 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text-based Approach For Link Prediction on Wikipedia Articles
Sep 01, 2023



This paper present our work in the DSAA 2023 Challenge about Link Prediction for Wikipedia Articles. We use traditional machine learning models with POS tags (part-of-speech tags) features extracted from text to train the classification model for predicting whether two nodes has the link. Then, we use these tags to test on various machine learning models. We obtained the results by F1 score at 0.99999 and got 7th place in the competition. Our source code is publicly available at this link: https://github.com/Tam1032/DSAA2023-Challenge-Link-prediction-DS-UIT_SAT
A Multiple Choices Reading Comprehension Corpus for Vietnamese Language Education
Mar 31, 2023



Machine reading comprehension has been an interesting and challenging task in recent years, with the purpose of extracting useful information from texts. To attain the computer ability to understand the reading text and answer relevant information, we introduce ViMMRC 2.0 - an extension of the previous ViMMRC for the task of multiple-choice reading comprehension in Vietnamese Textbooks which contain the reading articles for students from Grade 1 to Grade 12. This dataset has 699 reading passages which are prose and poems, and 5,273 questions. The questions in the new dataset are not fixed with four options as in the previous version. Moreover, the difficulty of questions is increased, which challenges the models to find the correct choice. The computer must understand the whole context of the reading passage, the question, and the content of each choice to extract the right answers. Hence, we propose the multi-stage approach that combines the multi-step attention network (MAN) with the natural language inference (NLI) task to enhance the performance of the reading comprehension model. Then, we compare the proposed methodology with the baseline BERTology models on the new dataset and the ViMMRC 1.0. Our multi-stage models achieved 58.81% by Accuracy on the test set, which is 5.34% better than the highest BERTology models. From the results of the error analysis, we found the challenge of the reading comprehension models is understanding the implicit context in texts and linking them together in order to find the correct answers. Finally, we hope our new dataset will motivate further research in enhancing the language understanding ability of computers in the Vietnamese language.
Integrating Image Features with Convolutional Sequence-to-sequence Network for Multilingual Visual Question Answering
Mar 22, 2023



Visual Question Answering (VQA) is a task that requires computers to give correct answers for the input questions based on the images. This task can be solved by humans with ease but is a challenge for computers. The VLSP2022-EVJVQA shared task carries the Visual Question Answering task in the multilingual domain on a newly released dataset: UIT-EVJVQA, in which the questions and answers are written in three different languages: English, Vietnamese and Japanese. We approached the challenge as a sequence-to-sequence learning task, in which we integrated hints from pre-trained state-of-the-art VQA models and image features with Convolutional Sequence-to-Sequence network to generate the desired answers. Our results obtained up to 0.3442 by F1 score on the public test set, 0.4210 on the private test set, and placed 3rd in the competition.
Improving Sentiment Analysis By Emotion Lexicon Approach on Vietnamese Texts
Oct 05, 2022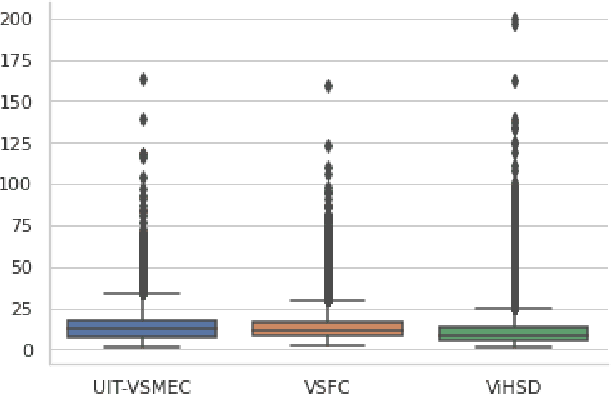
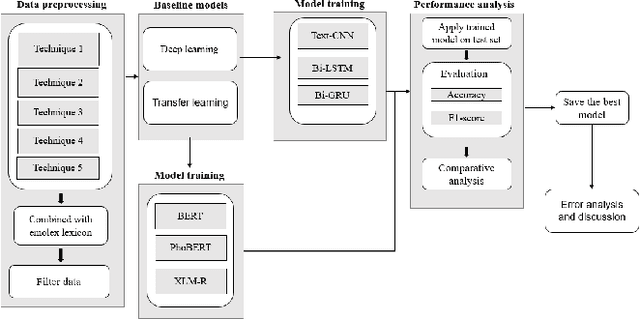
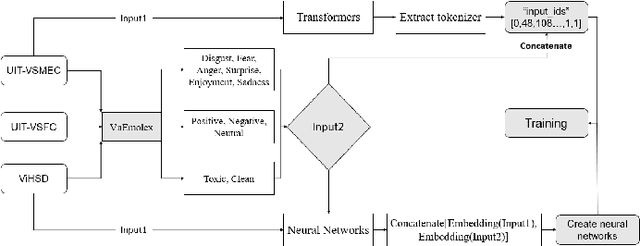

The sentiment analysis task has various applications in practice. In the sentiment analysis task, words and phrases that represent positive and negative emotions are important. Finding out the words that represent the emotion from the text can improve the performance of the classification models for the sentiment analysis task. In this paper, we propose a methodology that combines the emotion lexicon with the classification model for enhancing the accuracy of the models. Our experimental results show that the emotion lexicon combined with the classification model improves the performance of models.
UIT-ViCoV19QA: A Dataset for COVID-19 Community-based Question Answering on Vietnamese Language
Sep 14, 2022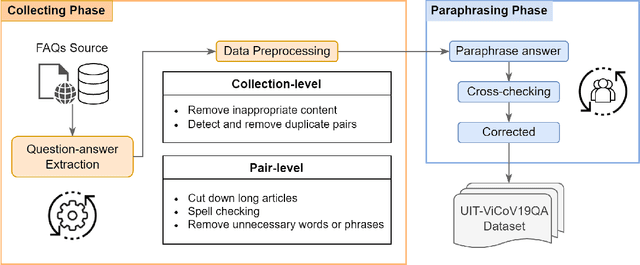
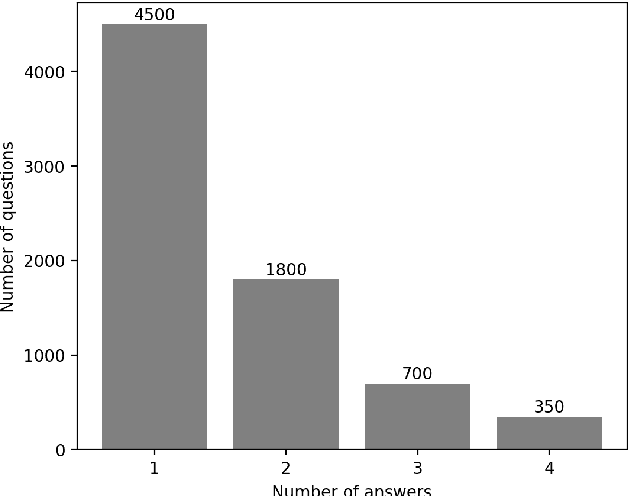
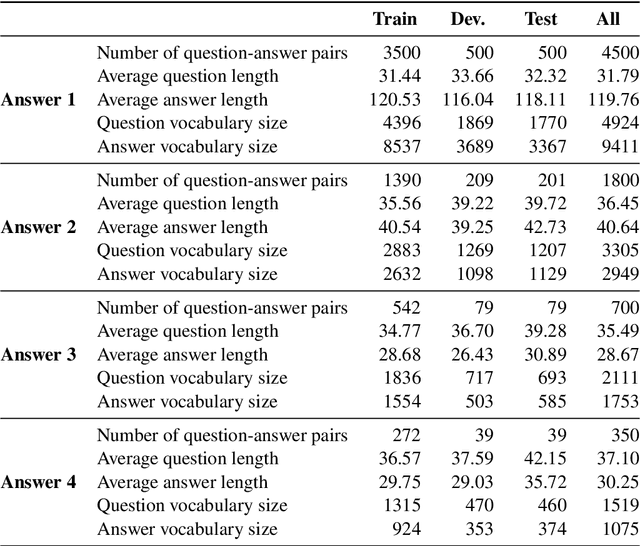
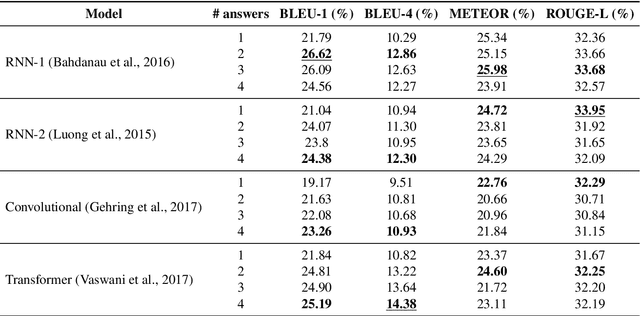
For the last two years, from 2020 to 2021, COVID-19 has broken disease prevention measures in many countries, including Vietnam, and negatively impacted various aspects of human life and the social community. Besides, the misleading information in the community and fake news about the pandemic are also serious situations. Therefore, we present the first Vietnamese community-based question answering dataset for developing question answering systems for COVID-19 called UIT-ViCoV19QA. The dataset comprises 4,500 question-answer pairs collected from trusted medical sources, with at least one answer and at most four unique paraphrased answers per question. Along with the dataset, we set up various deep learning models as baseline to assess the quality of our dataset and initiate the benchmark results for further research through commonly used metrics such as BLEU, METEOR, and ROUGE-L. We also illustrate the positive effects of having multiple paraphrased answers experimented on these models, especially on Transformer - a dominant architecture in the field of study.
Detecting Spam Reviews on Vietnamese E-commerce Websites
Jul 27, 2022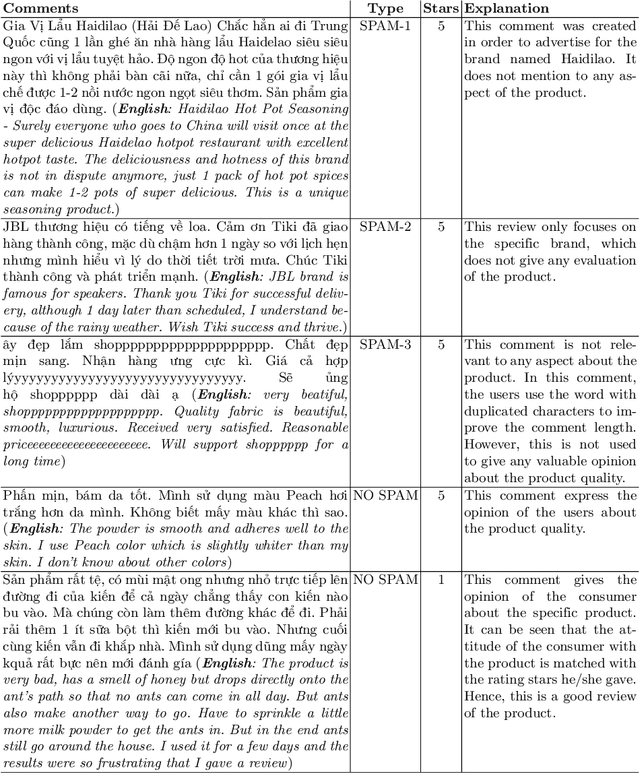
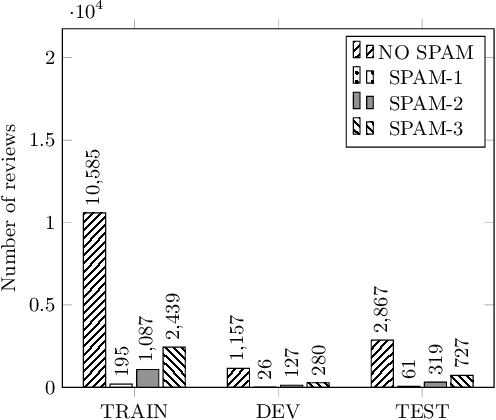

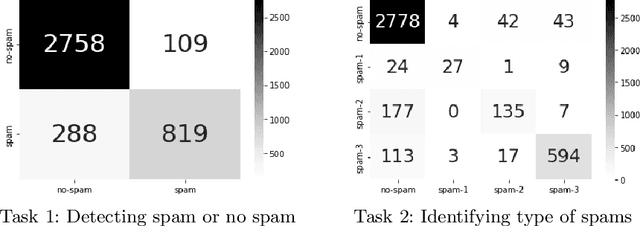
The reviews of customers play an essential role in online shopping. People often refer to reviews or comments of previous customers to decide whether to buy a new product. Catching up with this behavior, some people create untruths and illegitimate reviews to hoax customers about the fake quality of products. These reviews are called spam reviews, which confuse consumers on online shopping platforms and negatively affect online shopping behaviors. We propose the dataset called ViSpamReviews, which has a strict annotation procedure for detecting spam reviews on e-commerce platforms. Our dataset consists of two tasks: the binary classification task for detecting whether a review is a spam or not and the multi-class classification task for identifying the type of spam. The PhoBERT obtained the highest results on both tasks, 88.93% and 72.17%, respectively, by macro average F1 score.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022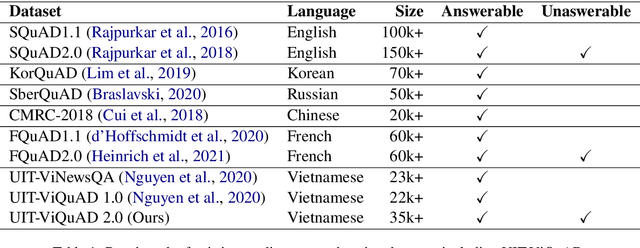
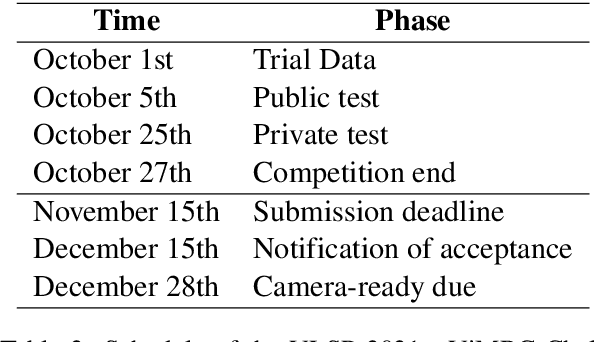
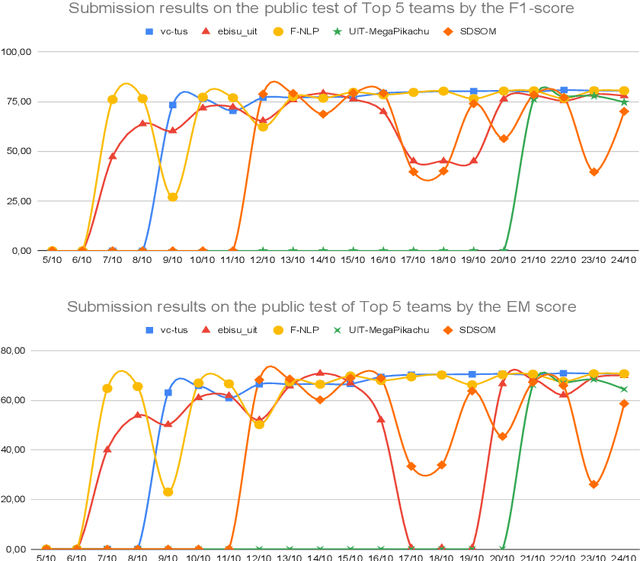

One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.
Predicting Job Titles from Job Descriptions with Multi-label Text Classification
Dec 21, 2021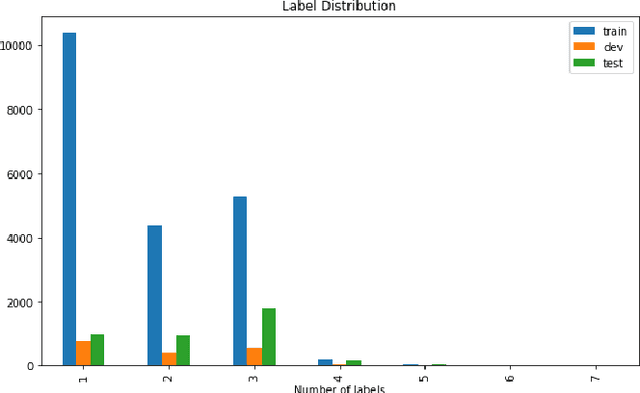
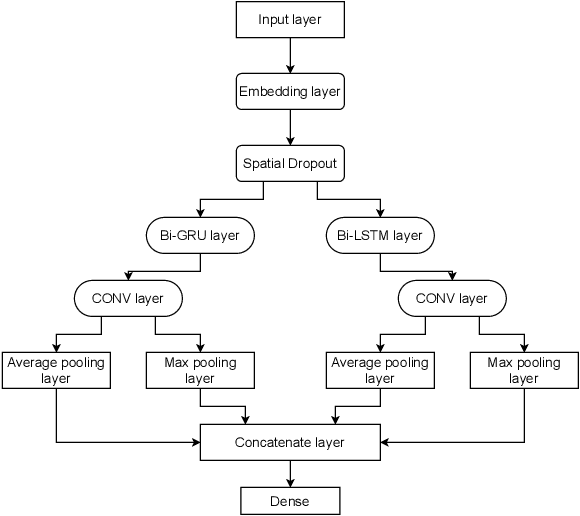


Finding a suitable job and hunting for eligible candidates are important to job seeking and human resource agencies. With the vast information about job descriptions, employees and employers need assistance to automatically detect job titles based on job description texts. In this paper, we propose the multi-label classification approach for predicting relevant job titles from job description texts, and implement the Bi-GRU-LSTM-CNN with different pre-trained language models to apply for the job titles prediction problem. The BERT with multilingual pre-trained model obtains the highest result by F1-scores on both development and test sets, which are 62.20% on the development set, and 47.44% on the test set.
Automatically Detecting Cyberbullying Comments on Online Game Forums
Jun 03, 2021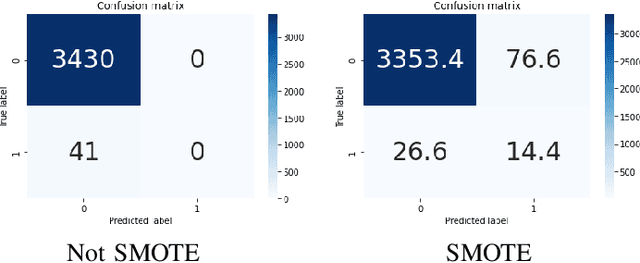
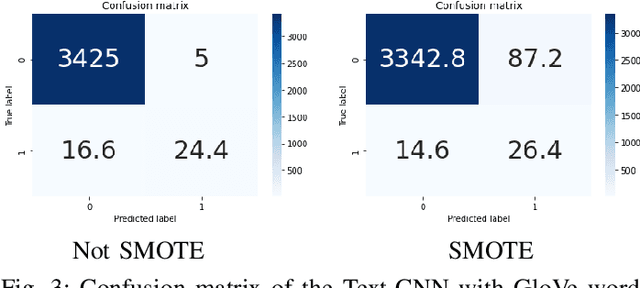
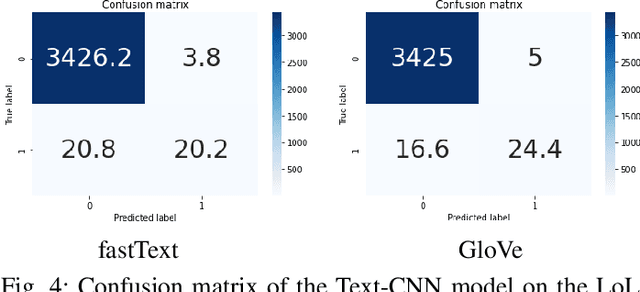

Online game forums are popular to most of game players. They use it to communicate and discuss the strategy of the game, or even to make friends. However, game forums also contain abusive and harassment speech, disturbing and threatening players. Therefore, it is necessary to automatically detect and remove cyberbullying comments to keep the game forum clean and friendly. We use the Cyberbullying dataset collected from World of Warcraft (WoW) and League of Legends (LoL) forums and train classification models to automatically detect whether a comment of a player is abusive or not. The result obtains 82.69% of macro F1-score for LoL forum and 83.86% of macro F1-score for WoW forum by the Toxic-BERT model on the Cyberbullying dataset.
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 21, 2021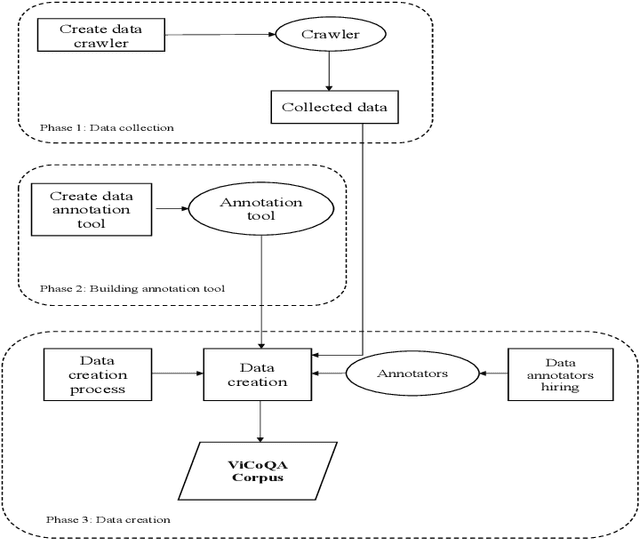
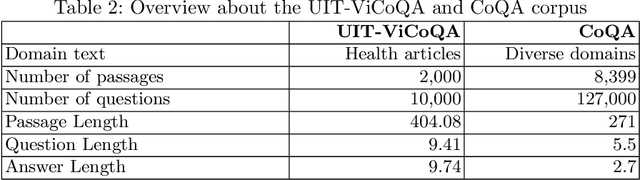
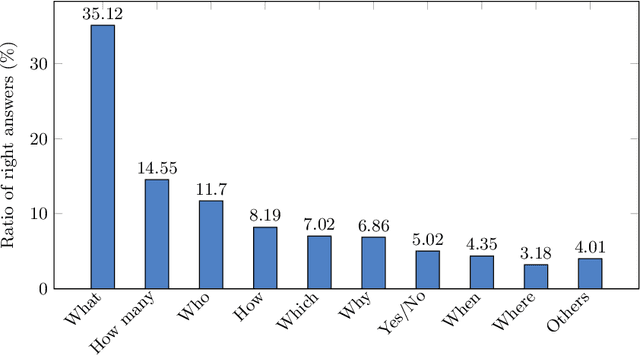

Machine reading comprehension (MRC) is a sub-field in natural language processing that aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.