 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Visual Relocalization by Discovering Anchor Points
Nov 11, 2018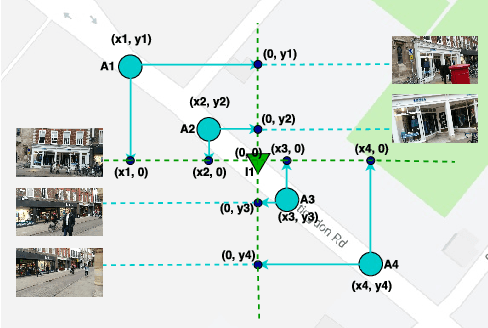
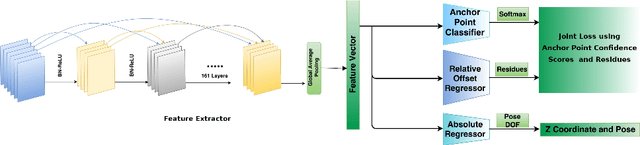
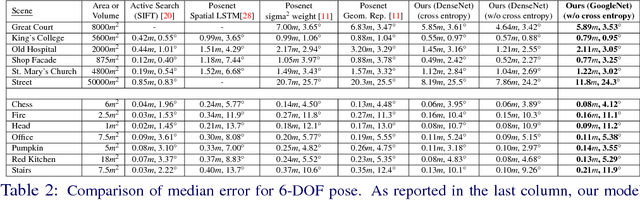
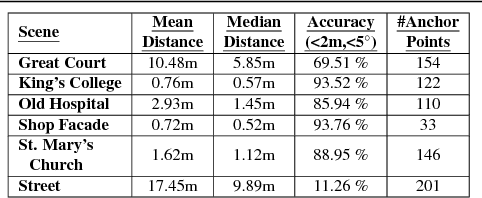
We address the visual relocalization problem of predicting the location and camera orientation or pose (6DOF) of the given input scene. We propose a method based on how humans determine their location using the visible landmarks. We define anchor points uniformly across the route map and propose a deep learning architecture which predicts the most relevant anchor point present in the scene as well as the relative offsets with respect to it. The relevant anchor point need not be the nearest anchor point to the ground truth location, as it might not be visible due to the pose. Hence we propose a multi task loss function, which discovers the relevant anchor point, without needing the ground truth for it. We validate the effectiveness of our approach by experimenting on CambridgeLandmarks (large scale outdoor scenes) as well as 7 Scenes (indoor scenes) using variousCNN feature extractors. Our method improves the median error in indoor as well as outdoor localization datasets compared to the previous best deep learning model known as PoseNet (with geometric re-projection loss) using the same feature extractor. We improve the median error in localization in the specific case of Street scene, by over 8m.
Class2Str: End to End Latent Hierarchy Learning
Aug 20, 2018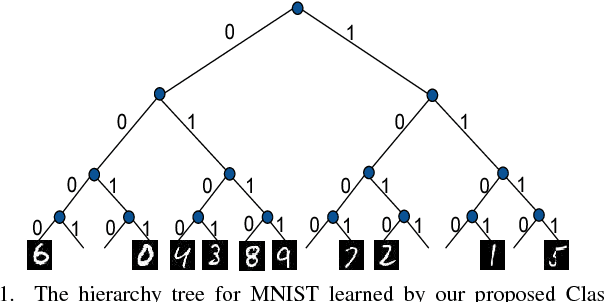
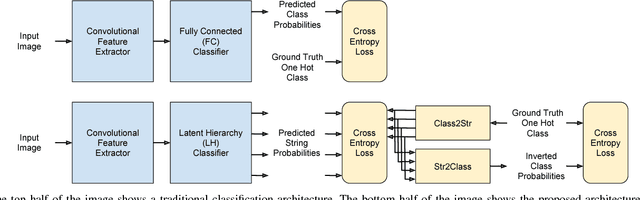
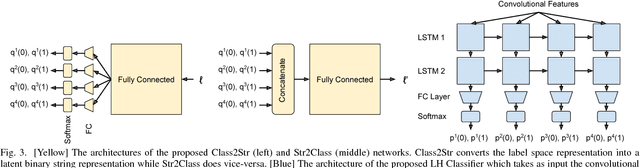
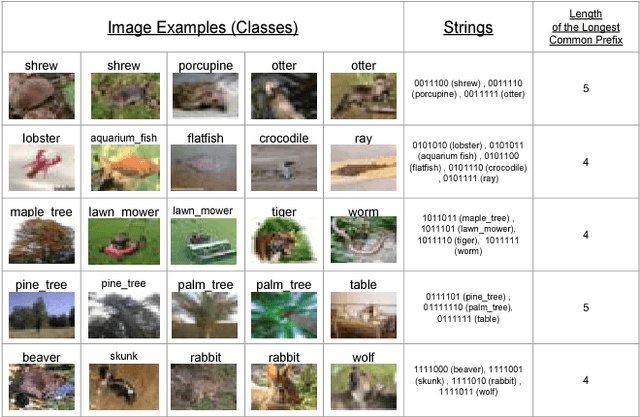
Deep neural networks for image classification typically consists of a convolutional feature extractor followed by a fully connected classifier network. The predicted and the ground truth labels are represented as one hot vectors. Such a representation assumes that all classes are equally dissimilar. However, classes have visual similarities and often form a hierarchy. Learning this latent hierarchy explicitly in the architecture could provide invaluable insights. We propose an alternate architecture to the classifier network called the Latent Hierarchy (LH) Classifier and an end to end learned Class2Str mapping which discovers a latent hierarchy of the classes. We show that for some of the best performing architectures on CIFAR and Imagenet datasets, the proposed replacement and training by LH classifier recovers the accuracy, with a fraction of the number of parameters in the classifier part. Compared to the previous work of HDCNN, which also learns a 2 level hierarchy, we are able to learn a hierarchy at an arbitrary number of levels as well as obtain an accuracy improvement on the Imagenet classification task over them. We also verify that many visually similar classes are grouped together, under the learnt hierarchy.