 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Coarse-grained Visual Language Navigation Task Planning Enhanced by Event Knowledge Graph
Aug 05, 2024Visual language navigation (VLN) is one of the important research in embodied AI. It aims to enable an agent to understand the surrounding environment and complete navigation tasks. VLN instructions could be categorized into coarse-grained and fine-grained commands. Fine-grained command describes a whole task with subtasks step-by-step. In contrast, coarse-grained command gives an abstract task description, which more suites human habits. Most existing work focuses on the former kind of instruction in VLN tasks, ignoring the latter abstract instructions belonging to daily life scenarios. To overcome the above challenge in abstract instruction, we attempt to consider coarse-grained instruction in VLN by event knowledge enhancement. Specifically, we first propose a prompt-based framework to extract an event knowledge graph (named VLN-EventKG) for VLN integrally over multiple mainstream benchmark datasets. Through small and large language model collaboration, we realize knowledge-enhanced navigation planning (named EventNav) for VLN tasks with coarse-grained instruction input. Additionally, we design a novel dynamic history backtracking module to correct potential error action planning in real time. Experimental results in various public benchmarks show our knowledge-enhanced method has superiority in coarse-grained-instruction VLN using our proposed VLN-EventKG with over $5\%$ improvement in success rate. Our project is available at https://sites.google.com/view/vln-eventkg
Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI
Nov 07, 2023Embodied AI is one of the most popular studies in artificial intelligence and robotics, which can effectively improve the intelligence of real-world agents (i.e. robots) serving human beings. Scene knowledge is important for an agent to understand the surroundings and make correct decisions in the varied open world. Currently, knowledge base for embodied tasks is missing and most existing work use general knowledge base or pre-trained models to enhance the intelligence of an agent. For conventional knowledge base, it is sparse, insufficient in capacity and cost in data collection. For pre-trained models, they face the uncertainty of knowledge and hard maintenance. To overcome the challenges of scene knowledge, we propose a scene-driven multimodal knowledge graph (Scene-MMKG) construction method combining conventional knowledge engineering and large language models. A unified scene knowledge injection framework is introduced for knowledge representation. To evaluate the advantages of our proposed method, we instantiate Scene-MMKG considering typical indoor robotic functionalities (Manipulation and Mobility), named ManipMob-MMKG. Comparisons in characteristics indicate our instantiated ManipMob-MMKG has broad superiority in data-collection efficiency and knowledge quality. Experimental results on typical embodied tasks show that knowledge-enhanced methods using our instantiated ManipMob-MMKG can improve the performance obviously without re-designing model structures complexly. Our project can be found at https://sites.google.com/view/manipmob-mmkg
2.5D Image based Robotic Grasping
May 31, 2019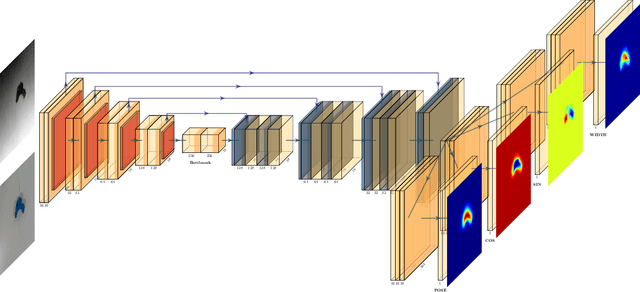

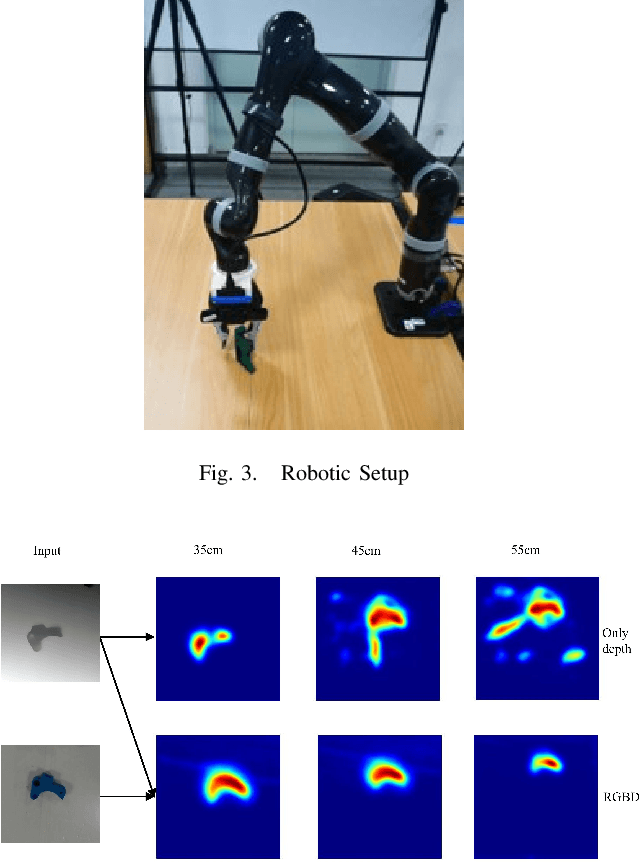
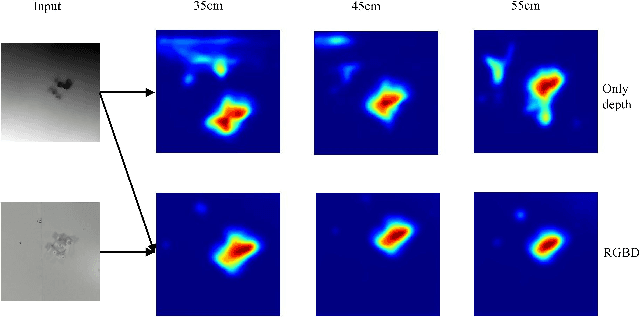
We consider the problem of robotic grasping using depth + RGB information sampling from a real sensor. we design an encoder-decoder neural network to predict grasp policy in real time. This method can fuse the advantage of depth image and RGB image at the same time and is robust for grasp and observation height.We evaluate our method in a physical robotic system and propose an open-loop algorithm to realize robotic grasp operation. We analyze the result of experiment from multi-perspective and the result shows that our method is competitive with the state-of-the-art in grasp performance, real-time and model size. The video is available in https://youtu.be/Wxw_r5a8qV0