 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Scalable Expansion of Natural Language Understanding Functionality for Intelligent Agents
May 03, 2018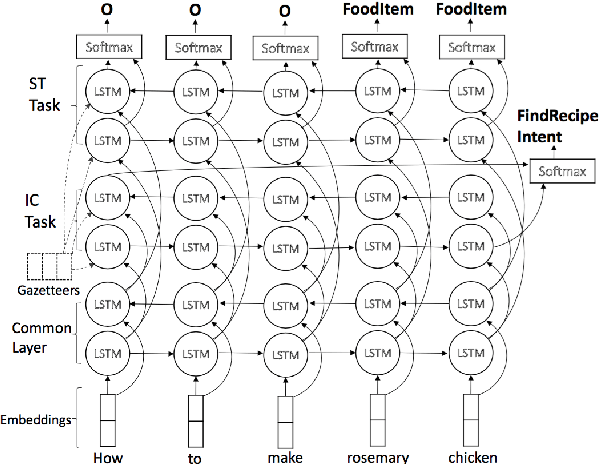
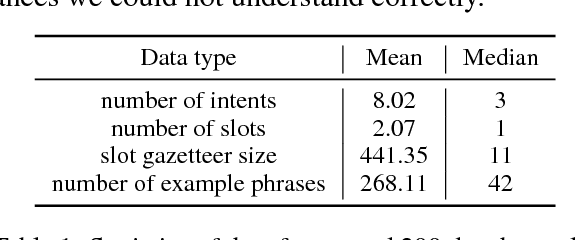
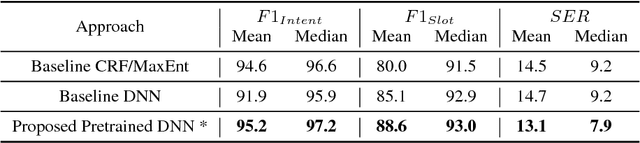
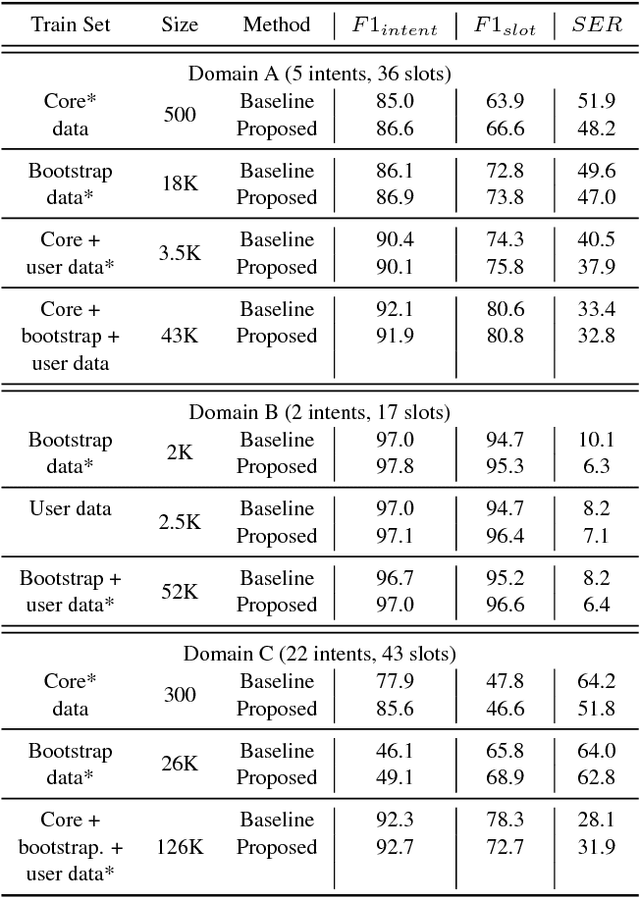
Fast expansion of natural language functionality of intelligent virtual agents is critical for achieving engaging and informative interactions. However, developing accurate models for new natural language domains is a time and data intensive process. We propose efficient deep neural network architectures that maximally re-use available resources through transfer learning. Our methods are applied for expanding the understanding capabilities of a popular commercial agent and are evaluated on hundreds of new domains, designed by internal or external developers. We demonstrate that our proposed methods significantly increase accuracy in low resource settings and enable rapid development of accurate models with less data.
Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting
May 05, 2017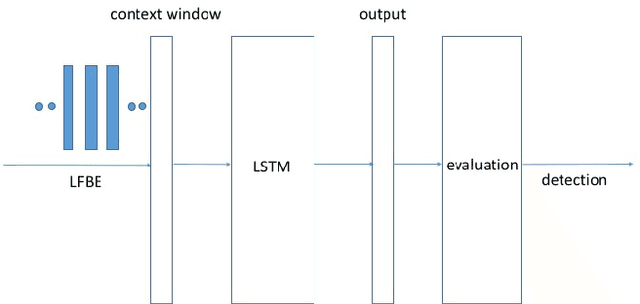

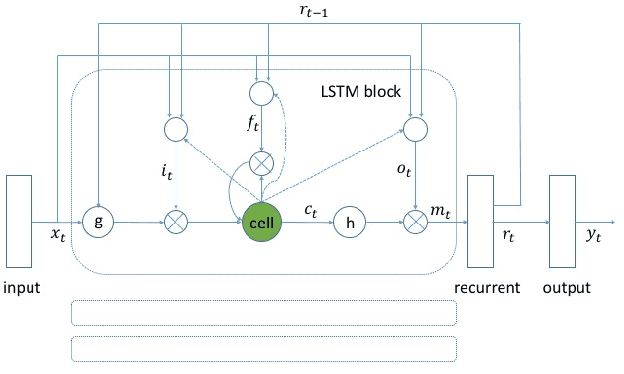
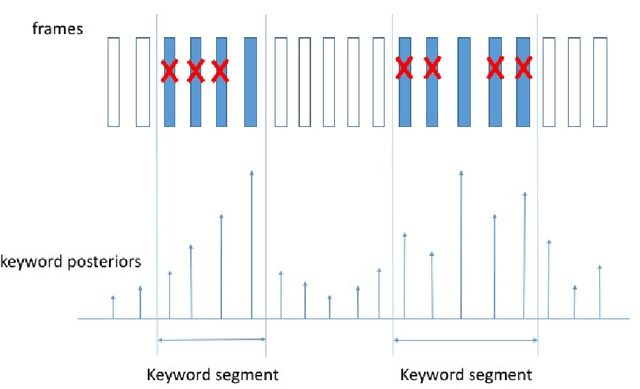
We propose a max-pooling based loss function for training Long Short-Term Memory (LSTM) networks for small-footprint keyword spotting (KWS), with low CPU, memory, and latency requirements. The max-pooling loss training can be further guided by initializing with a cross-entropy loss trained network. A posterior smoothing based evaluation approach is employed to measure keyword spotting performance. Our experimental results show that LSTM models trained using cross-entropy loss or max-pooling loss outperform a cross-entropy loss trained baseline feed-forward Deep Neural Network (DNN). In addition, max-pooling loss trained LSTM with randomly initialized network performs better compared to cross-entropy loss trained LSTM. Finally, the max-pooling loss trained LSTM initialized with a cross-entropy pre-trained network shows the best performance, which yields $67.6\%$ relative reduction compared to baseline feed-forward DNN in Area Under the Curve (AUC) measure.