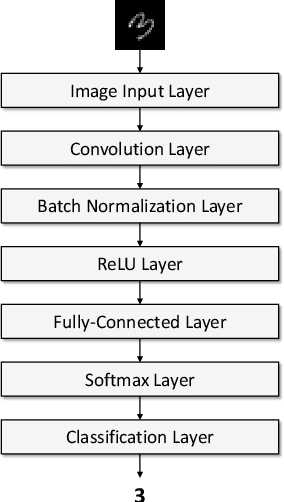
Gradient descent has been a central training principle for artificial neural networks from the early beginnings to today's deep learning networks. The most common implementation is the backpropagation algorithm for training feed-forward neural networks in a supervised fashion. Backpropagation involves computing the gradient of a loss function, with respect to the weights of the network, to update the weights and thus minimize loss. Although the mean square error is often used as a loss function, the general stochastic gradient descent principle does not immediately connect with a specific loss function. Another drawback of backpropagation has been the search for optimal values of two important training parameters, learning rate and momentum weight, which are determined empirically in most systems. The learning rate specifies the step size towards a minimum of the loss function when following the gradient, while the momentum weight considers previous weight changes when updating current weights. Using both parameters in conjunction with each other is generally accepted as a means to improving training, although their specific values do not follow immediately from standard backpropagation theory. This paper proposes a new information-theoretical loss function motivated by neural signal processing in a synapse. The new loss function implies a specific learning rate and momentum weight, leading to empirical parameters often used in practice. The proposed framework also provides a more formal explanation of the momentum term and its smoothing effect on the training process. All results taken together show that loss, learning rate, and momentum are closely connected. To support these theoretical findings, experiments for handwritten digit recognition show the practical usefulness of the proposed loss function and training parameters.
Entropy, Perception, and Relativity
Nov 02, 2008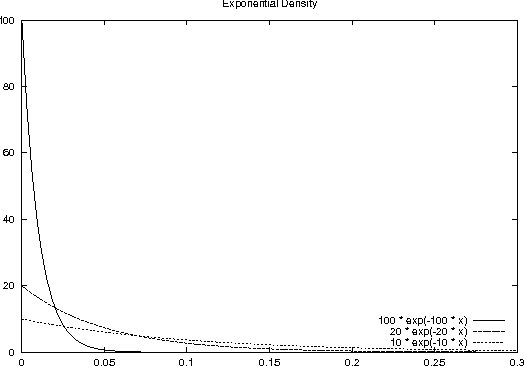
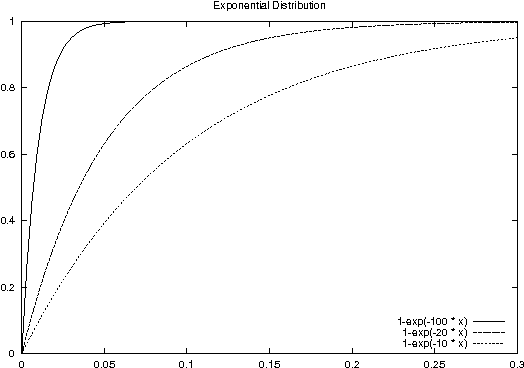
In this paper, I expand Shannon's definition of entropy into a new form of entropy that allows integration of information from different random events. Shannon's notion of entropy is a special case of my more general definition of entropy. I define probability using a so-called performance function, which is de facto an exponential distribution. Assuming that my general notion of entropy reflects the true uncertainty about a probabilistic event, I understand that our perceived uncertainty differs. I claim that our perception is the result of two opposing forces similar to the two famous antagonists in Chinese philosophy: Yin and Yang. Based on this idea, I show that our perceived uncertainty matches the true uncertainty in points determined by the golden ratio. I demonstrate that the well-known sigmoid function, which we typically employ in artificial neural networks as a non-linear threshold function, describes the actual performance. Furthermore, I provide a motivation for the time dilation in Einstein's Special Relativity, basically claiming that although time dilation conforms with our perception, it does not correspond to reality. At the end of the paper, I show how to apply this theoretical framework to practical applications. I present recognition rates for a pattern recognition problem, and also propose a network architecture that can take advantage of general entropy to solve complex decision problems.