 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proposed Biomedical Data Policy Framework to Reduce Fragmentation, Improve Quality, and Incentivize Sharing in Indian Healthcare in the era of Artificial Intelligence and Digital Health
Apr 13, 2026India generates vast biomedical data through postgraduate research, government hospital services and audits, government schemes, private hospitals and their electronic medical record (EMR) systems, insurance programs and standalone clinics. Unfortunately, these resources remain fragmented across institutional silos and vendor-locked EMR systems. The fundamental bottleneck is not technological but economic and academic. There is a systemic misalignment of incentives that renders data sharing a high-risk, low-reward activity for individual researchers and institutions. Until India's academic promotion criteria, institutional rankings, and funding mechanisms explicitly recognize and reward data curation as professional work, the nation's AI ambitions will remain constrained by fragmented, non-interoperable datasets. We propose a multi-layered incentive architecture integrating recognition of data papers in National Medical Commission (NMC) promotion criteria, incorporation of open data metrics into the National Institutional Ranking Framework (NIRF), adoption of Shapley Value-based revenue sharing in federated learning consortia, and establishment of institutional data stewardship as a mainstream professional role. Critical barriers to data sharing, including fear of data quality scrutiny, concerns about misinterpretation, and selective reporting bias, are addressed through mandatory data quality assessment, structured peer review, and academic credit for auditing roles. The proposed framework directly addresses regulatory constraints introduced by the Digital Personal Data Protection Act 2023 (DPDPA), while constructively engaging with the National Data Sharing and Accessibility Policy (NDSAP), Biotech-PRIDE Guidelines, and the Anusandhan National Research Foundation (ANRF) guidelines.
Carbon Emission Prediction on the World Bank Dataset for Canada
Nov 26, 2022



The continuous rise in CO2 emission into the environment is one of the most crucial issues facing the whole world. Many countries are making crucial decisions to control their carbon footprints to escape some of their catastrophic outcomes. There has been a lot of research going on to project the amount of carbon emissions in the future, which can help us to develop innovative techniques to deal with it in advance. Machine learning is one of the most advanced and efficient techniques for predicting the amount of carbon emissions from current data. This paper provides the methods for predicting carbon emissions (CO2 emissions) for the next few years. The predictions are based on data from the past 50 years. The dataset, which is used for making the prediction, is collected from World Bank datasets. This dataset contains CO2 emissions (metric tons per capita) of all the countries from 1960 to 2018. Our method consists of using machine learning techniques to take the idea of what carbon emission measures will look like in the next ten years and project them onto the dataset taken from the World Bank's data repository. The purpose of this research is to compare how different machine learning models (Decision Tree, Linear Regression, Random Forest, and Support Vector Machine) perform on a similar dataset and measure the difference between their predictions.
MAG-Net: Mutli-task attention guided network for brain tumor segmentation and classification
Jul 26, 2021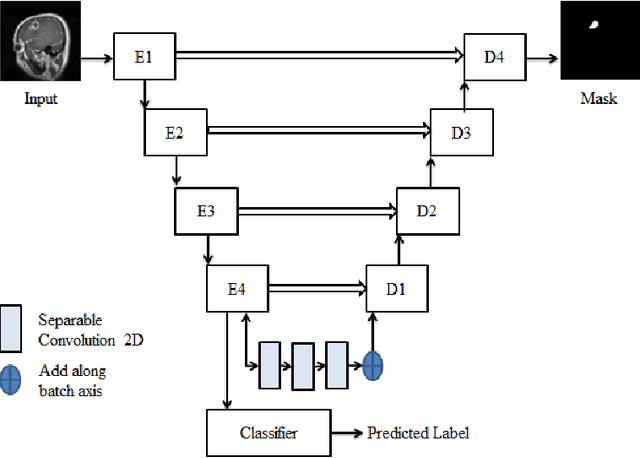
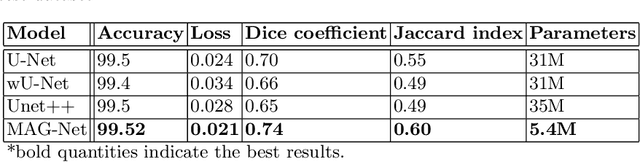
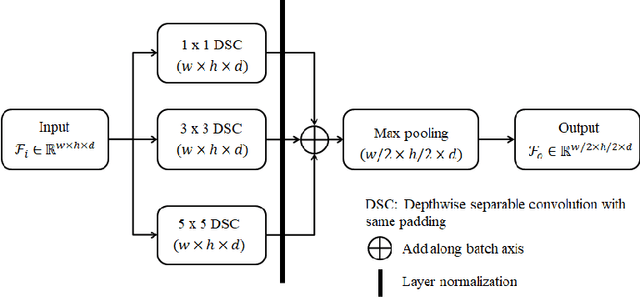
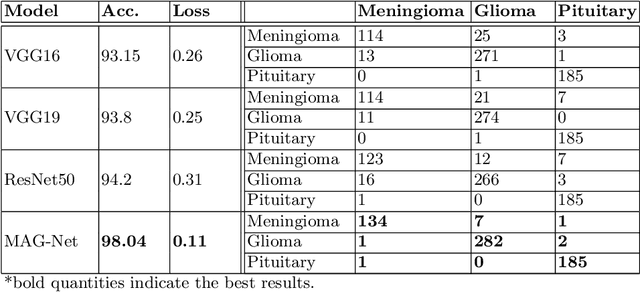
Brain tumor is the most common and deadliest disease that can be found in all age groups. Generally, MRI modality is adopted for identifying and diagnosing tumors by the radiologists. The correct identification of tumor regions and its type can aid to diagnose tumors with the followup treatment plans. However, for any radiologist analysing such scans is a complex and time-consuming task. Motivated by the deep learning based computer-aided-diagnosis systems, this paper proposes multi-task attention guided encoder-decoder network (MAG-Net) to classify and segment the brain tumor regions using MRI images. The MAG-Net is trained and evaluated on the Figshare dataset that includes coronal, axial, and sagittal views with 3 types of tumors meningioma, glioma, and pituitary tumor. With exhaustive experimental trials the model achieved promising results as compared to existing state-of-the-art models, while having least number of training parameters among other state-of-the-art models.