 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Co-speech Gestures in-the-wild
Mar 28, 2025



Co-speech gestures play a vital role in non-verbal communication. In this paper, we introduce a new framework for co-speech gesture understanding in the wild. Specifically, we propose three new tasks and benchmarks to evaluate a model's capability to comprehend gesture-text-speech associations: (i) gesture-based retrieval, (ii) gestured word spotting, and (iii) active speaker detection using gestures. We present a new approach that learns a tri-modal speech-text-video-gesture representation to solve these tasks. By leveraging a combination of global phrase contrastive loss and local gesture-word coupling loss, we demonstrate that a strong gesture representation can be learned in a weakly supervised manner from videos in the wild. Our learned representations outperform previous methods, including large vision-language models (VLMs), across all three tasks. Further analysis reveals that speech and text modalities capture distinct gesture-related signals, underscoring the advantages of learning a shared tri-modal embedding space. The dataset, model, and code are available at: https://www.robots.ox.ac.uk/~vgg/research/jegal
GestSync: Determining who is speaking without a talking head
Oct 08, 2023In this paper we introduce a new synchronisation task, Gesture-Sync: determining if a person's gestures are correlated with their speech or not. In comparison to Lip-Sync, Gesture-Sync is far more challenging as there is a far looser relationship between the voice and body movement than there is between voice and lip motion. We introduce a dual-encoder model for this task, and compare a number of input representations including RGB frames, keypoint images, and keypoint vectors, assessing their performance and advantages. We show that the model can be trained using self-supervised learning alone, and evaluate its performance on the LRS3 dataset. Finally, we demonstrate applications of Gesture-Sync for audio-visual synchronisation, and in determining who is the speaker in a crowd, without seeing their faces. The code, datasets and pre-trained models can be found at: \url{https://www.robots.ox.ac.uk/~vgg/research/gestsync}.
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Sep 01, 2022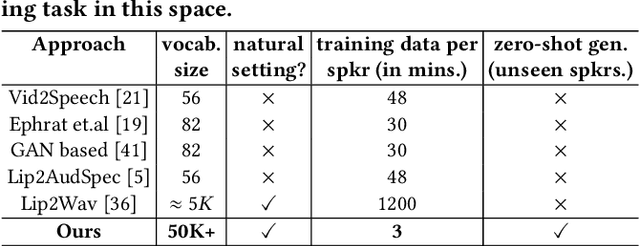
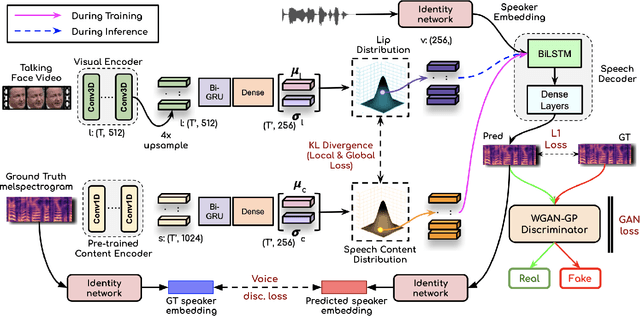
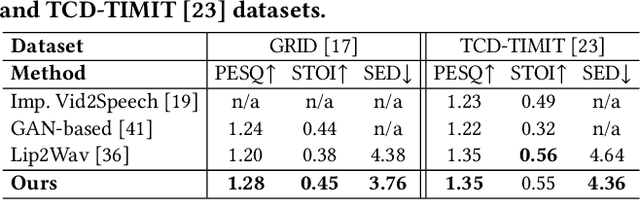
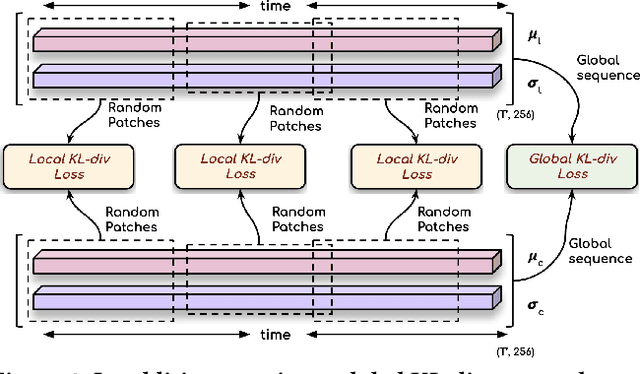
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works, our method (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings. The task presents a host of challenges, with the key one being that many features of the desired target speech, like voice, pitch and linguistic content, cannot be entirely inferred from the silent face video. In order to handle these stochastic variations, we propose a new VAE-GAN architecture that learns to associate the lip and speech sequences amidst the variations. With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person. Extensive experiments on multiple datasets show that we outperform all baselines by a large margin. Further, our network can be fine-tuned on videos of specific identities to achieve a performance comparable to single-speaker models that are trained on $4\times$ more data. We conduct numerous ablation studies to analyze the effect of different modules of our architecture. We also provide a demo video that demonstrates several qualitative results along with the code and trained models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/lip-to-speech-synthesis}}
Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
Aug 17, 2022

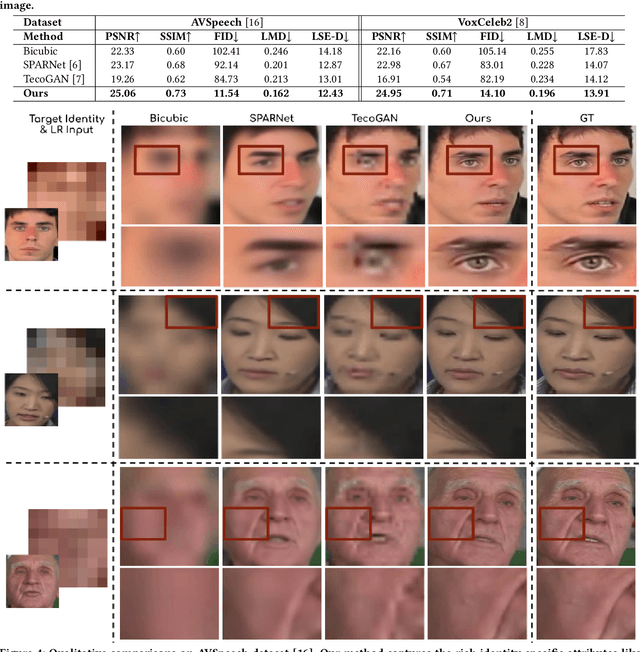
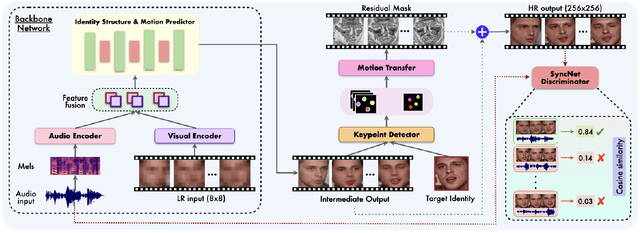
In this paper, we explore an interesting question of what can be obtained from an $8\times8$ pixel video sequence. Surprisingly, it turns out to be quite a lot. We show that when we process this $8\times8$ video with the right set of audio and image priors, we can obtain a full-length, $256\times256$ video. We achieve this $32\times$ scaling of an extremely low-resolution input using our novel audio-visual upsampling network. The audio prior helps to recover the elemental facial details and precise lip shapes and a single high-resolution target identity image prior provides us with rich appearance details. Our approach is an end-to-end multi-stage framework. The first stage produces a coarse intermediate output video that can be then used to animate single target identity image and generate realistic, accurate and high-quality outputs. Our approach is simple and performs exceedingly well (an $8\times$ improvement in FID score) compared to previous super-resolution methods. We also extend our model to talking-face video compression, and show that we obtain a $3.5\times$ improvement in terms of bits/pixel over the previous state-of-the-art. The results from our network are thoroughly analyzed through extensive ablation experiments (in the paper and supplementary material). We also provide the demo video along with code and models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/talking-face-video-upsampling}.
Towards Automatic Speech to Sign Language Generation
Jun 24, 2021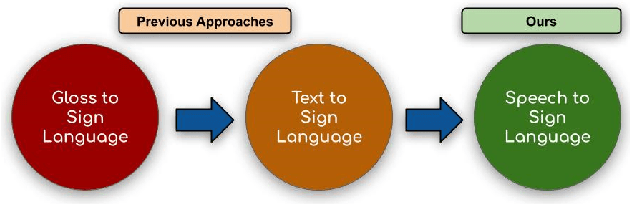
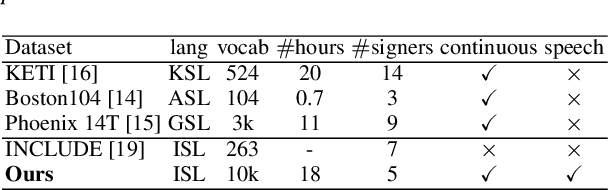

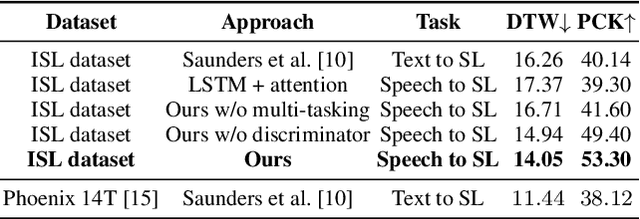
We aim to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss. Therefore, we eliminate the need of using text as input and design techniques that work for more natural, continuous, freely uttered speech covering an extensive vocabulary. Since the current datasets are inadequate for generating sign language directly from speech, we collect and release the first Indian sign language dataset comprising speech-level annotations, text transcripts, and the corresponding sign-language videos. Next, we propose a multi-tasking transformer network trained to generate signer's poses from speech segments. With speech-to-text as an auxiliary task and an additional cross-modal discriminator, our model learns to generate continuous sign pose sequences in an end-to-end manner. Extensive experiments and comparisons with other baselines demonstrate the effectiveness of our approach. We also conduct additional ablation studies to analyze the effect of different modules of our network. A demo video containing several results is attached to the supplementary material.
Visual Speech Enhancement Without A Real Visual Stream
Dec 20, 2020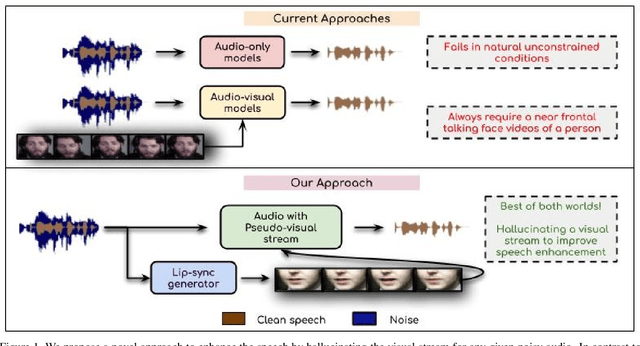

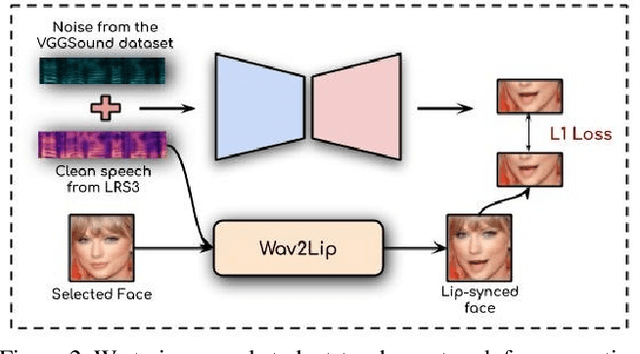
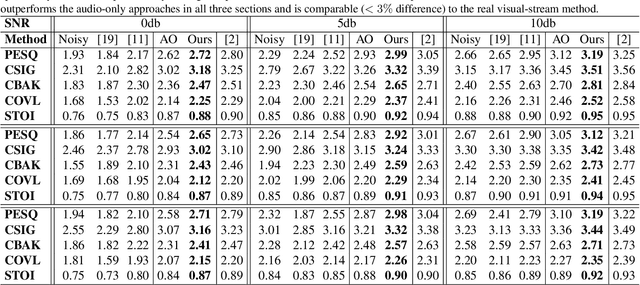
In this work, we re-think the task of speech enhancement in unconstrained real-world environments. Current state-of-the-art methods use only the audio stream and are limited in their performance in a wide range of real-world noises. Recent works using lip movements as additional cues improve the quality of generated speech over "audio-only" methods. But, these methods cannot be used for several applications where the visual stream is unreliable or completely absent. We propose a new paradigm for speech enhancement by exploiting recent breakthroughs in speech-driven lip synthesis. Using one such model as a teacher network, we train a robust student network to produce accurate lip movements that mask away the noise, thus acting as a "visual noise filter". The intelligibility of the speech enhanced by our pseudo-lip approach is comparable (< 3% difference) to the case of using real lips. This implies that we can exploit the advantages of using lip movements even in the absence of a real video stream. We rigorously evaluate our model using quantitative metrics as well as human evaluations. Additional ablation studies and a demo video on our website containing qualitative comparisons and results clearly illustrate the effectiveness of our approach. We provide a demo video which clearly illustrates the effectiveness of our proposed approach on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/visual-speech-enhancement-without-a-real-visual-stream}. The code and models are also released for future research: \url{https://github.com/Sindhu-Hegde/pseudo-visual-speech-denoising}.