 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of the composition of feature extraction and class sampling in medicare fraud detection
Jun 03, 2022
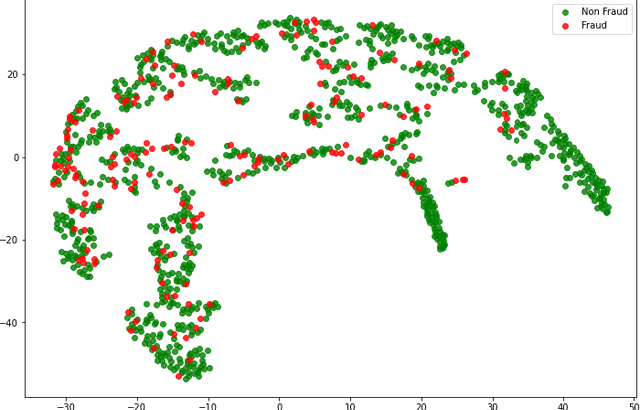
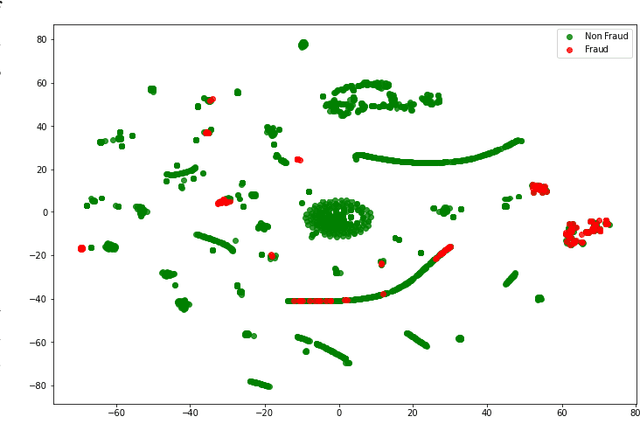
With healthcare being critical aspect, health insurance has become an important scheme in minimizing medical expenses. Following this, the healthcare industry has seen a significant increase in fraudulent activities owing to increased insurance, and fraud has become a significant contributor to rising medical care expenses, although its impact can be mitigated using fraud detection techniques. To detect fraud, machine learning techniques are used. The Centers for Medicaid and Medicare Services (CMS) of the United States federal government released "Medicare Part D" insurance claims is utilized in this study to develop fraud detection system. Employing machine learning algorithms on a class-imbalanced and high dimensional medicare dataset is a challenging task. To compact such challenges, the present work aims to perform feature extraction following data sampling, afterward applying various classification algorithms, to get better performance. Feature extraction is a dimensionality reduction approach that converts attributes into linear or non-linear combinations of the actual attributes, generating a smaller and more diversified set of attributes and thus reducing the dimensions. Data sampling is commonlya used to address the class imbalance either by expanding the frequency of minority class or reducing the frequency of majority class to obtain approximately equal numbers of occurrences for both classes. The proposed approach is evaluated through standard performance metrics. Thus, to detect fraud efficiently, this study applies autoencoder as a feature extraction technique, synthetic minority oversampling technique (SMOTE) as a data sampling technique, and various gradient boosted decision tree-based classifiers as a classification algorithm. The experimental results show the combination of autoencoders followed by SMOTE on the LightGBM classifier achieved best results.
Empirical Analysis of Lifelog Data using Optimal Feature Selection based Unsupervised Logistic Regression (OFS-ULR) Model with Spark Streaming
Apr 12, 2022



Recent advancement in the field of pervasive healthcare monitoring systems causes the generation of a huge amount of lifelog data in real-time. Chronic diseases are one of the most serious health challenges in developing and developed countries. According to WHO, this accounts for 73% of all deaths and 60% of the global burden of diseases. Chronic disease classification models are now harnessing the potential of lifelog data to explore better healthcare practices. This paper is to construct an optimal feature selection-based unsupervised logistic regression model (OFS-ULR) to classify chronic diseases. Since lifelog data analysis is crucial due to its sensitive nature; thus the conventional classification models show limited performance. Therefore, designing new classifiers for the classification of chronic diseases using lifelog data is the need of the age. The vital part of building a good model depends on pre-processing of the dataset, identifying important features, and then training a learning algorithm with suitable hyper parameters for better performance. The proposed approach improves the performance of existing methods using a series of steps such as (i) removing redundant or invalid instances, (ii) making the data labelled using clustering and partitioning the data into classes, (iii) identifying the suitable subset of features by applying either some domain knowledge or selection algorithm, (iv) hyper parameter tuning for models to get best results, and (v) performance evaluation using Spark streaming environment. For this purpose, two-time series datasets are used in the experiment to compute the accuracy, recall, precision, and f1-score. The experimental analysis proves the suitability of the proposed approach as compared to the conventional classifiers and our newly constructed model achieved highest accuracy and reduced training complexity among all among all.
An optimized hybrid solution for IoT based lifestyle disease classification using stress data
Apr 04, 2022



Stress, anxiety, and nervousness are all high-risk health states in everyday life. Previously, stress levels were determined by speaking with people and gaining insight into what they had experienced recently or in the past. Typically, stress is caused by an incidence that occurred a long time ago, but sometimes it is triggered by unknown factors. This is a challenging and complex task, but recent research advances have provided numerous opportunities to automate it. The fundamental features of most of these techniques are electro dermal activity (EDA) and heart rate values (HRV). We utilized an accelerometer to measure body motions to solve this challenge. The proposed novel method employs a test that measures a subject's electrocardiogram (ECG), galvanic skin values (GSV), HRV values, and body movements in order to provide a low-cost and time-saving solution for detecting stress lifestyle disease in modern times using cyber physical systems. This study provides a new hybrid model for lifestyle disease classification that decreases execution time while picking the best collection of characteristics and increases classification accuracy. The developed approach is capable of dealing with the class imbalance problem by using WESAD (wearable stress and affect dataset) dataset. The new model uses the Grid search (GS) method to select an optimized set of hyper parameters, and it uses a combination of the Correlation coefficient based Recursive feature elimination (CoC-RFE) method for optimal feature selection and gradient boosting as an estimator to classify the dataset, which achieves high accuracy and helps to provide smart, accurate, and high-quality healthcare systems. To demonstrate the validity and utility of the proposed methodology, its performance is compared to those of other well-established machine learning models.
Semantic Sensor Network Ontology based Decision Support System for Forest Fire Management
Apr 03, 2022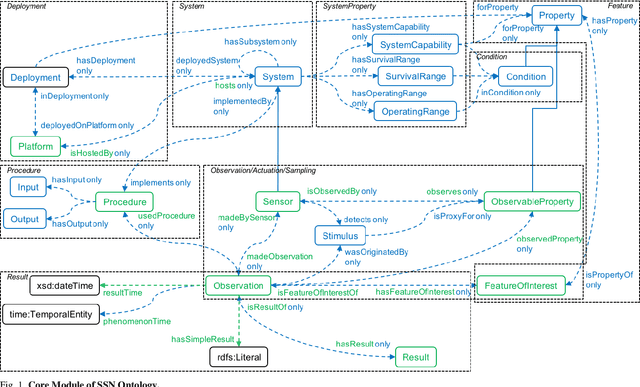



The forests are significant assets for every country. When it gets destroyed, it may negatively impact the environment, and forest fire is one of the primary causes. Fire weather indices are widely used to measure fire danger and are used to issue bushfire warnings. It can also be used to predict the demand for emergency management resources. Sensor networks have grown in popularity in data collection and processing capabilities for a variety of applications in industries such as medical, environmental monitoring, home automation etc. Semantic sensor networks can collect various climatic circumstances like wind speed, temperature, and relative humidity. However, estimating fire weather indices is challenging due to the various issues involved in processing the data streams generated by the sensors. Hence, the importance of forest fire detection has increased day by day. The underlying Semantic Sensor Network (SSN) ontologies are built to allow developers to create rules for calculating fire weather indices and also the convert dataset into Resource Description Framework (RDF). This research describes the various steps involved in developing rules for calculating fire weather indices. Besides, this work presents a Web-based mapping interface to help users visualize the changes in fire weather indices over time. With the help of the inference rule, it designed a decision support system using the SSN ontology and query on it through SPARQL. The proposed fire management system acts according to the situation, supports reasoning and the general semantics of the open-world followed by all the ontologies
BT-Unet: A self-supervised learning framework for biomedical image segmentation using Barlow Twins with U-Net models
Jan 02, 2022



Deep learning has brought the most profound contribution towards biomedical image segmentation to automate the process of delineation in medical imaging. To accomplish such task, the models are required to be trained using huge amount of annotated or labelled data that highlights the region of interest with a binary mask. However, efficient generation of the annotations for such huge data requires expert biomedical analysts and extensive manual effort. It is a tedious and expensive task, while also being vulnerable to human error. To address this problem, a self-supervised learning framework, BT-Unet is proposed that uses the Barlow Twins approach to pre-train the encoder of a U-Net model via redundancy reduction in an unsupervised manner to learn data representation. Later, complete network is fine-tuned to perform actual segmentation. The BT-Unet framework can be trained with a limited number of annotated samples while having high number of unannotated samples, which is mostly the case in real-world problems. This framework is validated over multiple U-Net models over diverse datasets by generating scenarios of a limited number of labelled samples using standard evaluation metrics. With exhaustive experiment trials, it is observed that the BT-Unet framework enhances the performance of the U-Net models with significant margin under such circumstances.
Impact of Attention on Adversarial Robustness of Image Classification Models
Sep 02, 2021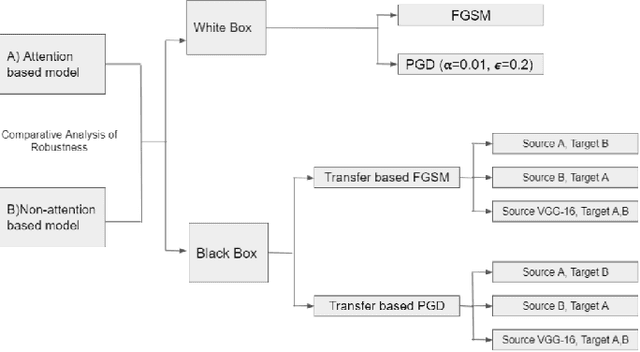
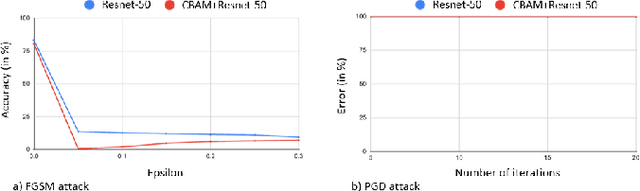
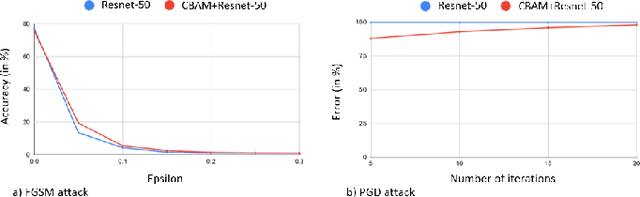
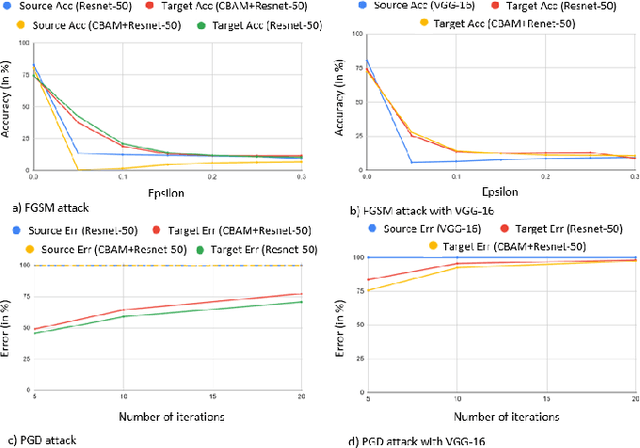
Adversarial attacks against deep learning models have gained significant attention and recent works have proposed explanations for the existence of adversarial examples and techniques to defend the models against these attacks. Attention in computer vision has been used to incorporate focused learning of important features and has led to improved accuracy. Recently, models with attention mechanisms have been proposed to enhance adversarial robustness. Following this context, this work aims at a general understanding of the impact of attention on adversarial robustness. This work presents a comparative study of adversarial robustness of non-attention and attention based image classification models trained on CIFAR-10, CIFAR-100 and Fashion MNIST datasets under the popular white box and black box attacks. The experimental results show that the robustness of attention based models may be dependent on the datasets used i.e. the number of classes involved in the classification. In contrast to the datasets with less number of classes, attention based models are observed to show better robustness towards classification.
White blood cell subtype detection and classification
Aug 10, 2021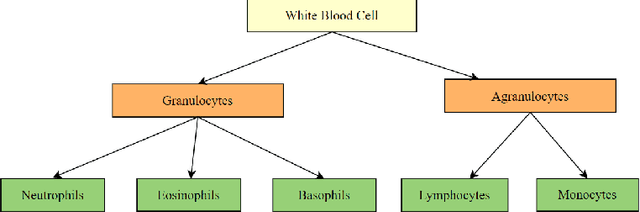
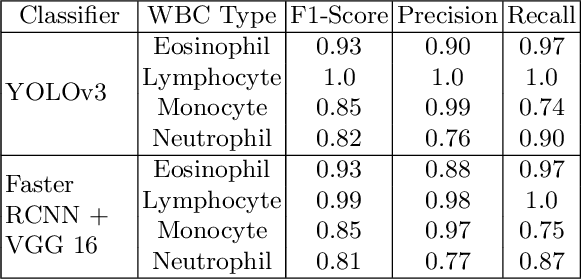
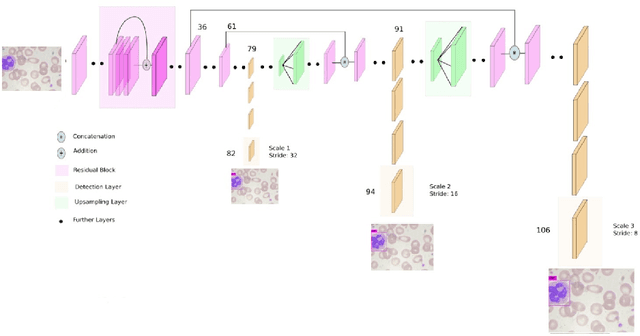
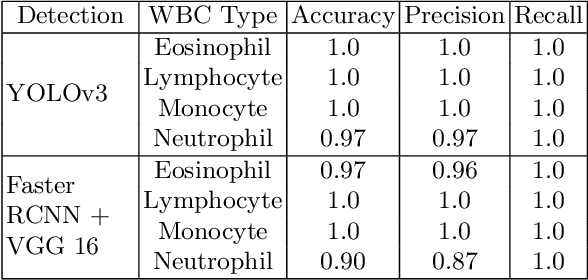
Machine learning has endless applications in the health care industry. White blood cell classification is one of the interesting and promising area of research. The classification of the white blood cells plays an important part in the medical diagnosis. In practise white blood cell classification is performed by the haematologist by taking a small smear of blood and careful examination under the microscope. The current procedures to identify the white blood cell subtype is more time taking and error-prone. The computer aided detection and diagnosis of the white blood cells tend to avoid the human error and reduce the time taken to classify the white blood cells. In the recent years several deep learning approaches have been developed in the context of classification of the white blood cells that are able to identify but are unable to localize the positions of white blood cells in the blood cell image. Following this, the present research proposes to utilize YOLOv3 object detection technique to localize and classify the white blood cells with bounding boxes. With exhaustive experimental analysis, the proposed work is found to detect the white blood cell with 99.2% accuracy and classify with 90% accuracy.
RCA-IUnet: A residual cross-spatial attention guided inception U-Net model for tumor segmentation in breast ultrasound imaging
Aug 05, 2021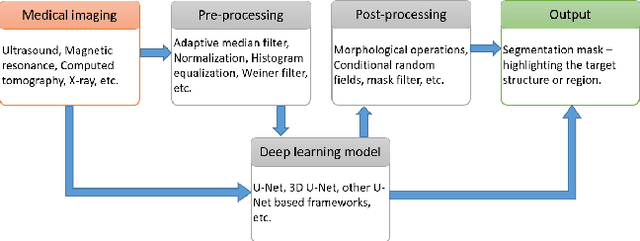



The advancements in deep learning technologies have produced immense contribution to biomedical image analysis applications. With breast cancer being the common deadliest disease among women, early detection is the key means to improve survivability. Medical imaging like ultrasound presents an excellent visual representation of the functioning of the organs; however, for any radiologist analysing such scans is challenging and time consuming which delays the diagnosis process. Although various deep learning based approaches are proposed that achieved promising results, the present article introduces an efficient residual cross-spatial attention guided inception U-Net (RCA-IUnet) model with minimal training parameters for tumor segmentation using breast ultrasound imaging to further improve the segmentation performance of varying tumor sizes. The RCA-IUnet model follows U-Net topology with residual inception depth-wise separable convolution and hybrid pooling (max pooling and spectral pooling) layers. In addition, cross-spatial attention filters are added to suppress the irrelevant features and focus on the target structure. The segmentation performance of the proposed model is validated on two publicly available datasets using standard segmentation evaluation metrics, where it outperformed the other state-of-the-art segmentation models.
MAG-Net: Mutli-task attention guided network for brain tumor segmentation and classification
Jul 26, 2021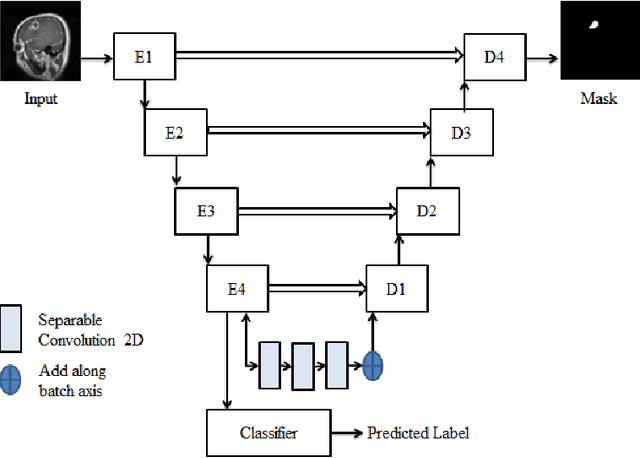
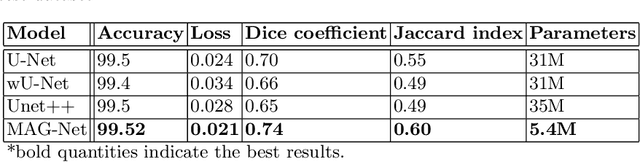
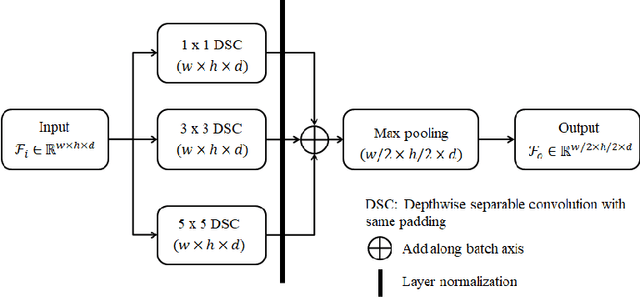
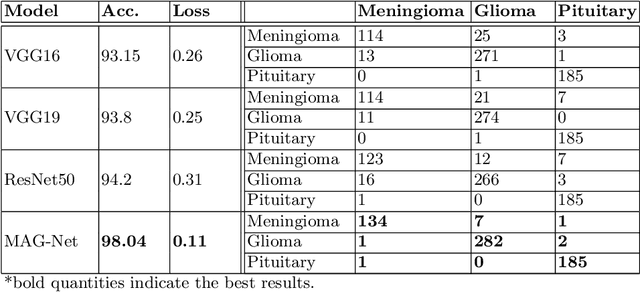
Brain tumor is the most common and deadliest disease that can be found in all age groups. Generally, MRI modality is adopted for identifying and diagnosing tumors by the radiologists. The correct identification of tumor regions and its type can aid to diagnose tumors with the followup treatment plans. However, for any radiologist analysing such scans is a complex and time-consuming task. Motivated by the deep learning based computer-aided-diagnosis systems, this paper proposes multi-task attention guided encoder-decoder network (MAG-Net) to classify and segment the brain tumor regions using MRI images. The MAG-Net is trained and evaluated on the Figshare dataset that includes coronal, axial, and sagittal views with 3 types of tumors meningioma, glioma, and pituitary tumor. With exhaustive experimental trials the model achieved promising results as compared to existing state-of-the-art models, while having least number of training parameters among other state-of-the-art models.
Recommending best course of treatment based on similarities of prognostic markers
Jul 19, 2021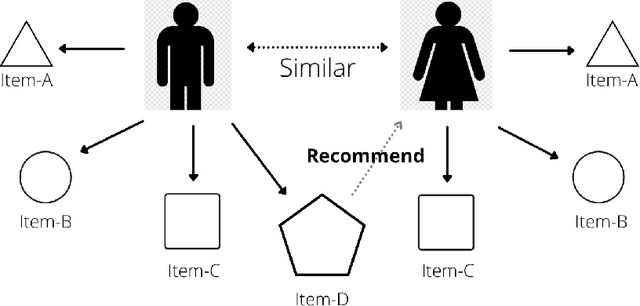
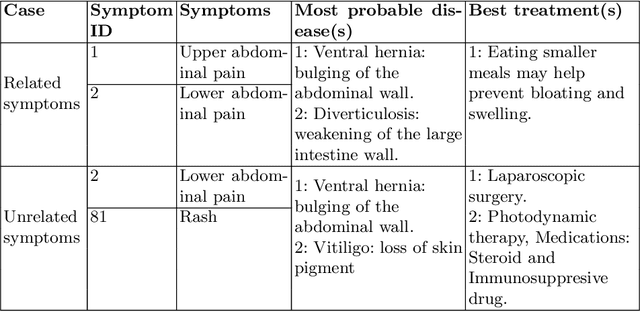

With the advancement in the technology sector spanning over every field, a huge influx of information is inevitable. Among all the opportunities that the advancements in the technology have brought, one of them is to propose efficient solutions for data retrieval. This means that from an enormous pile of data, the retrieval methods should allow the users to fetch the relevant and recent data over time. In the field of entertainment and e-commerce, recommender systems have been functioning to provide the aforementioned. Employing the same systems in the medical domain could definitely prove to be useful in variety of ways. Following this context, the goal of this paper is to propose collaborative filtering based recommender system in the healthcare sector to recommend remedies based on the symptoms experienced by the patients. Furthermore, a new dataset is developed consisting of remedies concerning various diseases to address the limited availability of the data. The proposed recommender system accepts the prognostic markers of a patient as the input and generates the best remedy course. With several experimental trials, the proposed model achieved promising results in recommending the possible remedy for given prognostic markers.