 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Weight Regularizers for Pruning Pretrained Neural Networks
Apr 05, 2022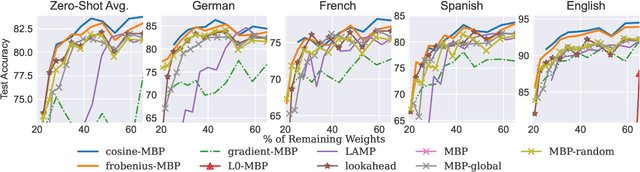
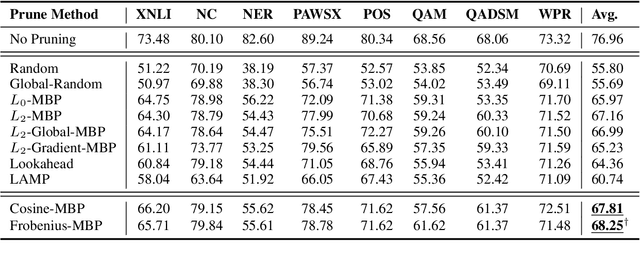
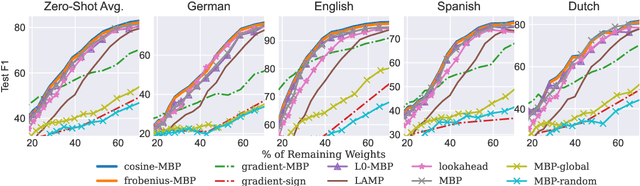
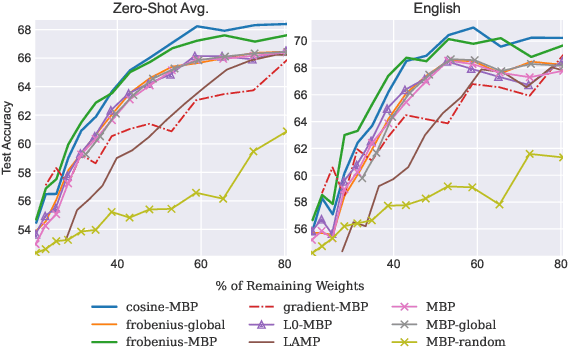
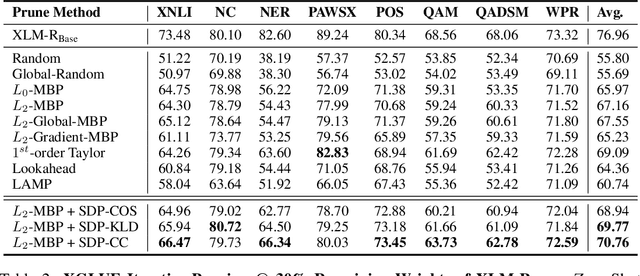
While various avenues of research have been explored for iterative pruning, little is known what effect pruning has on zero-shot test performance and its potential implications on the choice of pruning criteria. This pruning setup is particularly important for cross-lingual models that implicitly learn alignment between language representations during pretraining, which if distorted via pruning, not only leads to poorer performance on language data used for retraining but also on zero-shot languages that are evaluated. In this work, we show that there is a clear performance discrepancy in magnitude-based pruning when comparing standard supervised learning to the zero-shot setting. From this finding, we propose two weight regularizers that aim to maximize the alignment between units of pruned and unpruned networks to mitigate alignment distortion in pruned cross-lingual models and perform well for both non zero-shot and zero-shot settings. We provide experimental results on cross-lingual tasks for the zero-shot setting using XLM-RoBERTa$_{\mathrm{Base}}$, where we also find that pruning has varying degrees of representational degradation depending on the language corresponding to the zero-shot test set. This is also the first study that focuses on cross-lingual language model compression.
Deep Neural Compression Via Concurrent Pruning and Self-Distillation
Sep 30, 2021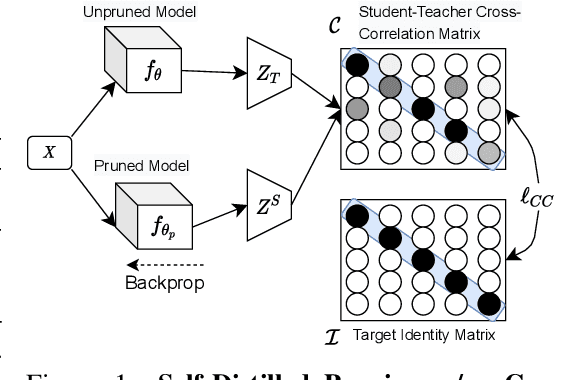
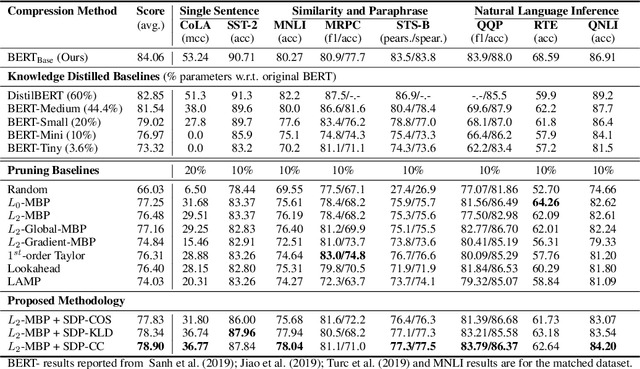
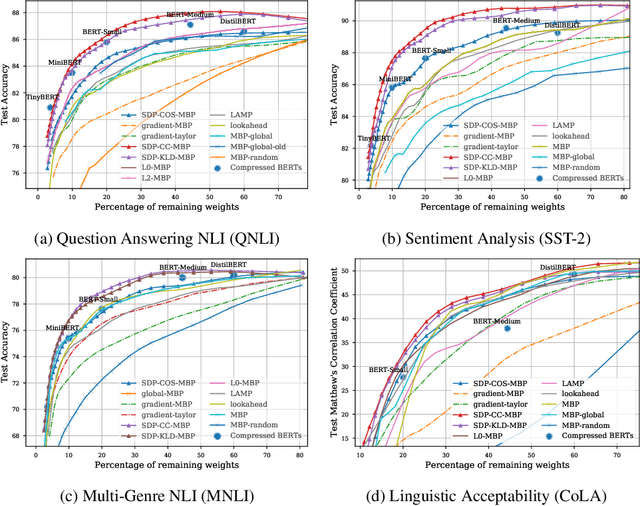
Pruning aims to reduce the number of parameters while maintaining performance close to the original network. This work proposes a novel \emph{self-distillation} based pruning strategy, whereby the representational similarity between the pruned and unpruned versions of the same network is maximized. Unlike previous approaches that treat distillation and pruning separately, we use distillation to inform the pruning criteria, without requiring a separate student network as in knowledge distillation. We show that the proposed {\em cross-correlation objective for self-distilled pruning} implicitly encourages sparse solutions, naturally complementing magnitude-based pruning criteria. Experiments on the GLUE and XGLUE benchmarks show that self-distilled pruning increases mono- and cross-lingual language model performance. Self-distilled pruned models also outperform smaller Transformers with an equal number of parameters and are competitive against (6 times) larger distilled networks. We also observe that self-distillation (1) maximizes class separability, (2) increases the signal-to-noise ratio, and (3) converges faster after pruning steps, providing further insights into why self-distilled pruning improves generalization.
EdinSaar@WMT21: North-Germanic Low-Resource Multilingual NMT
Sep 29, 2021
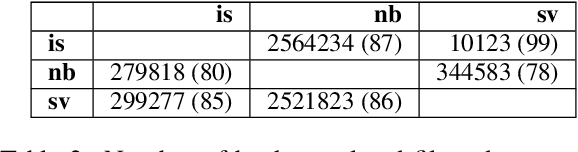
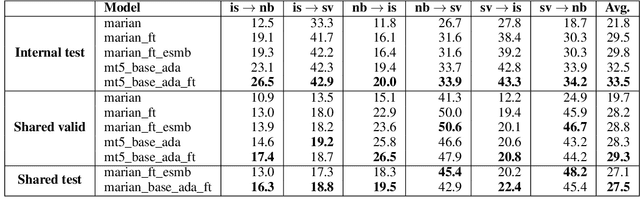
We describe the EdinSaar submission to the shared task of Multilingual Low-Resource Translation for North Germanic Languages at the Sixth Conference on Machine Translation (WMT2021). We submit multilingual translation models for translations to/from Icelandic (is), Norwegian-Bokmal (nb), and Swedish (sv). We employ various experimental approaches, including multilingual pre-training, back-translation, fine-tuning, and ensembling. In most translation directions, our models outperform other submitted systems.
Sequence-to-Sequence Learning on Keywords for Efficient FAQ Retrieval
Aug 23, 2021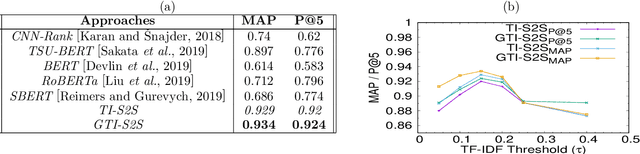
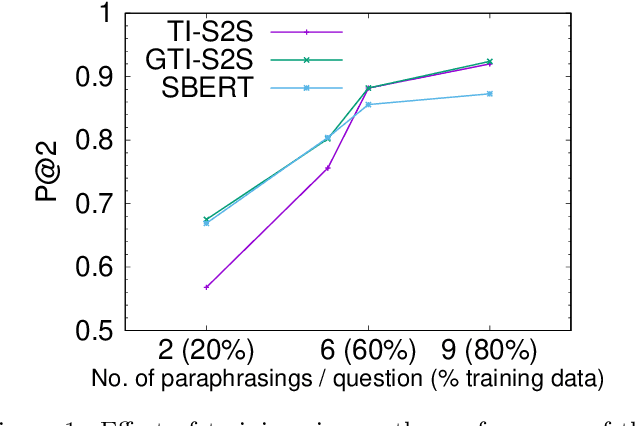
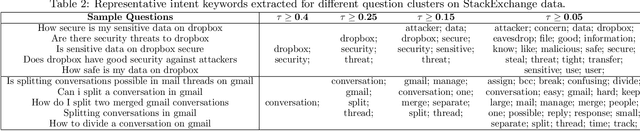
Frequently-Asked-Question (FAQ) retrieval provides an effective procedure for responding to user's natural language based queries. Such platforms are becoming common in enterprise chatbots, product question answering, and preliminary technical support for customers. However, the challenge in such scenarios lies in bridging the lexical and semantic gap between varied query formulations and the corresponding answers, both of which typically have a very short span. This paper proposes TI-S2S, a novel learning framework combining TF-IDF based keyword extraction and Word2Vec embeddings for training a Sequence-to-Sequence (Seq2Seq) architecture. It achieves high precision for FAQ retrieval by better understanding the underlying intent of a user question captured via the representative keywords. We further propose a variant with an additional neural network module for guiding retrieval via relevant candidate identification based on similarity features. Experiments on publicly available dataset depict our approaches to provide around 92% precision-at-rank-5, exhibiting nearly 13% improvement over existing approaches.
* 6 pages
Data-driven reduced order modeling of environmental hydrodynamics using deep autoencoders and neural ODEs
Jul 06, 2021

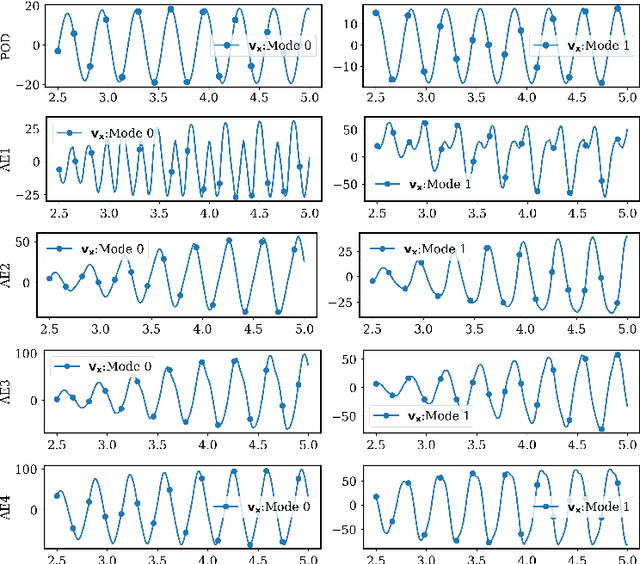
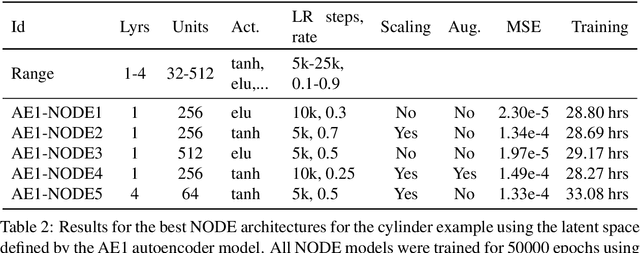
Model reduction for fluid flow simulation continues to be of great interest across a number of scientific and engineering fields. In a previous work [arXiv:2104.13962], we explored the use of Neural Ordinary Differential Equations (NODE) as a non-intrusive method for propagating the latent-space dynamics in reduced order models. Here, we investigate employing deep autoencoders for discovering the reduced basis representation, the dynamics of which are then approximated by NODE. The ability of deep autoencoders to represent the latent-space is compared to the traditional proper orthogonal decomposition (POD) approach, again in conjunction with NODE for capturing the dynamics. Additionally, we compare their behavior with two classical non-intrusive methods based on POD and radial basis function interpolation as well as dynamic mode decomposition. The test problems we consider include incompressible flow around a cylinder as well as a real-world application of shallow water hydrodynamics in an estuarine system. Our findings indicate that deep autoencoders can leverage nonlinear manifold learning to achieve a highly efficient compression of spatial information and define a latent-space that appears to be more suitable for capturing the temporal dynamics through the NODE framework.
Neural Ordinary Differential Equations for Data-Driven Reduced Order Modeling of Environmental Hydrodynamics
Apr 22, 2021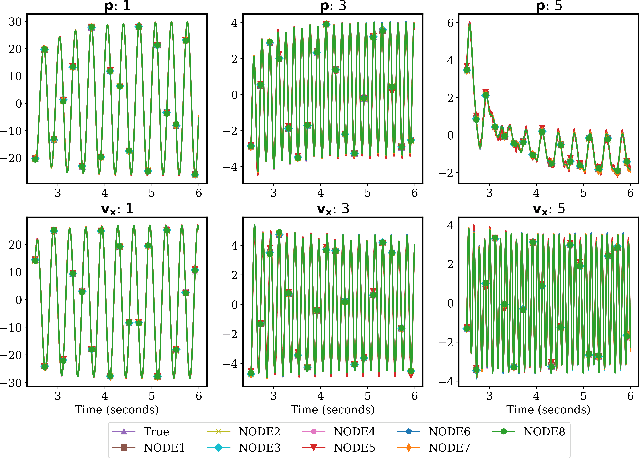
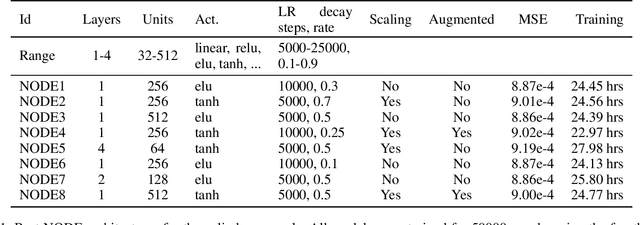
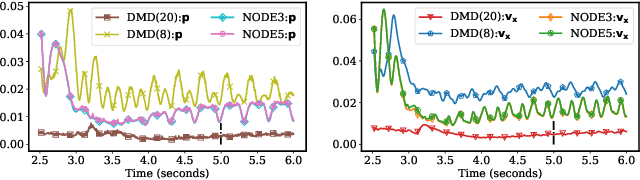
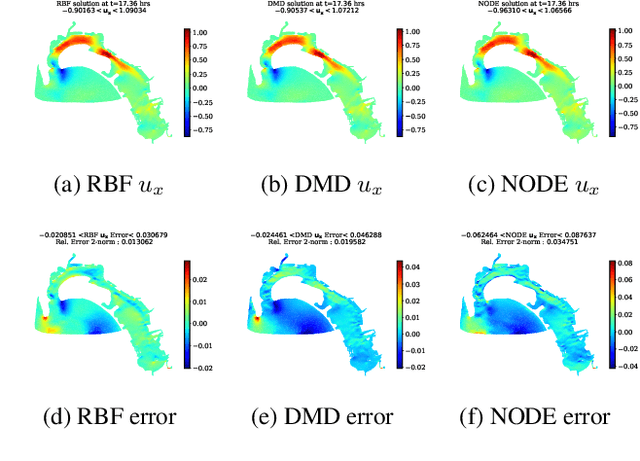
Model reduction for fluid flow simulation continues to be of great interest across a number of scientific and engineering fields. Here, we explore the use of Neural Ordinary Differential Equations, a recently introduced family of continuous-depth, differentiable networks (Chen et al 2018), as a way to propagate latent-space dynamics in reduced order models. We compare their behavior with two classical non-intrusive methods based on proper orthogonal decomposition and radial basis function interpolation as well as dynamic mode decomposition. The test problems we consider include incompressible flow around a cylinder as well as real-world applications of shallow water hydrodynamics in riverine and estuarine systems. Our findings indicate that Neural ODEs provide an elegant framework for stable and accurate evolution of latent-space dynamics with a promising potential of extrapolatory predictions. However, in order to facilitate their widespread adoption for large-scale systems, significant effort needs to be directed at accelerating their training times. This will enable a more comprehensive exploration of the hyperparameter space for building generalizable Neural ODE approximations over a wide range of system dynamics.
Neural Sampling Machine with Stochastic Synapse allows Brain-like Learning and Inference
Feb 20, 2021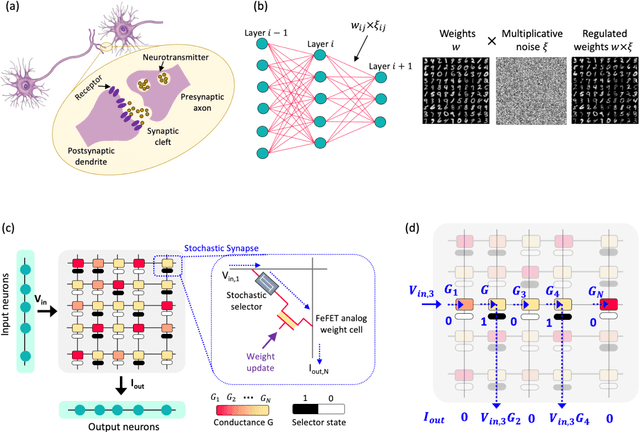
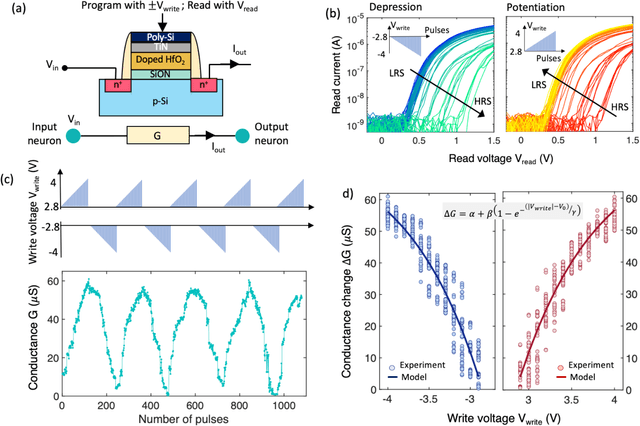
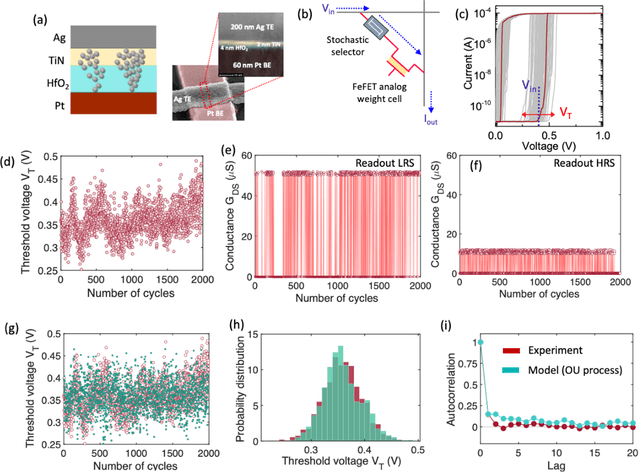
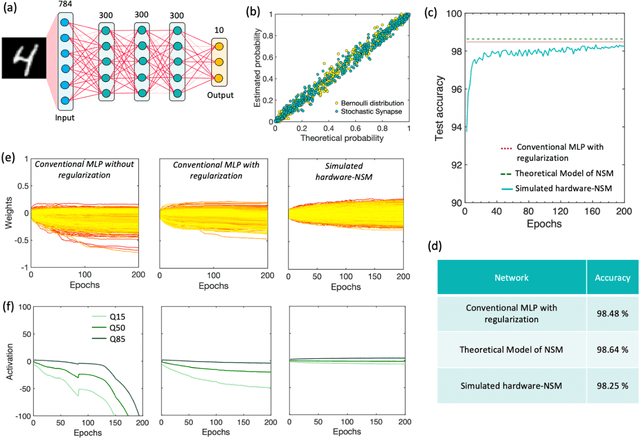
Many real-world mission-critical applications require continual online learning from noisy data and real-time decision making with a defined confidence level. Probabilistic models and stochastic neural networks can explicitly handle uncertainty in data and allow adaptive learning-on-the-fly, but their implementation in a low-power substrate remains a challenge. Here, we introduce a novel hardware fabric that implements a new class of stochastic NN called Neural-Sampling-Machine that exploits stochasticity in synaptic connections for approximate Bayesian inference. Harnessing the inherent non-linearities and stochasticity occurring at the atomic level in emerging materials and devices allows us to capture the synaptic stochasticity occurring at the molecular level in biological synapses. We experimentally demonstrate in-silico hybrid stochastic synapse by pairing a ferroelectric field-effect transistor -based analog weight cell with a two-terminal stochastic selector element. Such a stochastic synapse can be integrated within the well-established crossbar array architecture for compute-in-memory. We experimentally show that the inherent stochastic switching of the selector element between the insulator and metallic state introduces a multiplicative stochastic noise within the synapses of NSM that samples the conductance states of the FeFET, both during learning and inference. We perform network-level simulations to highlight the salient automatic weight normalization feature introduced by the stochastic synapses of the NSM that paves the way for continual online learning without any offline Batch Normalization. We also showcase the Bayesian inferencing capability introduced by the stochastic synapse during inference mode, thus accounting for uncertainty in data. We report 98.25%accuracy on standard image classification task as well as estimation of data uncertainty in rotated samples.
Unsupervised Word Translation Pairing using Refinement based Point Set Registration
Nov 26, 2020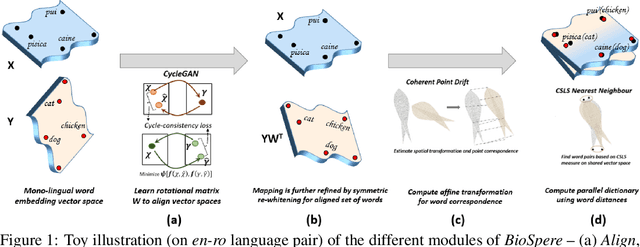
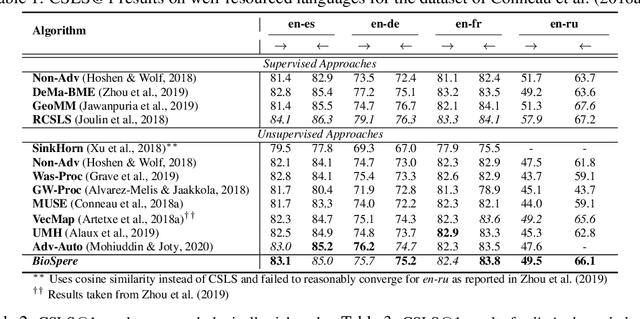

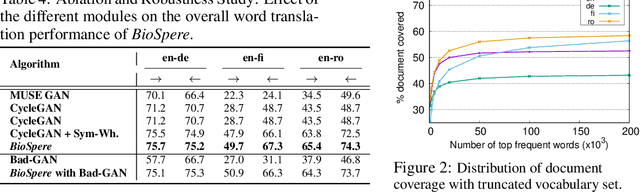
Cross-lingual alignment of word embeddings play an important role in knowledge transfer across languages, for improving machine translation and other multi-lingual applications. Current unsupervised approaches rely on similarities in geometric structure of word embedding spaces across languages, to learn structure-preserving linear transformations using adversarial networks and refinement strategies. However, such techniques, in practice, tend to suffer from instability and convergence issues, requiring tedious fine-tuning for precise parameter setting. This paper proposes BioSpere, a novel framework for unsupervised mapping of bi-lingual word embeddings onto a shared vector space, by combining adversarial initialization and refinement procedure with point set registration algorithm used in image processing. We show that our framework alleviates the shortcomings of existing methodologies, and is relatively invariant to variable adversarial learning performance, depicting robustness in terms of parameter choices and training losses. Experimental evaluation on parallel dictionary induction task demonstrates state-of-the-art results for our framework on diverse language pairs.
Predictive Probability Path Planning Model For Dynamic Environments
Jul 29, 2020
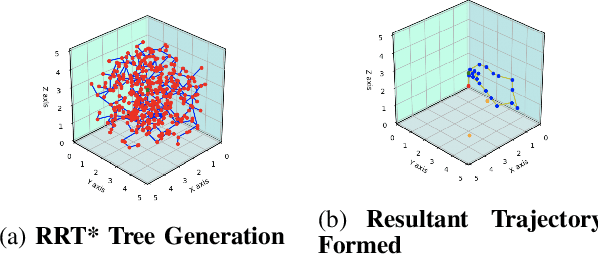
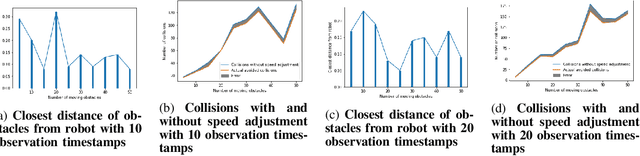
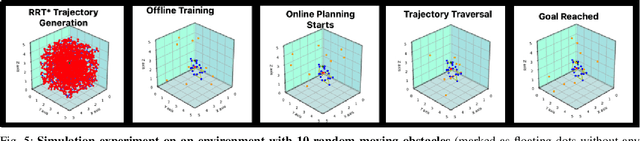
Path planning in dynamic environments is essential to high-risk applications such as unmanned aerial vehicles, self-driving cars, and autonomous underwater vehicles. In this paper, we generate collision-free trajectories for a robot within any given environment with temporal and spatial uncertainties caused due to randomly moving obstacles. We use two Poisson distributions to model the movements of obstacles across the generated trajectory of a robot in both space and time to determine the probability of collision with an obstacle. Measures are taken to avoid an obstacle by intelligently manipulating the speed of the robot at space-time intervals where a larger number of obstacles intersect the trajectory of the robot. Our method potentially reduces the use of computationally expensive collision detection libraries. Based on our experiments, there has been a significant improvement over existing methods in terms of safety, accuracy, execution time and computational cost. Our results show a high level of accuracy between the predicted and actual number of collisions with moving obstacles.
Towards Quantifying the Distance between Opinions
Jan 27, 2020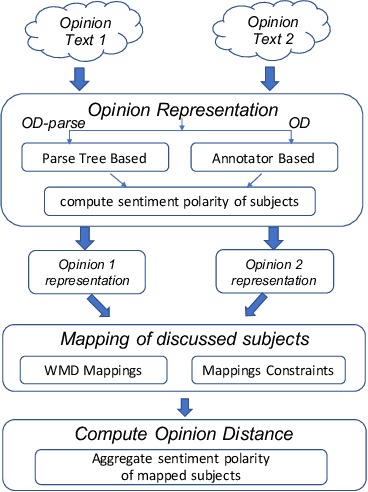


Increasingly, critical decisions in public policy, governance, and business strategy rely on a deeper understanding of the needs and opinions of constituent members (e.g. citizens, shareholders). While it has become easier to collect a large number of opinions on a topic, there is a necessity for automated tools to help navigate the space of opinions. In such contexts understanding and quantifying the similarity between opinions is key. We find that measures based solely on text similarity or on overall sentiment often fail to effectively capture the distance between opinions. Thus, we propose a new distance measure for capturing the similarity between opinions that leverages the nuanced observation -- similar opinions express similar sentiment polarity on specific relevant entities-of-interest. Specifically, in an unsupervised setting, our distance measure achieves significantly better Adjusted Rand Index scores (up to 56x) and Silhouette coefficients (up to 21x) compared to existing approaches. Similarly, in a supervised setting, our opinion distance measure achieves considerably better accuracy (up to 20% increase) compared to extant approaches that rely on text similarity, stance similarity, and sentiment similarity