 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Ensemble Collaborative Learning by using Knowledge-transfer Graph for Fine-grained Object Classification
Mar 27, 2021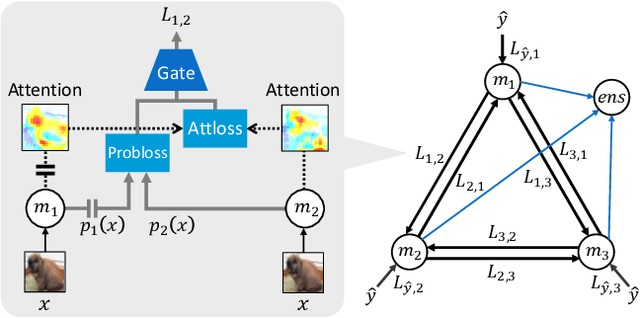
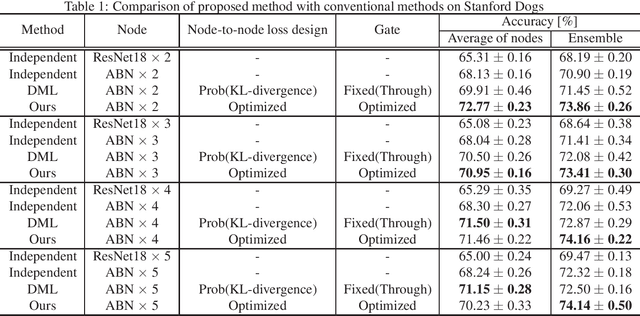
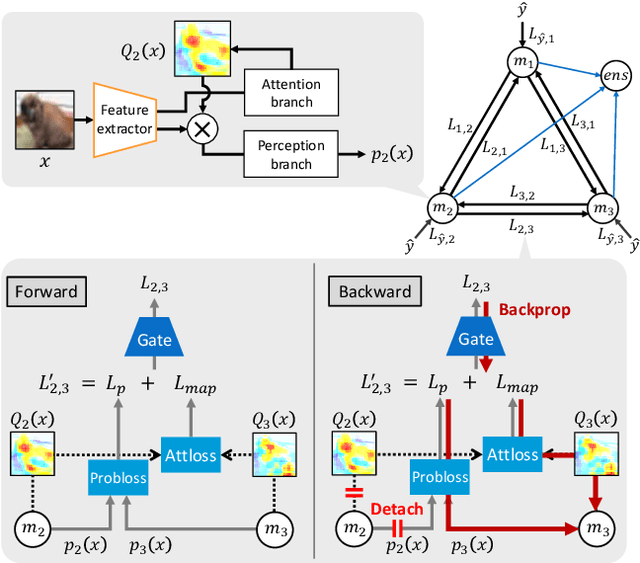
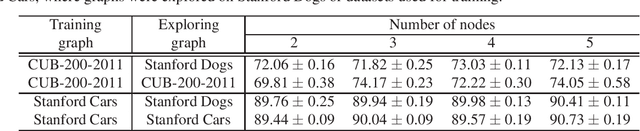
Mutual learning, in which multiple networks learn by sharing their knowledge, improves the performance of each network. However, the performance of ensembles of networks that have undergone mutual learning does not improve significantly from that of normal ensembles without mutual learning, even though the performance of each network has improved significantly. This may be due to the relationship between the knowledge in mutual learning and the individuality of the networks in the ensemble. In this study, we propose an ensemble method using knowledge transfer to improve the accuracy of ensembles by introducing a loss design that promotes diversity among networks in mutual learning. We use an attention map as knowledge, which represents the probability distribution and information in the middle layer of a network. There are many ways to combine networks and loss designs for knowledge transfer methods. Therefore, we use the automatic optimization of knowledge-transfer graphs to consider a variety of knowledge-transfer methods by graphically representing conventional mutual-learning and distillation methods and optimizing each element through hyperparameter search. The proposed method consists of a mechanism for constructing an ensemble in a knowledge-transfer graph, attention loss, and a loss design that promotes diversity among networks. We explore optimal ensemble learning by optimizing a knowledge-transfer graph to maximize ensemble accuracy. From exploration of graphs and evaluation experiments using the datasets of Stanford Dogs, Stanford Cars, and CUB-200-2011, we confirm that the proposed method is more accurate than a conventional ensemble method.
Knowledge Transfer Graph for Deep Collaborative Learning
Sep 10, 2019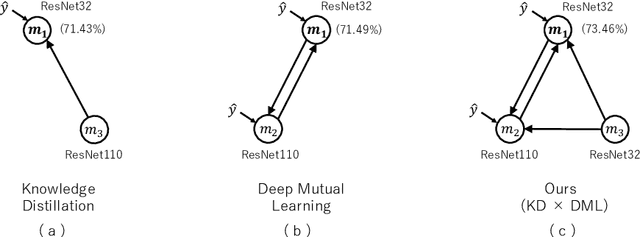
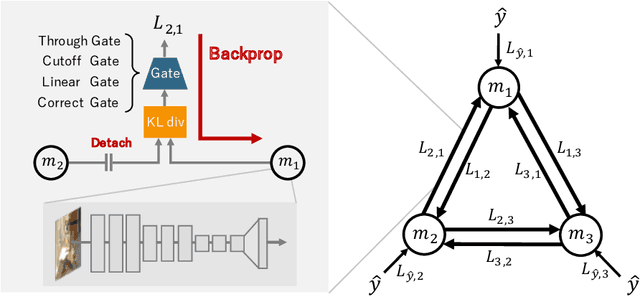
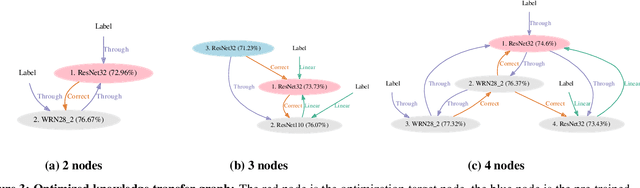
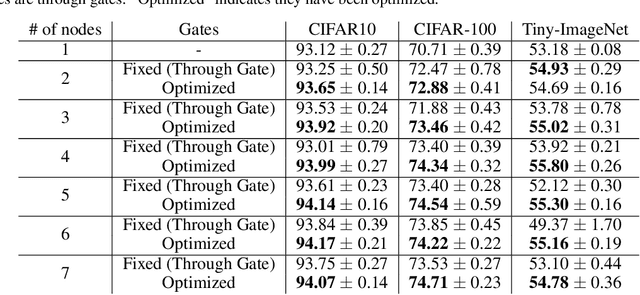
We propose Deep Collaborative Learning (DCL), which is a method that incorporates Knowledge Distillation and Deep Mutual Learning, and represents graph using a more generalized knowledge transfer method. DCL is represented by a directional graph where each model is represented by a node, and the propagation of knowledge from the source node to the target node is represented by edges. In DCL, a hyperparameter search can be used to search for an optimal knowledge transfer graph. We also propose four types of gate structure to control the propagation of gradients through the network for edges. When searching a knowledge transfer graph, optimization is performed to maximize the recognition rate of optimization target node using collaborative learning network types and gate types as hyperparameters. Using the CIFAR-100 dataset to search for an optimal knowledge transfer graph structure, we obtained a graph structure learning method that combines Knowledge Distillation with Deep Mutual Learning. Also, in experiments with the CIFAR-10, CIFAR-100 and Tiny-ImageNet datasets, we achieved a significant improvement in accuracy without increasing the network parameters beyond the vanilla model. We also show that an optimized graph can be transferred to a different dataset.