 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Open-set Segmentation with Synthetic Negative Data
Jan 19, 2023



Open-set segmentation is often conceived by complementing closed-set classification with anomaly detection. Existing dense anomaly detectors operate either through generative modelling of regular training data or by discriminating with respect to negative training data. These two approaches optimize different objectives and therefore exhibit different failure modes. Consequently, we propose the first dense hybrid anomaly score that fuses generative and discriminative cues. The proposed score can be efficiently implemented by upgrading any semantic segmentation model with translation-equivariant estimates of data likelihood and dataset posterior. Our design is a remarkably good fit for efficient inference on large images due to negligible computational overhead over the closed-set baseline. The resulting dense hybrid open-set models require negative training images that can be sampled either from an auxiliary negative dataset or from a jointly trained generative model. We evaluate our contributions on benchmarks for dense anomaly detection and open-set segmentation of traffic scenes. The experiments reveal strong open-set performance in spite of negligible computational overhead.
On advantages of Mask-level Recognition for Open-set Segmentation in the Wild
Jan 09, 2023Most dense recognition methods bring a separate decision in each particular pixel. This approach still delivers competitive performance in usual closed-set setups with small taxonomies. However, important applications in the wild typically require strong open-set performance and large numbers of known classes. We show that these two demanding setups greatly benefit from mask-level predictions, even in the case of non-finetuned baseline models. Moreover, we propose an alternative formulation of dense recognition uncertainty that effectively reduces false positive responses at semantic borders. The proposed formulation produces a further improvement over a very strong baseline and sets the new state of the art in dense anomaly detection without training on negative data. Our contributions also lead to a performance improvement in a recent open-set panoptic setup. In-depth experiments confirm that our approach succeeds due to implicit aggregation of pixel-level cues into mask-level predictions.
Weakly supervised training of universal visual concepts for multi-domain semantic segmentation
Dec 20, 2022Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on multiple datasets becomes a method of choice towards strong generalization in usual scenes and graceful performance degradation in edge cases. Unfortunately, different datasets often have incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. Furthermore, many datasets have overlapping labels. For instance, pickups are labeled as trucks in VIPER, cars in Vistas, and vans in ADE20k. We address this challenge by considering labels as unions of universal visual concepts. This allows seamless and principled learning on multi-domain dataset collections without requiring any relabeling effort. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
Dynamic loss balancing and sequential enhancement for road-safety assessment and traffic scene classification
Nov 08, 2022



Road-safety inspection is an indispensable instrument for reducing road-accident fatalities contributed to road infrastructure. Recent work formalizes road-safety assessment in terms of carefully selected risk factors that are also known as road-safety attributes. In current practice, these attributes are manually annotated in geo-referenced monocular video for each road segment. We propose to reduce dependency on tedious human labor by automating recognition with a two-stage neural architecture. The first stage predicts more than forty road-safety attributes by observing a local spatio-temporal context. Our design leverages an efficient convolutional pipeline, which benefits from pre-training on semantic segmentation of street scenes. The second stage enhances predictions through sequential integration across a larger temporal window. Our design leverages per-attribute instances of a lightweight bidirectional LSTM architecture. Both stages alleviate extreme class imbalance by incorporating a multi-task variant of recall-based dynamic loss weighting. We perform experiments on the iRAP-BH dataset, which involves fully labeled geo-referenced video along 2,300 km of public roads in Bosnia and Herzegovina. We also validate our approach by comparing it with the related work on two road-scene classification datasets from the literature: Honda Scenes and FM3m. Experimental evaluation confirms the value of our contributions on all three datasets.
Automatic universal taxonomies for multi-domain semantic segmentation
Jul 18, 2022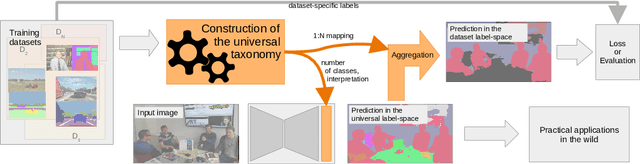
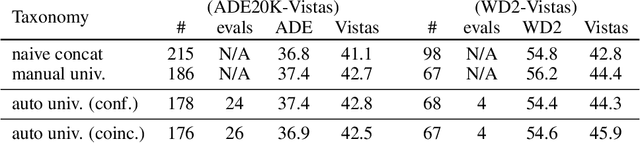
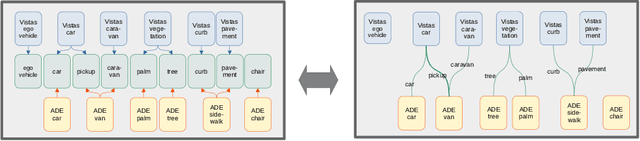

Training semantic segmentation models on multiple datasets has sparked a lot of recent interest in the computer vision community. This interest has been motivated by expensive annotations and a desire to achieve proficiency across multiple visual domains. However, established datasets have mutually incompatible labels which disrupt principled inference in the wild. We address this issue by automatic construction of universal taxonomies through iterative dataset integration. Our method detects subset-superset relationships between dataset-specific labels, and supports learning of sub-class logits by treating super-classes as partial labels. We present experiments on collections of standard datasets and demonstrate competitive generalization performance with respect to previous work.
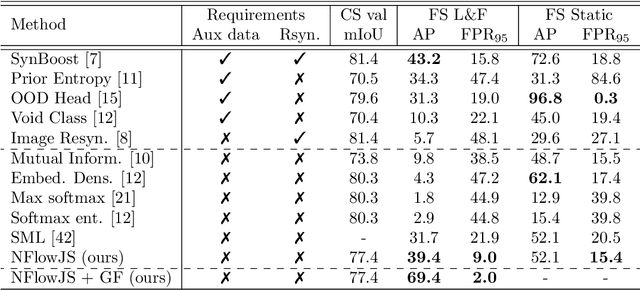
DenseHybrid: Hybrid Anomaly Detection for Dense Open-set Recognition
Jul 06, 2022
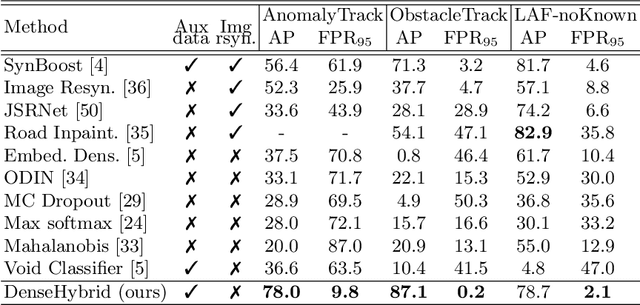
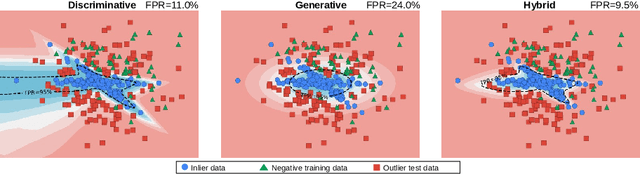
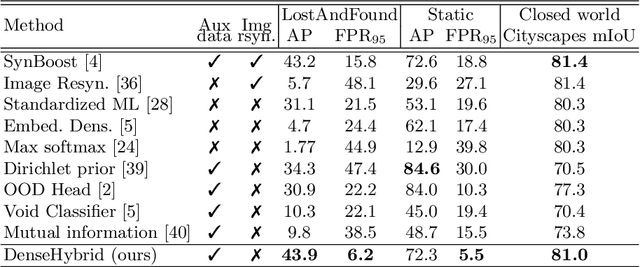
Anomaly detection can be conceived either through generative modelling of regular training data or by discriminating with respect to negative training data. These two approaches exhibit different failure modes. Consequently, hybrid algorithms present an attractive research goal. Unfortunately, dense anomaly detection requires translational equivariance and very large input resolutions. These requirements disqualify all previous hybrid approaches to the best of our knowledge. We therefore design a novel hybrid algorithm based on reinterpreting discriminative logits as a logarithm of the unnormalized joint distribution $\hat{p}(\mathbf{x}, \mathbf{y})$. Our model builds on a shared convolutional representation from which we recover three dense predictions: i) the closed-set class posterior $P(\mathbf{y}|\mathbf{x})$, ii) the dataset posterior $P(d_{in}|\mathbf{x})$, iii) unnormalized data likelihood $\hat{p}(\mathbf{x})$. The latter two predictions are trained both on the standard training data and on a generic negative dataset. We blend these two predictions into a hybrid anomaly score which allows dense open-set recognition on large natural images. We carefully design a custom loss for the data likelihood in order to avoid backpropagation through the untractable normalizing constant $Z(\theta)$. Experiments evaluate our contributions on standard dense anomaly detection benchmarks as well as in terms of open-mIoU - a novel metric for dense open-set performance. Our submissions achieve state-of-the-art performance despite neglectable computational overhead over the standard semantic segmentation baseline.
Panoptic SwiftNet: Pyramidal Fusion for Real-time Panoptic Segmentation
Mar 15, 2022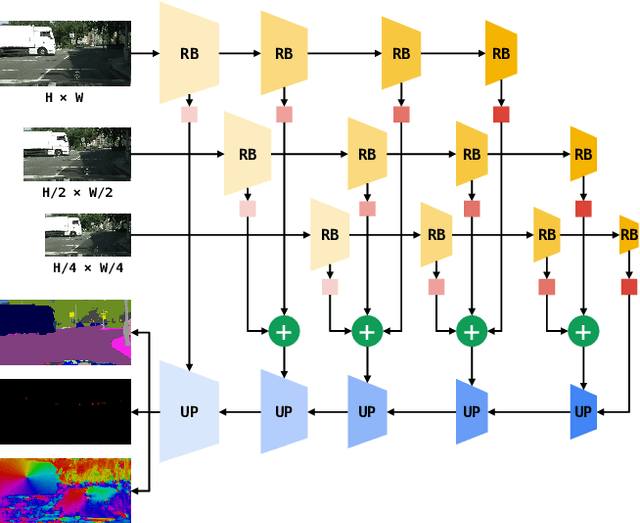
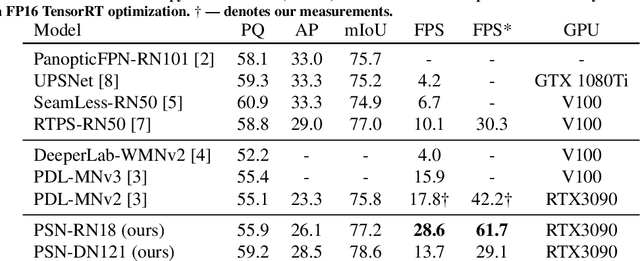

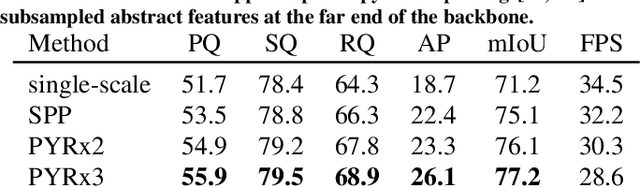
Dense panoptic prediction is a key ingredient in many existing applications such as autonomous driving, automated warehouses or agri-robotics. However, most of these applications leverage the recovered dense semantics as an input to visual closed-loop control. Hence, practical deployments require real-time inference over large input resolutions on embedded hardware. These requirements call for computationally efficient approaches which deliver high accuracy with limited computational resources. We propose to achieve this goal by trading-off backbone capacity for multi-scale feature extraction. In comparison with contemporaneous approaches to panoptic segmentation, the main novelties of our method are scale-equivariant feature extraction and cross-scale upsampling through pyramidal fusion. Our best model achieves 55.9% PQ on Cityscapes val at 60 FPS on full resolution 2MPx images and RTX3090 with FP16 Tensor RT optimization.
Dense anomaly detection by robust learning on synthetic negative data
Dec 31, 2021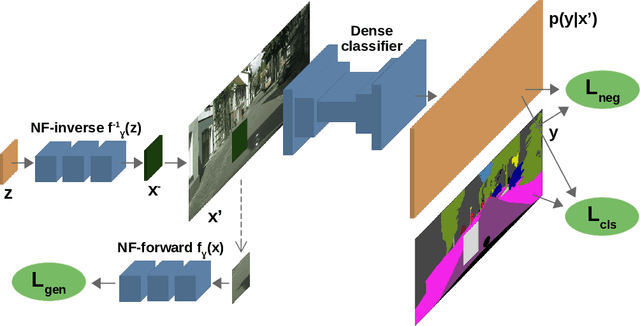

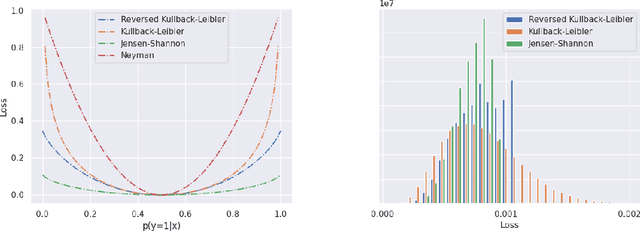
Standard machine learning is unable to accommodate inputs which do not belong to the training distribution. The resulting models often give rise to confident incorrect predictions which may lead to devastating consequences. This problem is especially demanding in the context of dense prediction since input images may be partially anomalous. Previous work has addressed dense anomaly detection by discriminative training on mixed-content images. We extend this approach with synthetic negative patches which simultaneously achieve high inlier likelihood and uniform discriminative prediction. We generate synthetic negatives with normalizing flows due to their outstanding distribution coverage and capability to generate samples at different resolutions. We also propose to detect anomalies according to a principled information-theoretic criterion which can be consistently applied through training and inference. The resulting models set the new state of the art on standard benchmarks and datasets in spite of minimal computational overhead and refraining from auxiliary negative data.
Multi-domain semantic segmentation with overlapping labels
Aug 25, 2021

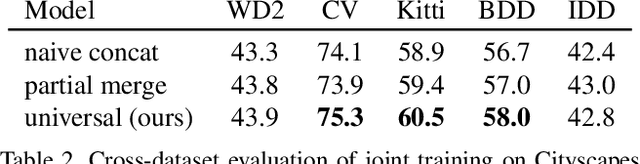

Deep supervised models have an unprecedented capacity to absorb large quantities of training data. Hence, training on many datasets becomes a method of choice towards graceful degradation in unusual scenes. Unfortunately, different datasets often use incompatible labels. For instance, the Cityscapes road class subsumes all driving surfaces, while Vistas defines separate classes for road markings, manholes etc. We address this challenge by proposing a principled method for seamless learning on datasets with overlapping classes based on partial labels and probabilistic loss. Our method achieves competitive within-dataset and cross-dataset generalization, as well as ability to learn visual concepts which are not separately labeled in any of the training datasets. Experiments reveal competitive or state-of-the-art performance on two multi-domain dataset collections and on the WildDash 2 benchmark.
A baseline for semi-supervised learning of efficient semantic segmentation models
Jun 15, 2021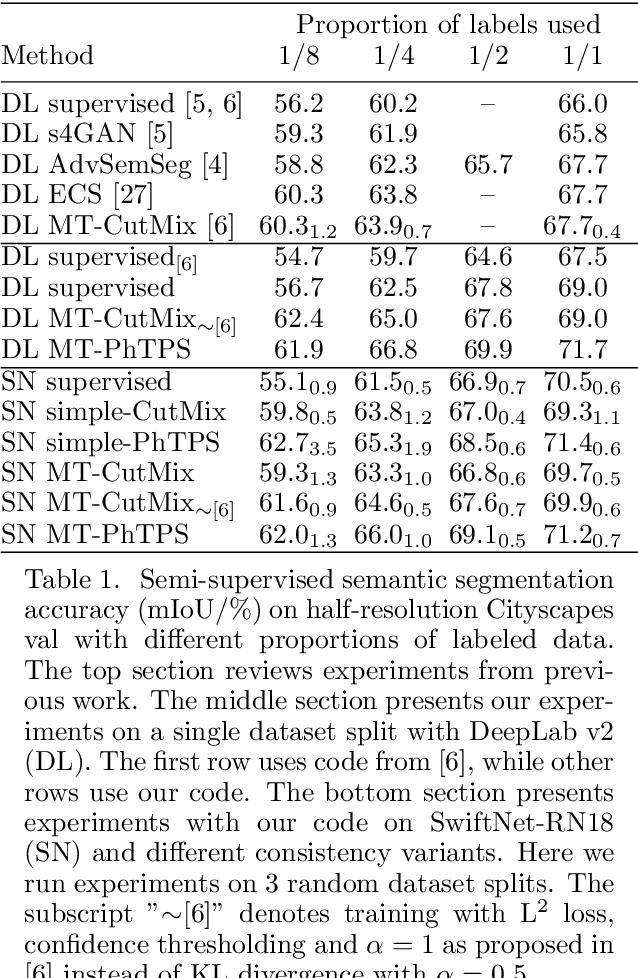

Semi-supervised learning is especially interesting in the dense prediction context due to high cost of pixel-level ground truth. Unfortunately, most such approaches are evaluated on outdated architectures which hamper research due to very slow training and high requirements on GPU RAM. We address this concern by presenting a simple and effective baseline which works very well both on standard and efficient architectures. Our baseline is based on one-way consistency and non-linear geometric and photometric perturbations. We show advantage of perturbing only the student branch and present a plausible explanation of such behaviour. Experiments on Cityscapes and CIFAR-10 demonstrate competitive performance with respect to prior work.